
Welcome
Software Engineering in Industry 4.0 Ecosystems
Course: COMP 233
Time: 12:30 PM - 01:25 PM on Monday, Wednesday, Friday
Location: Chambers Technology Center 113 (CTC 113)
Module 1
Introduction to Software Engineering in Industry 4.0
Motivation: the challenges of building software that touches the physical world.
Today's Agenda
- What is Industry 4.0?
- Key challenges
- Software engineering principles
The Core Challenge
Industry 4.0 is not about writing more code. It is about engineering systems that interact with nature, machines, and data.
What You Will Learn to Handle
- Complex systems, not single programs
- Continuous data, not one-time input
- Deployment and updates, not just coding
Why This Is Hard
- Physical signals are noisy and imperfect
- Systems must run continuously
- Failures can cause real-world harm
Industry 4.0 as a Loop
Sense → process → decide → act (repeated continuously)
Where Problems Appear
- At the sensor (measurement errors)
- In the network (latency, outages)
- In the software (bugs, wrong logic)

Software Engineering
A discipline for building systems that last.
Legal Validation, User Validation, Safety Validation
- Engineering discipline, not just programming
- Correctness, structure, lifecycle
- Built to evolve over years
In liability cases, lawyers typically try to show a specific product issue contributed to the accident, such as a manufacturing defect, design defect, software malfunction, inadequate testing, failure to warn, or misleading marketing about the system’s capabilities.
What “Correct” Means Here
- Correct results
- Correct timing
- Correct behavior under failures
Programming vs. Software Engineering
| Programming | Software Engineering |
|---|---|
| Make it work | Make it work reliably over time |
| Single developer focus | Team focus, handoffs, documentation |
| Short-term code | Long-term system maintenance |
| Local correctness | System-level correctness + safety |
Engineering
Constraints and trade-offs are unavoidable.
Engineering Reality
- Constraints matter
- Trade-offs are explicit
- Failures have consequences

Common Constraints
- Limited power and compute on devices
- Unreliable networks
- Strict timing requirements

From Code to Systems
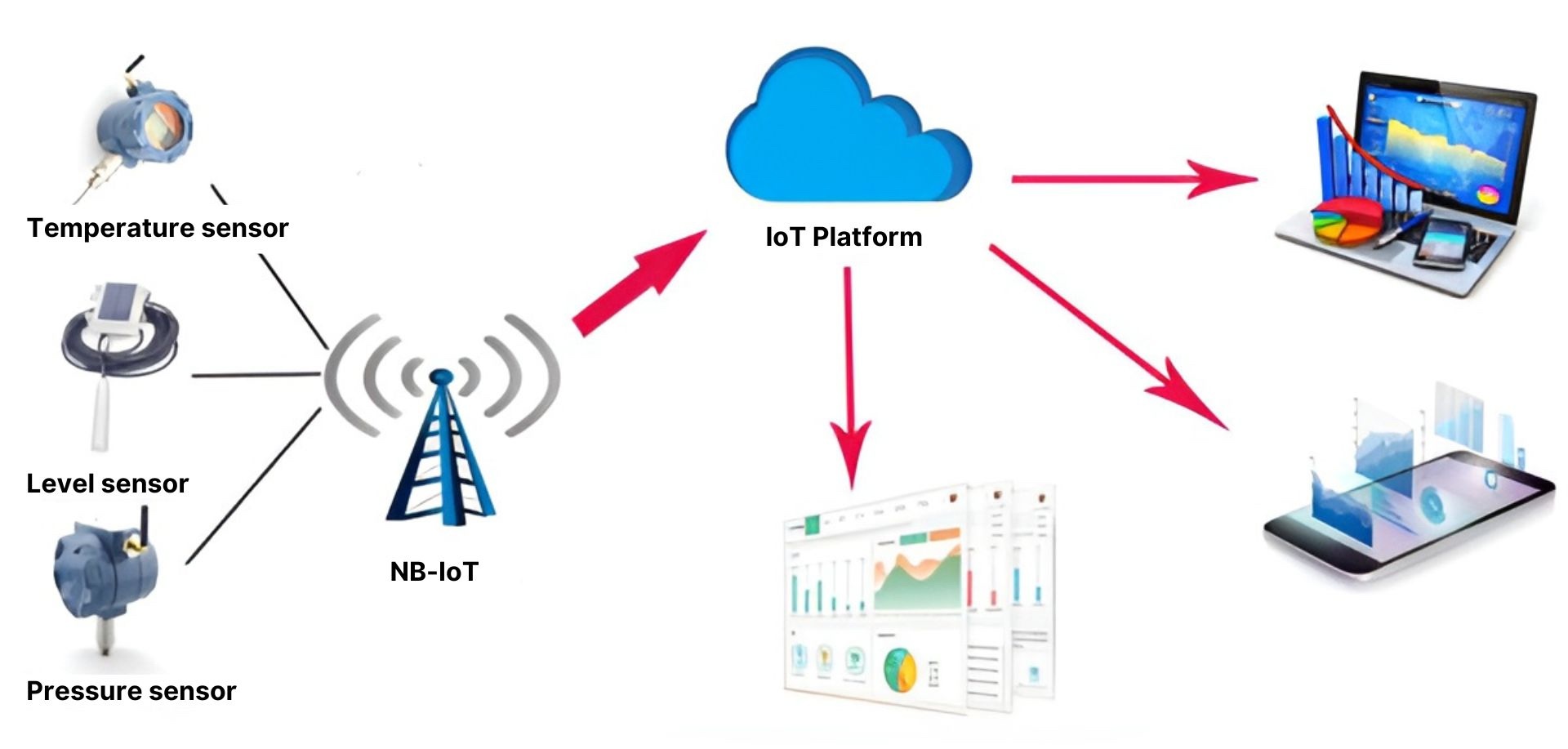
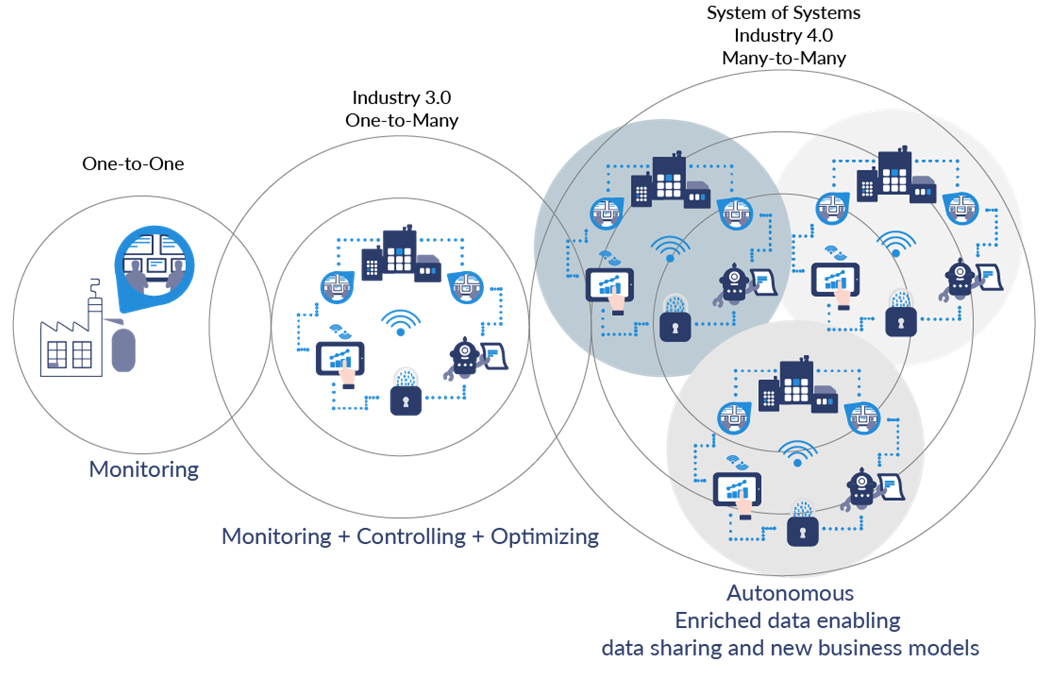
What Is Industry 4.0?
A connected environment for software.
Live traffic data
- Digitally connected physical systems
- Automation + data + intelligence
- Continuous sensing and control
What Makes It “Ecosystem”
- Many independent components
- Shared dependencies
- Constant coordination

Industry 4.0 Core Pipeline
Sensors
- The system starts with measurement
- Capture real-world signals
- Temperature, motion, pressure, location
- Bridge nature and software

Sensor Data Is Messy
- Noise and drift over time
- Missing readings
- Calibration differences
Sensor Examples
| Sensor | Measures | Why It Matters |
|---|---|---|
| Temperature | Heat | Safety, quality control |
| Accelerometer | Motion / vibration | Fault detection, wear |
| GPS | Location | Tracking assets, logistics |
| Pressure | Force | Industrial control, monitoring |
Nature Meets Software
Data
- Industry 4.0 produces continuous streams
- Produced continuously
- High volume and velocity
- Requires storage and processing

Data Needs Context
- What device produced it?
- When was it measured?
- What units and conditions?
{
"deviceId": "plant-hydration-042",
"deviceType": "soil_moisture_sensor",
"location": {
"plantId": "tomato-17"
},
"measurement": {
"type": "soil_moisture",
"value": 23.4,
"unit": "percent"
},
"timestamp": "2026-01-12T09:14:32Z",
"conditions": {
"temperatureC": 21.8,
}
}From Data to Information
Data Challenges
| Challenge | What It Means | Impact |
|---|---|---|
| Noise | Measurements are imperfect | False alarms, wrong decisions |
| Missing data | Sensor downtime | Gaps in monitoring |
| Scale | Too much data to store/process | Cost + performance issues |
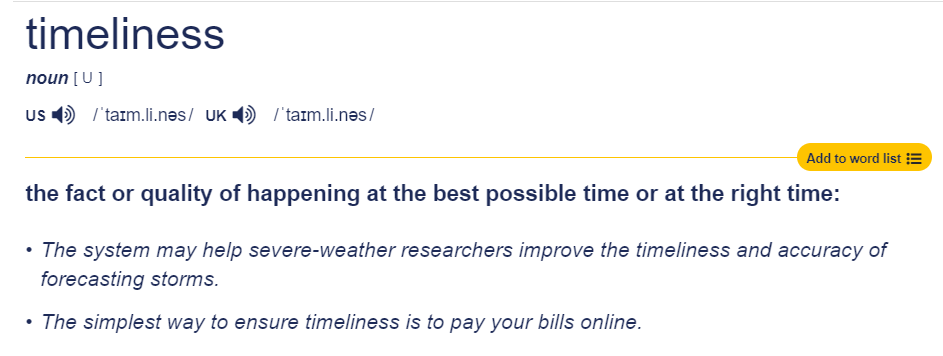
Real-Time Systems
Timing is part of correctness.
- Responses must be timely
- Late answers can be failures
- Time is a correctness constraint
Latency Sources
- Sensor sampling rate
- Network delay
- Backend processing time
Real-Time Flow
Real-Time: What Can Go Wrong?
| Problem | Example | Result |
|---|---|---|
| High latency | Slow network | Delayed response |
| Overload | Too many events | Dropped messages |
| Wrong timing | Out-of-order events | Incorrect decisions |
Integration
Complexity comes from connections.
- Devices must talk to services
- Systems must share data
- Failures propagate across layers

Integration Needs Standards
- Stable interfaces
- Consistent data formats
- Clear ownership of services
Integration Layers
Integration Failure Modes
| Failure | Cause | Effect |
|---|---|---|
| Incompatible interfaces | API mismatch | System breaks at runtime |
| Inconsistent data | Different formats | Wrong results |
| Single point of failure | Central dependency | Outage spreads |
Security
Connectivity increases attack surface.
- More devices = more entry points
- Data must be protected
- Safety can depend on security
Security Is a System Problem
- Device security
- Network security
- Backend and data security
Security: What Must Be Protected?
| Asset | Risk | Example |
|---|---|---|
| Devices | Tampering | Compromised sensor |
| Data | Leakage | Exposed telemetry |
| Control | Hijacking | Unauthorized commands |
Reliability
Systems must keep working under stress.
- Hardware fails
- Networks degrade
- Software must recover
Reliability Techniques
- Health checks
- Retries and backoff
- Fallback behavior
Reliability Principle
Design for faults, not perfect conditions.
Maintenance
Most work happens after version 1.
- Requirements change
- Systems need updates
- Teams change over time
Why Maintenance Is Hard
- Legacy decisions remain
- Downtime is expensive
- Changes can break integration

What Changes vs. What Lasts
| Changes Often | Lasts Longer |
|---|---|
| Tools and frameworks | Data and system behavior |
| Hardware generations | Interfaces and requirements |
| Deployment platforms | Engineering fundamentals |
Software Engineering in Industry 4.0
Course Goal
- Understand the ecosystem
- Learn to manage complexity
- Build systems
- Scale and make many mistake
- Apply theory directly in project
Key Takeaway
Industry 4.0 systems require engineering discipline: correct behavior, real-time performance, secure integration, and long-term maintenance.
Where do we start?
Today's Agenda
- What Roles are in Industry 4.0?
- What Tools are in Industry 4.0?
- Setup GitHub
Today's Agenda
- Present Project Requirements
- Setup Project Team Structure
- Setup Project Team Process
- Homework 1 and Lab 1
Lab 1.1
Join Slack
[ ] Open Slack link
[ ] Click "Join"
[ ] Confirm participation
Communication Hub
┌─────────┐
│ Slack │
└───┬─────┘
│ team channels
▼
┌─────────┐
│ Teams │
└─────────┘
Lab 1.2
Create Team Channel
Naming convention
team-architecture
team-embedded
team-quality
...
[ ] Create channel
[ ] Join channel
[ ] Confirm created
Slack Workspace
┌───────────────────────┐
│ #team-architecture │
│ #team-embedded │
│ #team-quality │
└───────────────────────┘
Lab 1.3
Meet In Person + Post Intro
[ ] Meet team members
[ ] Introduce yourself
[ ] Share your contribution
[ ] Post summary in Slack
Intro Template
"Hi, I'm __.
I will contribute by __.
My focus is __."
Lab 1.4
GitHub Backlog Labels
[ ] Review backlog
[ ] Add team label to issues
team-architecture
team-embedded
team-quality
...
GitHub Project
┌──────────────┐
│ Issues │
└─────┬────────┘
│ add labels
▼
┌──────────────┐
│ Team Work │
└──────────────┘
Lab 1.5
Create Issues + Demo Slide Task
Per team:
[ ] Create ≥ 5 issues
- PO: user stories
- Tester: testing tasks
- All: stories + tasks
Per member:
[ ] Assign yourself ≥ 1 task
One team task:
Title: Sprint 1 Demo Slide [Team]
Labels: sprint-demo + team-*
Upload 1 slide to the ticket
Deliverables
┌─────────────────────────────┐
│ 5+ issues created │
│ Labels applied │
│ Tasks assigned │
│ Sprint 1 demo slide ticket │
└─────────────────────────────┘
Homework 1.1
Industry 4.0 Challenges
Read:
"The Essence of Industry 4.0"
Task:
[ ] Identify 12 challenges (Section V)
[ ] Sort from biggest → smallest
challenge for the
plant water project
[ ] Write 1 sentence per challenge
explaining your reasoning
Analysis Focus
┌───────────────────────┐
│ Context: Water Plant │
│ Constraints │
│ Scale │
│ Integration │
└───────────────────────┘
Homework 1.2
Software Paradigms
Read:
"Software Engineering Tutorial"
Pages: 8–14
Task:
[ ] Identify development paradigms
[ ] Sort by suitability
for our project
[ ] 1 sentence explanation
per paradigm
Decision Criteria
┌───────────────────────┐
│ Change frequency │
│ System complexity │
│ Hardware dependency │
│ Risk │
└───────────────────────┘
Homework 1.3
Key Terms (Definitions)
Explain in 1–2 sentences:
[ ] Internet of Things (IoT)
[ ] Cyber-Physical Systems (CPS)
[ ] Machine-to-Machine (M2M)
[ ] Smart Factory
[ ] Fourth Industrial Revolution
Goal
┌───────────────────────┐
│ Clear terminology │
│ Correct scope │
│ No buzzwords │
└───────────────────────┘
Homework 1.4
Traditional Paradigms vs IoT
Task:
[ ] Identify 2 challenges
traditional software
paradigms face with:
- IoT
- CPS
- M2M
[ ] Explain each challenge
in a brief paragraph
Hint
┌──────────────────────────┐
│ Assumptions break down │
│ Timing matters │
│ Hardware is involved │
└──────────────────────────┘
Homework 1.5
What We Are Evaluating
[ ] Reading comprehension
[ ] Ability to rank & justify
[ ] Conceptual clarity
[ ] Connection to project
[ ] Structured reasoning
Mindset
┌───────────────────────┐
│ Think like an engineer│
│ Not just a reader │
│ Not memorization │
└───────────────────────┘
Module 2
Requirements Engineering for Industry 4.0 Applications
Defining what systems must do before deciding how to build them.
Software Engineering Starts with Requirements

Requirement
The light sensor system should measure ambient light levels and report for monitoring.
Requirement
The light sensor system should provide light level measurement and a dashboard with status updated every hour.
Requirement
Purpose: IoT Light Sensor system to monitor ambient light levels and present system status.
- Measure ambient light levels using a connected light sensor
- Display current readings and system status on a dashboard
Translating Textual/Visual Requirements into Epics
What Are Epics?
Definition: Epics represent high-level requirements that group related features or functionalities.What Are Epics?
Epics are broad categories of work that can be broken down into smaller, actionable tasks or user stories
Epic Principle
An epic describes what should be done, not how it will be implemented.
What an Epic Should Include
- Title: A concise, descriptive name for the epic
- Description: A brief overview of the functionality or goal the epic addresses
- Goals: High-level objectives or outcomes that the epic aims to achieve.
- Related User Stories: A list of smaller tasks or features that contribute to the epic
Epic Summary Examples:
- Implement IoT Light Sensor Monitoring
- Provide Dashboard with Sensor Status

IoT Light Sensor: Epic Overview
- Title: IoT Light Sensor
- Description: Monitor ambient light levels and expose system status
- Goals: Provide visibility into light conditions and sensor health
- Key Features:
- Light level measurement
- Dashboard with status
- Phase: Requirements
- Author: Feature Owner
- Due Date: TBD
- Status: Draft
- Effort Estimation: TBD
Adding User Story Requirements into an Epic
What Are User Stories?
Definition: User stories represent small, actionable tasks that describe specific functionality or features from the user’s perspective.What Are User Stories?
User stories are specific features or tasks that can be completed within a short time frame, often within a sprint
What a User Story Should Include
- Title: A short, clear description of the user story
- Description: A brief explanation of the user need and the goal
- Acceptance Criteria: Specific conditions that must be met for the story to be considered complete
Acceptance Criteria
- Definition: Conditions that must be met for a light sensor feature to be considered complete
- Purpose: To ensure the light sensor meets stated requirements and reports its status correctly
- Example: "As a user, I should see the current light level and sensor status on the dashboard."
- Components:
- Clear and testable conditions
- Defines the scope of the light sensor functionality
- Supports validation and verification
User Story Template
As a [user role],
I want to [desired action],
Because [reason or benefit]
User Stories for Light Sensor
- As a user, I want to view the current light level, Because I want to understand the ambient lighting conditions
- As a user, I want to see the sensor status on a dashboard, Because I want to know whether the sensor is operating correctly
- As a user, I want to access basic historical light readings, Because I want to observe changes over time
User Stories Focus on What
User stories describe what the user needs or expects from the system, not how the system is implemented.
Acceptance Criteria: Light Sensor
-
User Story 1: View current light level
- The dashboard displays the current light value
- The value updates when new sensor data is available
- The reading is clearly labeled with appropriate units
-
User Story 2: View sensor status on dashboard
- The sensor status is visible on the dashboard
- The status indicates whether the sensor is active or inactive
- Status information is easy to distinguish from readings
-
User Story 3: View historical light readings
- Past light readings are accessible from the dashboard
- Data is presented in a readable format
- The time range of displayed data is clearly indicated
Epic
User Story + AC
Tasks
Adding Implementation Task Requirements into User Stories
Implementation Tasks
Implementation tasks are specific, actionable steps required to complete a user story or
feature.
They focus on how the system is built and include:
- Breaking down complex features into manageable pieces of work
- Focusing on concrete technical decisions
- Ensuring each task is clear, achievable, and aligned with the project’s goals
- Technology choices, such as:
- Database: MongoDB or PostgreSQL
- Backend language: Python or JavaScript
- Operating system: Linux or Windows
- Mobile platform: Android or iOS
- Deployment: Local setup or Cloud environment
Product Requirements Backlog
- Epics and user stories defining what the system should provide
- Acceptance criteria used to validate user stories
- Technical tasks required for implementation
- Continuously reviewed and refined items
Exercise: Create the epics shown on the right directly in the GitHub backlog.
- Epic 1: IoT Light Sensor Monitoring
- Epic 2: Dashboard with Sensor Status
Translating Requirements into Implementation
Requirements
Epic
User Story
Task
Implementation
Code
Issue
Ticket
Git Commit Message
git commit -m "Implements #3 - Light Sensor Monitoring"
Types of Requirements
- UI Requirements: Define user interaction and design
- Architecture Requirements: Specify system structure and components
- Database Requirements: Outline data storage and access
- Functional Requirements: Define core features and functionality
- Non-Functional Requirements: Define performance and scalability
- Security Requirements: Protect against unauthorized access
- Performance Requirements: Specify responsiveness and load capacity
- Compliance Requirements: Ensure legal and regulatory adherence
Requirement Priority
- Must Have: Critical features needed for system functionality
- Should Have: Important but non-essential features that can be deferred.
- Nice to Have: Desirable features that can be added if resources allow
Effort Estimation: T-Shirt Size
- Small (S): Low complexity or effort, typically takes a short time
- Medium (M): Moderate complexity, takes a moderate amount of time
- Large (L): High complexity, requires significant effort and time
- Extra Large (XL): Very high complexity, requires substantial time and resources
Effort Estimation: Fibonacci Numbers
- 1: Very low effort, simple task that requires little time
- 2: Low effort, simple task with a bit more time required
- 3: Moderate effort, task that requires a reasonable amount of time
- 5: High effort, more complex task with significant time and resources
- 8: Very high effort, complex task requiring considerable time and resources
- 13: Extremely high effort, very complex task with substantial time and resources
- Requirement Gathering
- Requirement Tracebility Matrix
- Dependency Matrix
- Use Case
- Lab 1 and Homework 1
Requirements Gathering
What is needed for the software product?
Requirement Types
- Requirement → High-level need
- Epic → Larger body of work
- User Story → Specific deliverable
- Verification/Validation Ticket → Ensure correctness
- Task → Actionable work item
Getting User Requirements from the Client
- Ask open-ended questions to understand needs
- Use tools like surveys or interviews
- Clarify unclear points to avoid assumptions
- Document the conversation for future reference
Example: CPC/IoT User Requirements
- Req 001: The system shall support remote monitoring of IoT devices via a secure web interface
- Req 002: The IoT devices shall transmit data to the cloud at intervals of 10 seconds
- Req 003: The system shall notify users of critical device status changes within 5 seconds
- Req 004: The IoT platform shall allow for firmware updates over-the-air (OTA)
Process Requirements
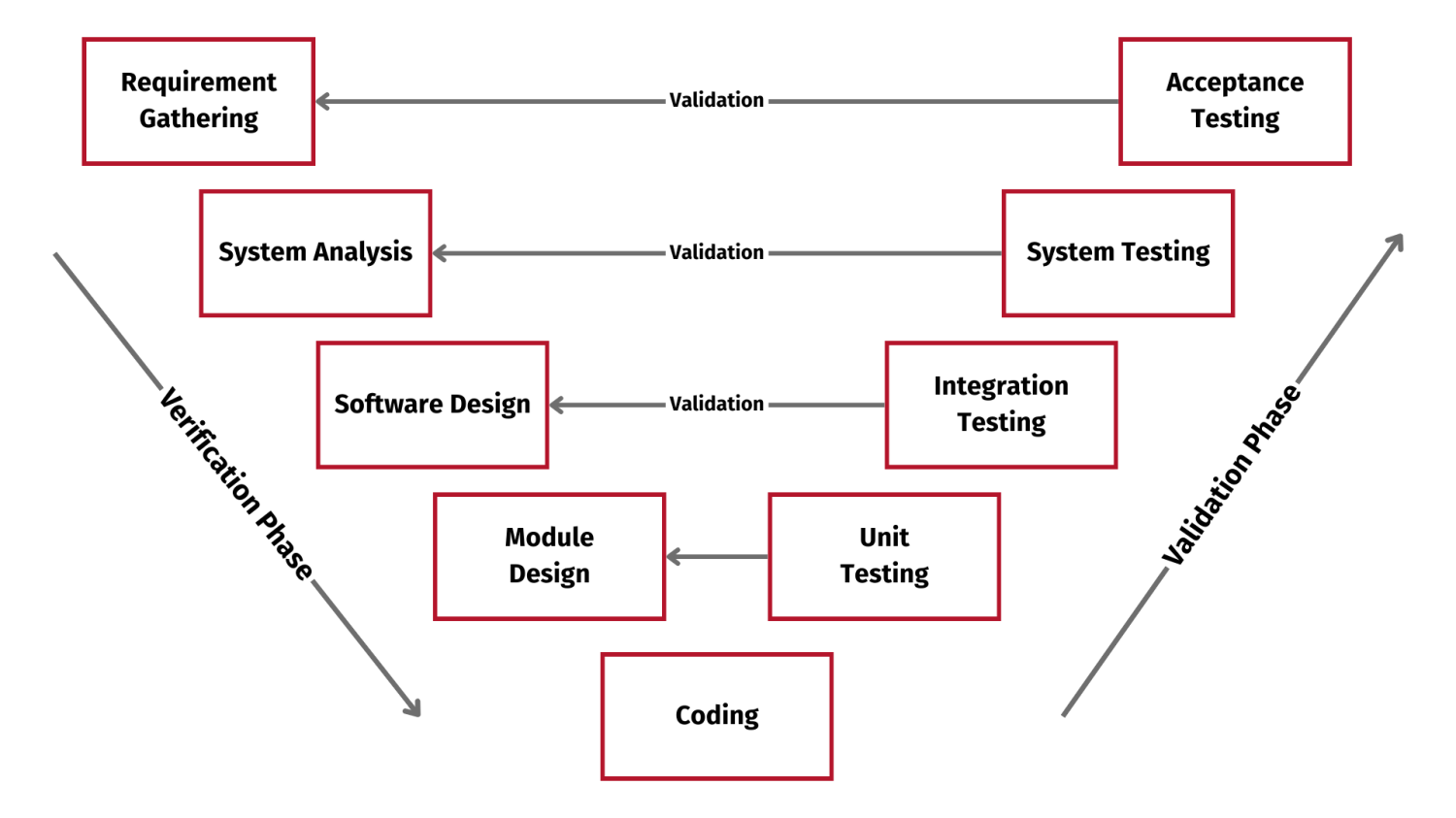
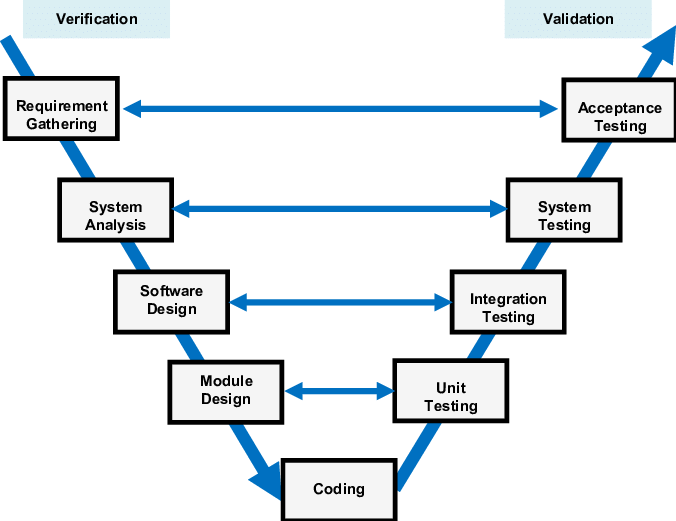
Verification
Ensures the product is built as per specifications. ("Are we building the product right?")
Verification in the V-Model
Purpose: Acts as a quality gate to ensure readiness for the next stage
Verification at Each Stage:
- Requirements Analysis → System Design: Verify requirements are clear, complete, and testable
- System Design → Architectural Design: Verify high-level design meets specified requirements
- Architectural Design → Module Design: Verify components align with design goals
- Module Design → Implementation: Verify module designs are correct and implementable
Validation
Confirms the product meets user needs. ("Are we building the right product?")
Horizontal and Vertical Traceability
Test Tickets: Verification
- Ticket ID: #VT-001 Task: Review the system architecture to ensure alignment with requirements
- Ticket ID: #VT-002 Task: Run unit tests to ensure each module meets functionality specifications
- Ticket ID: #VT-003 Task: Perform integration testing to verify interfaces between modules
Test Ticket: Validation
- Ticket ID: #VD-001 | Task: Conduct acceptance testing to verify user needs are met
- Ticket ID: #VD-002 | Task: Perform usability testing for user satisfaction
- Ticket ID: #VD-003 | Task: Validate real-world data processing accuracy
Project
- Requirement: The system must notify user to water plants based on soil moisture levels
- Verification: Ensure sensors capture soil moisture data accurately
- Validation: Confirm plants are watered when soil moisture is below the threshold
Requirement Tracebility Matrix
Requirements Traceability Matrix
| Requirement ID | Requirement | Verification Ticket | Validation Ticket | Verification Method | Validation Method |
|---|---|---|---|---|---|
| REQ-001 | System must measure soil moisture levels | #VT-001 | #VD-001 | Unit Test: Sensor data accuracy | Functional Test: Moisture detection in real soil |
| REQ-002 | System must water plants when moisture is below threshold | #VT-002 | #VD-002 | Integration Test: Sensor-to-actuator response | Acceptance Test: Ensure plants are watered correctly |
| REQ-003 | System must notify users of low water levels in the tank | #VT-003 | #VD-003 | System Test: Notification accuracy | User Test: Validate notifications received |
| REQ-004 | System must allow users to set custom thresholds | #VT-004 | #VD-004 | Interface Test: Threshold input functionality | Usability Test: Confirm thresholds match user input |
Requirement Dependency Matrix
| Requirement | REQ-001 | REQ-002 | REQ-003 | REQ-004 |
|---|---|---|---|---|
| REQ-001 | - | X | X | - |
| REQ-002 | X | - | - | X |
| REQ-003 | X | ? | - | - |
| REQ-004 | - | X | X | - |
| Requirement | REQ-001 | REQ-002 | REQ-003 | REQ-004 |
|---|---|---|---|---|
| REQ-001: Measure soil moisture | - | X | X | - |
| REQ-002: Water plants when moisture is low | X | - | - | X |
| REQ-003: Notify user when water levels are low | X | - | - | - |
| REQ-004: User can set watering thresholds | - | X | X | - |
Logistics Team for IoT Sensor Setup
Requirements for the IoT System
| Requirement | Description |
|---|---|
| REQ-001 | Purchase moisture sensors to detect soil moisture levels |
| REQ-002 | Order Raspberry Pi devices for controlling the system and running the software |
| REQ-003 | Develop system plan for sensor and device integration |
| REQ-004 | Ensure all components meet quality standards for outdoor usage |
| REQ-005 | Test sensors and Raspberry Pi setup for functionality and connectivity |
Horizontal Tickets
- Ticket #LT-001: Purchase Sensors
- Task: Identify, source, and order soil moisture sensors
- Dependencies: None
- Due Date:
- Assignee: Logistics Team
- Ticket #LT-002: Order Raspberry Pi
- Task: Source Raspberry Pi models suitable for integration
- Dependencies: LT-001 (sensors)
- Due Date:
- Assignee: Logistics Team
Horizontal Tickets
- Ticket #LT-003: Develop System Plan
- Task: Plan the integration of sensors and Raspberry Pi into the watering system
- Dependencies: LT-001, LT-002
- Due Date:
- Assignee: Logistics Team
Requirements Dependency Matrix
| Requirement | REQ-001 | REQ-002 | REQ-003 | REQ-004 | REQ-005 |
|---|---|---|---|---|---|
| REQ-001 | - | - | - | - | - |
| REQ-002 | X | - | - | X | - |
| REQ-003 | X | - | - | - | X |
| REQ-004 | - | X | X | - | - |
| REQ-005 | - | - | X | - | - |
Requirements Dependency Matrix
Project: Automated Plant Watering System
| Requirement | REQ-001 | REQ-002 | REQ-003 | REQ-004 | REQ-005 |
|---|---|---|---|---|---|
| REQ-001: Measure soil moisture | - | X | X | - | - |
| REQ-002: Water plants when moisture is low | X | - | - | X | - |
| REQ-003: Notify user when water levels are low | X | - | - | - | X |
| REQ-004: User can set watering thresholds | - | X | X | - | - |
| REQ-005: Test sensors and Raspberry Pi | - | - | X | - | - |
Requirement Traceability Matrix
| Requirement Ticket | LT Task | Verification Tickets | Validation Tickets |
|---|---|---|---|
| REQ-001: Purchase moisture sensors | LT-001: Purchase Sensors | VT-001: Verify sensor functionality | VT-002: Validate sensor accuracy in real-world conditions |
| REQ-002: Order Raspberry Pi devices | LT-002: Order Raspberry Pi | VT-003: Verify compatibility with sensors | VT-004: Validate Raspberry Pi performance under load |
| REQ-003: Develop system integration plan | LT-003: Develop System Plan | VT-005: Verify integration of sensors and Raspberry Pi | VT-006: Validate system flow against project requirements |
| REQ-004: Ensure quality standards for components | LT-004: Ensure Quality Standards | VT-007: Verify component durability and reliability | VT-008: Validate quality compliance with industry standards |
| REQ-005: Test sensors and Raspberry Pi | LT-005: Test Sensors and Raspberry Pi | VT-009: Verify sensors' response to moisture levels | VT-010: Validate system functionality after testing |
Lab 1: Issue Creation and Review
- Create at least 5 issues (only client team can/edit create requirements and epics)
- Client team create one empty dependency and tracebility matrix
- Review all existing issues to ensure they are up-to-date and relevant, comment if not
- Review all existing issues and update the dependency and tracebility matrix
- Focus on creating user stories based on the requirements and epics
- Focus on creating tracebility tickets based on your tickets
- Use Slack for communication to collaborate and ask questions: Join Slack Workspace
- If you are not blocked, start with the implementation (eg logistics)
- Always keep your tickets up-to-date
- Due next Friday, Jan 31
Question?
What is the primary purpose of verification in software development?
- To ensure the product meets user needs
- To verify that the product is built according to specifications
- To test the product in real-world scenarios
- To evaluate the product's market fit
What does a Requirements Traceability Matrix (RTM) help with?
- To track the schedule of the project
- To track how requirements relate to other project artifacts
- To assign tasks to team members
- To calculate project costs
Which of the following best describes an Epic?
- A small unit of work that can be completed in a few days
- A large, high-level unit of work that encompasses several user stories
- A detailed test case
- A requirement defined by the client
What is the main purpose of verification and validation tickets?
- To assign specific tasks to developers
- To ensure that the system meets technical specifications and user needs
- To verify market demand for the system
- To track project expenses
What is the role of tasks in project management?
- They represent high-level goals
- They break down user stories into actionable work items
- They track customer feedback
- They estimate project timelines
- Requirement and Standards
- Requirement and Automation
- Status Project
- Lab 1 and Homework 1
Requirement and Standards
Requirement and Standard Diagrams
Standard UML: Component Diagram
- Represents system components and their relationships
- Shows high-level architecture
- Useful for modular design and dependencies
+----------------+ +-----------------+
| Component | ------ | Component 2 |
+----------------+ +-----------------+
Standard UML: Entity Relationship Diagram
- Shows entities and their relationships
- Highlights data structure and constraints
- Commonly used in database design
+------------+ +------------+
| Entity | ------- | Entity 2 |
+------------+ +------------+
PlantUML: Component Diagram
@startuml
[Component 1] --> [Component 2]
@enduml
PlantUML: Entity Relationship Diagram
@startuml
entity "Entity" {
+ID: int
+Name: string
}
entity "Entity2" {
+ID: int
+Details: string
}
"Entity" -- "Entity2"
@enduml
PlantUML Editor
Open PlantUML EditorPlantUML Language Reference Guide
Requirement and Standard Communication
Standard Communication Using Slack
- Use public channels for specific topics
- Keep messages clear and concise
- Use threads for organized conversations
- Set availability status
Public Channel Naming Conventions
- [team]-[topic] format
- [logistics]-wifi-access
Special Use Case Channels
- #all-plant-watering-system for important updates
Slack Communication Standards
- Use @mentions carefully
- Set Slack reminders
- Pin important messages
- Use threads to keep channels organized
Example Public Channels for Teams
- [team-design-ui]-sprint
- [team-architecture]-tech-stack
- [team-embedded]-sensor-data
- [team-frontend]-status
- [team-backend]-api
Adding Team to Profile Name
- Include your team name in your Slack profile
- Format: [name] ([team])
- Example: Dr. Berhe (Quality)
- Helps others quickly identify your role and team
- Improves cross-team communication and collaboration
Slack vs GitHub
- Slack is for **quick communication** and collaboration
- **GitHub** is the **single source of truth** for code, issues, and tasks
- Use Slack for Reviewions, but always refer to GitHub for the most accurate data
- Ensure your code, issues, and progress are tracked directly in GitHub
Slack Task
- Please create one team channel per team
- Please add your team to your handle
Requirement and Automation
GitHub Automation Overview
- Automate repetitive tasks like issue creation, CI/CD pipelines, etc
- Improve productivity and consistency
- Use GitHub Actions to automate workflows
Automating Issue Creation
- Automate issue creation based on events like weekly schedules
- Use workflows to trigger issue creation
- Example: Weekly sprint demo issues
Setting Up GitHub Actions
- Create a workflow file: .github/workflows/automation.yml
- Define the event triggers (e.g., schedule, push)
- Configure actions to automate tasks like issue creation
name: Create Weekly Issue
on:
schedule:
- cron: '0 0 * * 5' # Every Friday
jobs:
create-issue:
...
Slack Integration with GitHub Automation
- Receive GitHub notifications directly in Slack
- Use GitHub's Slack integration to get updates on pull requests, issues, etc
- Automate Slack messages for new issues, commits, and deployments
- Set up GitHub Actions to send custom messages to specific Slack channels
Benefits of GitHub Automation
- Consistency: Automate repetitive tasks
- Efficiency: Free up time for more important tasks
- Collaboration: Keep everyone aligned with automated workflows
- Automation is a Type of Standardization
Automation Task (1/2)
- Please review which tasks can be automated in your team
Automation Task (2/2)
- Please create one task for each automation recommendation
- Requirement and Standards ✓
- Requirement and Automation ✓
- Status Project
- Lab 1 and Homework 1
Status Project
Project Team Task
- Please introduce your team
- Assign roles and responsibilities
- Review team goals and deliverables
- Review team structure and technologies to use
- Ensure all team members have access to necessary tools
- Plan first sprint demo tasks for next Friday
Project Goal: Product Backlog MVP 1
- Product feature teams require feature tickets
- Each feature ticket requires a user story
- Each user story is decomposed into tasks
- Estimate tasks, user stories, and features (due March 6)
- Plan Sprint #1 by selecting user stories
- Scrum team assignment: 5 + 2 (rotating Product Owner / Scrum Master)
What Is a Feature?
- A feature is a cohesive unit of user-visible functionality
- It delivers measurable value to the user or business
- A feature is larger than a user story
- A feature is small enough to be planned and estimated
- A feature is implemented through one or more user stories
- ⚠️Limited dependency on other features
| Level | Purpose |
|---|---|
| Feature | User value |
| User Story | User need |
| Task | Implementation |
Think in Features
- Identify one features you see in this system
- Focus on user-visible functionality
- Ask: what value does each feature deliver?
- Consider how many user stories each feature might require
- Be prepared to justify your choices
- Link to Backlog

Project Goal: Product Backlog MVP 1
- Product feature teams require feature tickets ✓
- Each feature ticket requires a user story
- Each user story is decomposed into tasks
- Estimate tasks, user stories, and features (due March 6)
- Plan Sprint #1 by selecting user stories
- Scrum team assignment: 5 + 2 (rotating Product Owner / Scrum Master)
What Is a User Story?
- A user story describes functionality from the user’s perspective
- It focuses on value, not implementation
- A user story is smaller than a feature
- User stories are the primary unit of sprint planning
- A story should be understandable by all stakeholders
| Artifact | Focus |
|---|---|
| Feature | Value |
| User Story | Behavior |
| Task | Work |
User Story Format (Best Practice)
- User stories follow a simple, consistent template
- The template emphasizes who, what, and why
- This keeps discussion focused on user value
- Technical details belong in tasks, not the story
| Element | Example |
|---|---|
| As a | registered user |
| I want | to reset my password |
| So that | I can regain access |
Good User Stories (INVEST)
- User stories should follow the INVEST principles
- They support flexibility and collaboration
- Poor stories create risk during sprint execution
- Well-written stories reduce rework and ambiguity
| Letter | Meaning |
|---|---|
| I | Independent |
| N | Negotiable |
| V | Valuable |
| E | Estimable |
| S | Small |
| T | Testable |
User Stories and Acceptance Criteria
- Acceptance criteria define when a story is done
- They remove ambiguity before development starts
- They guide implementation and testing
- A story without acceptance criteria is not ready
| Story | Criteria |
|---|---|
| Password reset | Email link sent |
| Password reset | Link expires |
When Is a User Story Ready?
- The story is clearly written and understood
- Acceptance criteria are defined
- The story can be estimated by the team
- Dependencies are identified ⚠️
- The story fits within a single sprint
| Status | Meaning |
|---|---|
| Ready | Can enter sprint |
| Not Ready | Needs refinement |
Think in User Stories
- Identify two user stories based on this system
- Write each story from the user’s perspective
- Focus on behavior, not implementation
- State the value clearly using “so that …”
- Be prepared to explain why each story matters
- Link to Backlog
Project Goal: Product Backlog MVP 1
- Product feature teams require feature tickets ✓
- Each feature ticket requires a user story
- Each user story is decomposed into tasks
- Estimate tasks, user stories, and features (due March 6)
- Plan Sprint #1 by selecting user stories
- Scrum team assignment: 5 + 2 (rotating Product Owner / Scrum Master)
What Is a Task?
- A task represents a concrete unit of implementation work
- Tasks describe how work is done, not why
- Tasks belong to a single user story
- Tasks are owned by the development team
- Tasks are tracked during the sprint
| Level | Focus |
|---|---|
| User Story | Behavior |
| Task | Work |
Breaking a User Story into Tasks
- Tasks are derived after the user story is agreed upon
- Each task should be small and actionable
- Tasks often reflect design, implementation, and testing
- Multiple tasks can be worked on in parallel
- Tasks make progress visible during the sprint
| Task Type | Example |
|---|---|
| Design | Define API |
| Build | Implement logic |
| Test | Write tests |
Good Tasks (Best Practice)
- A task can be completed within a short time frame
- A task has a clear definition of done
- A task can be estimated with confidence
- A task has minimal dependency on other tasks ⚠️
- Tasks are updated daily during the sprint
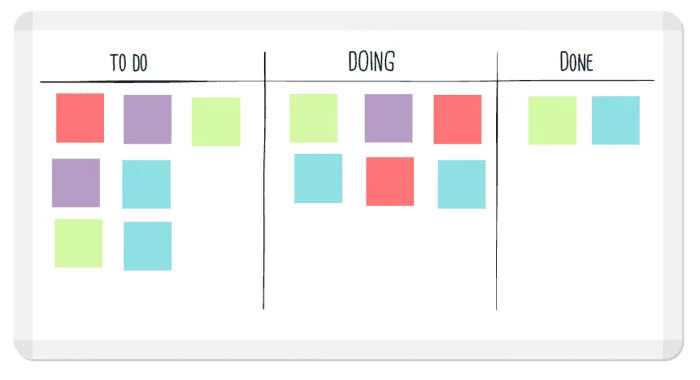
| State | Meaning |
|---|---|
| To Do | Not started |
| In Progress | Being worked on |
| Done | Completed |
Project Goal: Product Backlog MVP 1
- Product feature teams require feature tickets ✓
- Each feature ticket requires a user story
- Each user story is decomposed into tasks
- Estimate tasks, user stories, and features (due March 6)
- Plan Sprint #1 by selecting user stories
- Scrum team assignment: 5 + 2 (rotating Product Owner / Scrum Master)
Complexity Estimation (Fibonacci)
- Complexity measures relative difficulty, not time
- It accounts for uncertainty, risk, and unknowns
- Complexity is estimated using story points
- The Fibonacci sequence is commonly used
- Estimation is done collaboratively by the team
| Points | Meaning |
|---|---|
| 1 | Very simple |
| 3 | Simple |
| 5 | Moderate |
| 8 | Complex |
| 13+ | High risk ⚠️ |
Why Fibonacci?
- Precision decreases as complexity increases
- Fibonacci numbers force meaningful choices
- Large gaps reflect growing uncertainty
- Encourages discussion instead of false accuracy
- Large stories signal the need for splitting
| Estimate | Signal |
|---|---|
| 1–3 | Well understood |
| 5–8 | Some uncertainty |
| 13+ | Too large → refine |
Effort Estimation (Man Days)
- Effort measures time required to do the work
- Expressed in hours or man days
- Used mainly for short-term planning
- Effort depends on team capacity and availability
- Effort is derived after complexity is understood ⚠️
| Measure | Used For |
|---|---|
| Story Points | Complexity |
| Man Days | Scheduling |
| Velocity | Forecasting |
Effort Estimation (Man Days)
- Effort measures time required to do the work
- Expressed in hours or man days
- Used mainly for short-term planning
- Effort depends on team capacity and availability
- Effort is derived after complexity is understood ⚠️
| Measure | Used For |
|---|---|
| Story Points | Complexity |
| Man Days | Scheduling |
| Velocity | Forecasting |
- Product feature teams require feature tickets ✓
- Each feature ticket requires a user story
- Each user story is decomposed into tasks
- Estimate tasks, user stories, and features (due March 6)
- Plan Sprint #1 by selecting user stories
- Scrum team assignment: 5 + 2 (rotating Product Owner / Scrum Master)
Modeling a 1-Week Sprint with GitHub Milestones
- A sprint is modeled as a GitHub milestone
- The milestone represents a fixed 1-week time box
- User stories and tasks are assigned to the milestone
- Progress is tracked through issue completion
- The sprint ends after one week, regardless of status ⚠️
| Milestone | Represents |
|---|---|
| Sprint 1 | 1-week sprint |
| Issues | User stories / tasks |
| Progress | % completed |
- Product feature teams require feature tickets ✓
- Each feature ticket requires a user story
- Each user story is decomposed into tasks
- Estimate tasks, user stories, and features (due March 6)
- Plan Sprint #1 by selecting user stories
- Scrum team assignment: 5 + 2 (rotating Product Owner / Scrum Master)
Assigning Team Members to Tickets
- Tickets are assigned to a responsible team member
- Assignment indicates ownership, not exclusivity
- One primary owner keeps accountability clear
- Work can still be reviewed or supported by others
- Assignments may change during the sprint ⚠️
| Ticket Field | Purpose |
|---|---|
| Assignee | Primary owner |
| Reviewer | Quality check |
| Labels | Role / area |
Question?
Lab 1 and Homework 1 due Friday, Jan/30
Module 3
Team Structure for Industry 4.0 Applications
Organizing people, roles, and responsibilities in complex systems.
- Define team roles in Industry 4.0 systems
- Escalation paths aligned with the V-model
- Formal communication structures and tools
- Leadership and coordination principles
- Assigned roles: sensor, backend, frontend, data
- Issues escalate from team → TA → instructor
- Slack, GitHub Issues, and sprint demos
- Product Owner guides priorities each sprint
Current team structure
- Cross-functional Teams
- Modular Teams
- Product-Oriented Teams ✓
- Agile/Scrum Teams?
- Hierarchical Teams
Team Communication
- Clear roles reduce coordination overhead
- Direct communication paths avoid bottlenecks
- Shared context supports faster decisions
- Regular feedback keeps the team aligned
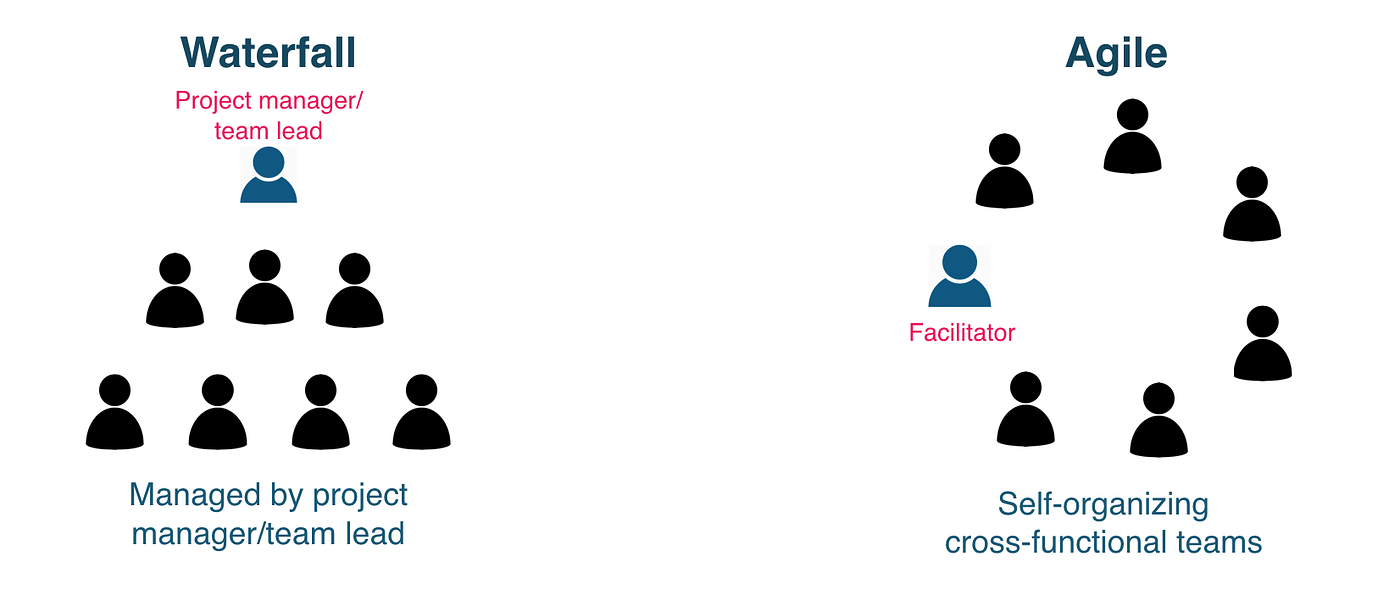
Waterfall
What shall I do next?
- Pause and assess the situation
- Evaluate options and trade-offs
- Choose the most rational next step
- Optimize before acting
Agile
Let's start this task
- Act with incomplete information
- Learn by doing
- Adjust based on feedback
- Progress over perfection
Where can I contribute most?
- What technical strengths do I bring?
- Where can my work unblock others?
- How good are my communication skills?
- Am I more agile (start) or more waterfall (plan)?

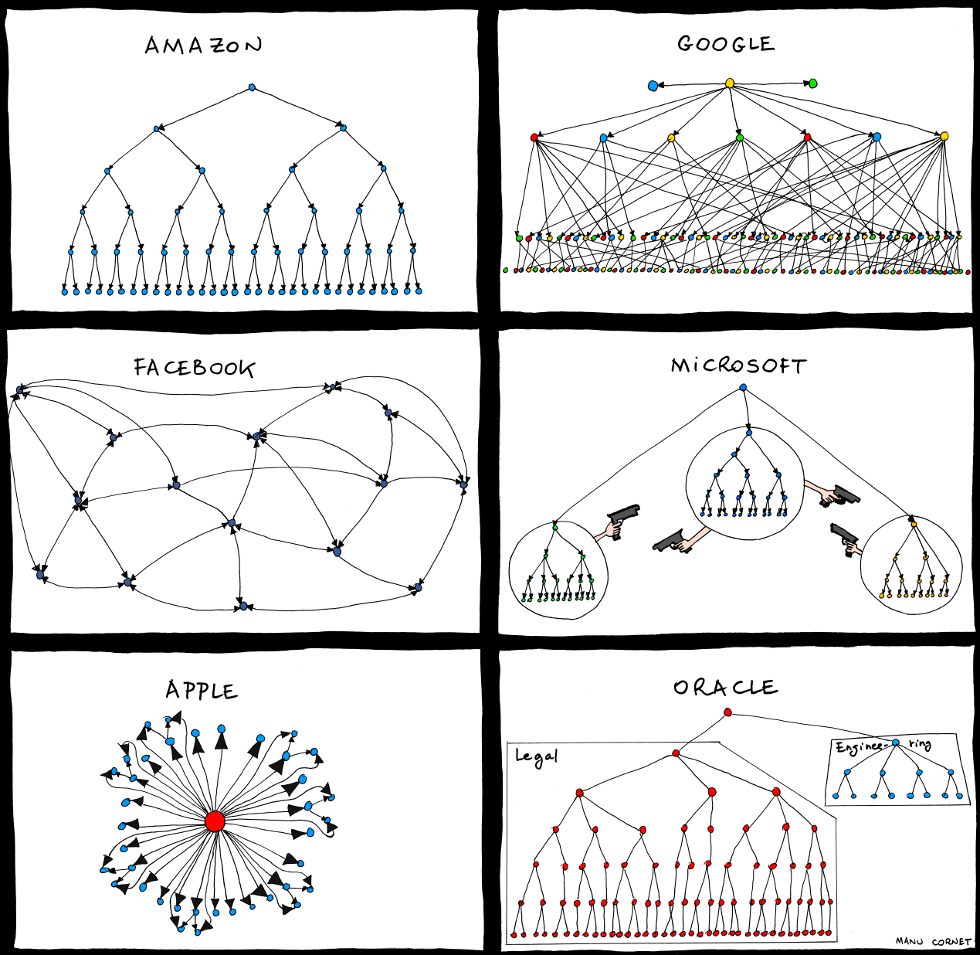
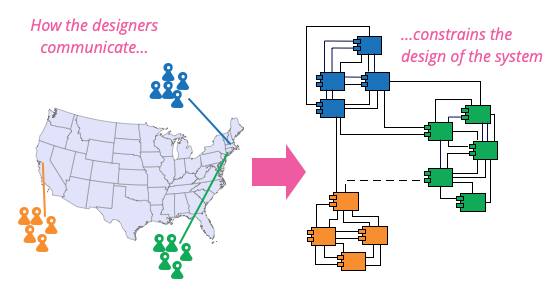
Conway's Law in Industry 4.0
Conway's Law: "Organizations design systems that mirror their team and communication structures."
- In Industry 4.0, team structures influence the design of interconnected systems
- Well-structured teams enable seamless integration of IoT, AI, and robotics
- Poor communication creates fragmented or inefficient systems
to Coordinate Meetings (and more)
Sprint Cycle: Five Meetings
(Refine Backlog)
(Select Work)
(Sync & Blockers)
(Show Increment)
(Improve Process)
Meeting 1: Sprint Grooming (Friday)
- Clarify and refine upcoming work items
- Break goals into actionable tasks
- Estimate effort and dependencies
- Reduce uncertainty before planning
- Review backlog items for Sprint 2
- Refine sensor, backend, and dashboard tasks
- Identify integration and data flow risks
- Prepare a realistic Sprint 2 scope
Meeting 2: Sprint Planning (Friday)
- Select backlog items for the sprint
- Define a sprint goal and success criteria
- Assign responsibilities and clarify interfaces
- Confirm timeline and definition of done
- Choose tasks that support the sprint user story
- Set the sprint goal: working end-to-end increment
- Coordinate handoffs: sensor → API → DB → dashboard
- Agree on done: code merged, tested, demo ready
- Sprint 1 Backlog Planning (2 U-S, 3 tasks)
Meeting 3: Stand-up Meeting (Monday / Wednesday)
- What did you do?
- What are you planning to do?
- Where are you blocked?
- Maintain shared situational awareness
- Weekly stand-up during Sprint 1
- Each role reports: done, next, blocked
- Blockers raised before demo deadline
- Alignment on Sprint 1 demo readiness
Meeting 4: Sprint Demo Meeting (Friday)
- Shared objective aligns individual efforts
- Clear short-term milestone builds trust
- Visible outcome creates accountability
- Feedback loop strengthens coordination
- Single goal: deliver Sprint #1 demo
- All roles contribute to one working system
- Demo forces integration, not silos
- Review clarifies gaps before next sprint
- Sprint 1 Quiz (Canvas)
Meeting 5: Sprint Retrospective (Friday)
- Reflect on process, not individuals
- Identify what worked and what did not
- Capture concrete improvement actions
- Promote continuous learning
- Discuss Sprint 1 coordination and tooling
- Review communication and role clarity
- Note demo preparation challenges
- Define adjustments for Sprint 2
Core Collaboration Spaces
Stand-up Sprint #1
Will Agile/Scrum Framework work for all Requirements?
Software Engineering
vs.Software Engineering for Industry 4.0
Why hardware cannot follow agile sprints
- Long fabrication and procurement lead times
- Physical changes are costly and slow to reverse
- Testing depends on manufacturing completion
- Iterations measured in weeks or months, not days
Hardware Requirements in Sprint 1
- Hardware choices constrain all later work
- Procurement and setup have long lead times
- Late hardware decisions block software progress
- Early clarity reduces integration risk
- Define sensors, boards, and connectivity
- Confirm availability and ordering
- Document assumptions and constraints
- Track in Sprint 1 milestone
- Reference: Sprint 1 Milestone
Ticket Fine Specification
- Clear problem statement and scope
- Well-defined inputs and expected outputs
- Acceptance criteria are explicit and testable
- No ambiguity for implementation or review
- Each ticket answers: what, why, and how
- Includes hardware or software constraints
- Linked to sprint goal and milestone
- Ready for assignment without clarification
Current goal
Define the team structure.
- Philips Hue Smart Lighting System , ~100–150 people
Firmware, hardware, mobile apps, cloud services, UX, QA, manufacturing, product management - Nest Learning Thermostat (Google) , ~150–200 people
Embedded systems, hardware design, mobile/web apps, cloud infrastructure, data science, security, QA - Apple Watch , ~500+ people
Custom silicon, sensors, firmware, watchOS, iOS integration, health algorithms, industrial design, QA - Ring Video Doorbell (Amazon) , ~200–300 people
Computer vision, embedded firmware, cloud backend, mobile apps, security, hardware, QA - Fitbit Fitness Trackers , ~200+ people
Sensor engineering, embedded systems, mobile apps, cloud analytics, data science, UX, QA
Questions on team structure
- Which structure scales as the product grows?
- Which structure enables faster decision making?
- Which structure reduces communication overhead?
- Which structure supports long term maintenance?
- Which structure aligns best with system architecture?
Key question
- Team structure first?
- Architecture first?
Current goal
Which structure do you recommend for our project?
- Cross-functional Teams?
- Modular Teams?
- Product-Oriented Teams?
- Agile/Scrum Teams?
- Hierarchical Teams?

Cross functional teams
- Hardware, software, and data in one team
- All concerns addressed from the start
- Continuous communication
- Fast problem solving
function checkLightStatus(sensor) {
// Requirements defined light states
if (sensor.isLightOn) {
// Architecture defined data flow
// QA tested detection logic
reportLightOn(sensor); // Dev implementation
} else {
reportLightOff(sensor);
}
// Product and UX defined reporting
logLightStatus(sensor);
}
Functional Team Matrix
| Function | Requirements | Architecture | Development | Testing |
|---|---|---|---|---|
| Function 1 | ||||
| Function 2 | ||||
| Function 3 | ||||
| Function 4 |
Advantages
- Clear ownership
- Fast feedback
- Aligned decisions
- Early risk detection
Disadvantages
- Role overlap
- Context switching
- Higher coordination cost
- Scaling complexity
Modular Teams
- Teams per component
- Clear boundaries
- Deep specialization
- Coordination needed
Product Oriented Teams
- Teams per feature
- End to end ownership
- Outcome focused
- Faster decisions
IoT Light Sensor App
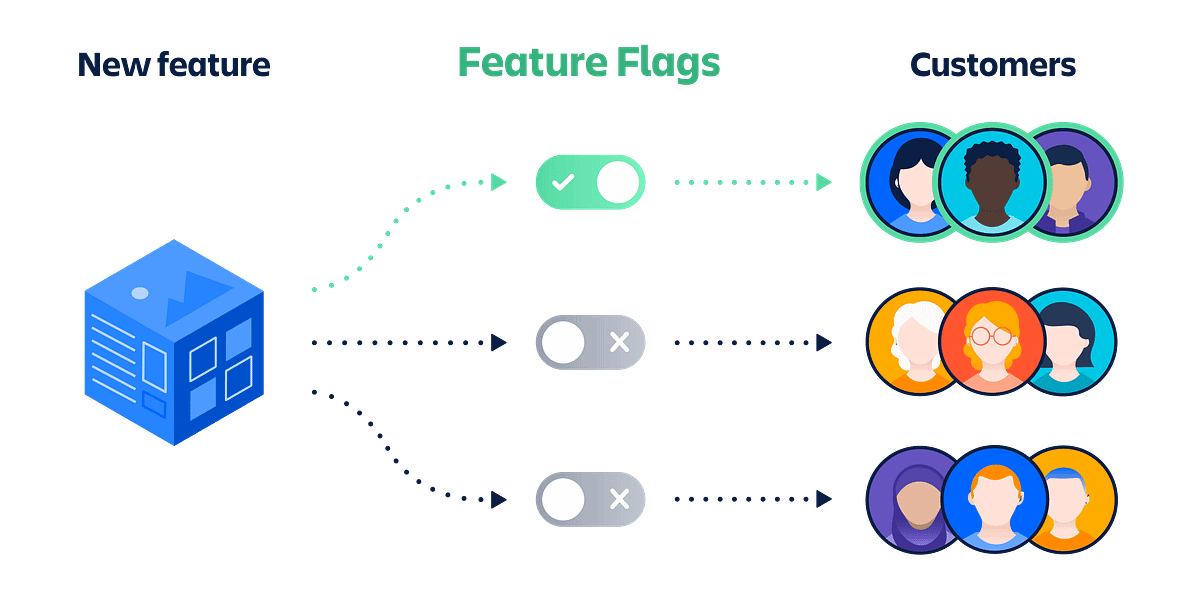
- Feature flag controls reporting
- Detect light on or off
- Send status to backend
- Log events for dashboard
function reportLightStatus(sensor) {
if (featureFlags.isLightReportingEnable{
if (sensor.isLightOn) {
sendStatus("on"); // Backend reporting
} else {
sendStatus("off");
}
} else {
console.log("Light reporting is off");
}
logLightEvent(sensor); // Tracking
}
Controlled Feature Release
- Enable or disable features safely
- Release incrementally
- Reduce deployment risk
- Test in production
- Rollback instantly
Agile / Scrum Teams
- Work in short sprints
- Daily stand ups
- Regular reviews
- Continuous feedback
- Adapt to change

IoT Light Sensor (Sprint Based)
- Sprint 3: Light detection
- Sprint 3: Feature flag control
- Sprint 5: Event logging
- QA per sprint
function reportLightStatus(sensor) {
if (sprint3FeatureFlags.isLightReportingEnable{
if (sensor.isLightOn) {
sendLightOn(sensor); // Sprint 3: Dev task
} else {
sendLightOff(sensor);
}
}
// Sprint 5: Log light event
sprint5LogLightEvent(sensor); // Sprint 5: QA validation
}
Hierarchical Teams
- Single project manager
- Clear reporting lines
- Sub teams per component
- Centralized decisions
- Aligned project vision
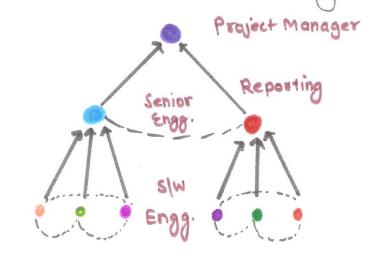
Hierarchical Team
- Lead controls feature flags
- Senior dev implements core logic
- Clear decision authority
- Centralized tracking
function reportLightStatus(sensor) {
if (leadFeatureFlag.isLightReportingEnable{
if (sensor.isLightOn) {
sendLightOn(sensor); // Senior dev implementation
}
} else {
console.log("Light reporting is off");
}
// Tracking handled by project lead
logLightEvent(sensor);
}
What team structure (combinations) do you recommend?
Team Structures Reviewed
- Cross functional teams
- Modular teams
- Product oriented teams
- Agile / Scrum teams
- Hierarchical teams
IoT Light Sensor Dashboard App
Team Structure & Communication Impact on Software Errors
- Mariner 1 Spacecraft, 1962: Poor communication between engineering teams > Small coding error caused mission failure ($18.5 million)
- The Morris Worm, 1988: Lack of collaboration > Single developer's error led to widespread impact ($10 million)
- Pentium FDIV Bug, 1994: Slow internal communication > Mismanagement of response led to massive costs ($475 million)
- Heathrow Terminal 5, 2008: Poor integration between teams > Misaligned goals led to system failure ($1.4 billion)
Team Structures: Pros and Cons
| Team Structure | Pros | Cons |
|---|---|---|
| Cross-functional Teams |
|
|
| Modular Teams |
|
|
| Product-Oriented Teams |
|
|
| Agile/Scrum Teams |
|
|
| Hierarchical Teams |
|
|
Levels of Communication
- Code Level: Communication through code comments and documentation (e.g., GitHub)
- Ticket Level: Use of issue tracking tools for problem-solving (e.g., Jira, GitLab)
- Team Level: Team communication via chat tools (e.g., Slack, Microsoft Teams)
- Project Level: Project updates and reporting (e.g., Trello, Confluence)
Escalation Paths and Norming
- Define team structure in Industry 4.0 systems ✓
- Define roles and responsibilities
- Define escalation paths along the V-Model
- Standard communication tools and channels
- Standard definitions, templates, and workflows
Communication and Risks

Team > Communication > ⚠ > Software > Product
- Misunderstanding
- Information overload
- Delays in decision-making
- Disagreement on priorities
- Assumptions and misinterpretation
- Lack of feedback
Team Communication and Escalations
Phase
- Requirements Gathering
- Team Role Definition
Escalation Path
- Product Owner
| V-Model Phase | Phase Timing | Escalation Responsibility | When to Escalate |
|---|---|---|---|
| Requirements Analysis | Anytime but specifically during requirements gathering | Product Owner | Unclear, conflicting, or incomplete requirements and roles |
| System Design | Before but also after implementation begins | Architecture | Design inconsistencies or integration risks |
| Implementation | During active development and testing | Frontend / Backend / Embedded | Blocking defects, unresolved bugs, or scope confusion |
| Unit Testing | Immediately after implementation | Testing | Failed unit tests or testability issues |
| Integration Testing | After components are combined | Quality | Interface failures or non-functional integrations |
| System Testing | After full system assembly | Testing | System-wide failures or unexpected behavior |
| Acceptance Testing | Before release or deployment | Client | Acceptance criteria not met or client concerns |
Reduce Escalation → Norming
- GitHub Issues: Standard templates
- UML Diagrams: Consistent notation
- Communication: Defined channels and response times
- Code Reviews: Git pull requests
- Documentation: Standard file structure
- Code Workflow: V-Model
- Canvas Labs: Standard format
Norming: Push Notifications
- Slack for Android: Play Store
- Slack for iOS: App Store
- GitHub for Android:Play Store
- GitHub for iOS:App Store
Bookmark Project View
Norming: Slack Handles for Role Responsibility
- (product owner) , requirements, clarifications, scope decisions
- (architecture) , design guidance, integration decisions
- (fronten, UI/UX implementation queries
- (backen, API, data, and service logic discussions
- (database) , testing issues, failed cases, test plans
- (devops) , environment, deployment, and CI/CD concerns
Slack Workspace
Norming: Standard User Story Templates
- User stories capture intent and value
- Acceptance criteria define “done”
- Lightweight, repeatable structure
- Supports review and closure
- GitHub Issue Example
### User Story
As a <role>,
I want <goal>,
so that <benefit>.
### Context
Brief background or motivation for this story.
### Acceptance Criteria
- [ ] Criterion 1
- [ ] Criterion 2
- [ ] Criterion 3
### Notes
Optional design notes, assumptions, or references.
Norming: Standard UML Diagram
@startuml
title IoT Light Sensor - End to End Flow
actor "User" as U
component "Frontend" as FE
component "Backend API" as BE
database "Database" as DB
component "Sensor Device" as S
S --> BE: POST /sensor\n{room_id, light_state, timestamp}
BE --> DB: store sensor event
DB --> BE: query latest state\nand history
BE --> FE: GET /dashboard\nstate + trends
U --> FE: view dashboard
@endumlNorming: Standard Backlog View
- Single standard backlog for the team
- Shared view of priorities and work in progress
- Issues as the source of truth
- Consistent status definitions and workflow
- Reduced escalation through transparency
Standard Backlog View
Reduce Escalation - Performing
- Routine communication and team harmony
- Automate Code Workflow: Unit testing and release
- Define team structure in Industry 4.0 systems ✓
- Escalation paths along the V-model ✓
- Review leadership approaches for managing teams
- Team Building and Listening
- Refine Product Backlog
Biggest Challenge: Lack of adequate skill sets
Feature Branch Workflow
- Main branch remains stable and releasable
- Each change is developed in a dedicated feature branch
- Work is reviewed before merging
- Issues act as the source of truth

Workflow Overview
- Create or assign a GitHub issue
- Create a feature branch from main
- Implement and commit changes
- Open a pull request
- Review, merge, and close the issue
Create a Feature Branch
- Always branch from main
- Use a descriptive, issue-linked name
- One branch per task or user story
git checkout main
git pull origin main
git checkout -b feature/issue-24-slack-integration
Link Branch to a Ticket
- Include issue ID in branch name
- Reference issue ID in commits
- Maintains traceability
git commit -m "Issue #24: integrate GitHub with Slack"
Pull Requests
- Request review before merging
- Discuss changes in context
- Protect the main branch
git push origin feature/issue-24-slack-integration
Merge and Close
- Merge pull request after review
- Close the linked issue
- Delete the feature branch
- Main branch stays clean
Backlog Refinement
- Review and prioritize issues
- Clarify requirements and scope
- Break down tasks for implementation
- Review Team Structure
- Refine Product Backlog
- Sprint #1 Demo
Sprint Day (Today)
Sprint #1 Demo + Retro
Sprint #2 Planning + Grooming
Agenda
- Sprint #1 Demo (show working increment)
- Sprint #1 Retrospective (improve process)
- Sprint #2 Planning (select work + goal)
- Sprint #2 Grooming (refine backlog)
(Sprint 1)
(Sprint 1)
(Sprint 2)
(Sprint 2)
Sprint #1 Demo
Purpose
- Prove the increment works (not slides)
- Force integration across roles
- Collect feedback for Sprint #2
- Confirm what is done vs almost done
Rule
Demo only what runs.
- If it crashes, we learn (no blame)
- If it works, we document how to reproduce
- If it is unfinished, we label it clearly
Definition of Done (Sprint #1)
- Code merged to main (or clearly staged)
- Basic tests executed (even manual)
- README updated for demo steps
- Issue or story closed with evidence
- No hidden setup steps
DoD checklist (quick):
[ ] Can a teammate run it in <10 minutes?
[ ] Inputs and outputs are visible
[ ] Failure mode is explained
[ ] Link: PR / issue / commit is provided
Sprint #1 Demo
Sprint #1 Retrospective
Purpose
- Improve process (not personalities)
- Turn lessons into concrete actions
- Reduce future escalation through norms
Be specific
- Name the situation (what happened)
- Name the impact (why it matters)
- Name the adjustment (what we will do)
Retro Format: Start / Stop / Continue
Retro Output: 3 Concrete Actions
- Action #1: owner + due date
- Action #2: owner + due date
- Action #3: owner + due date
Action template:
- Problem:
- Change:
- Owner:
- Due:
- Evidence (how we know it improved):
Sprint #1 Retrospective
Sprint #2 Planning
Inputs
- Sprint #1 demo feedback
- Open issues and known gaps
- Team capacity (time + skill)
- Integration risks
Outputs
- Sprint #2 goal (one sentence)
- Selected stories and tasks
- Owners per item
- Shared definition of done
Sprint #2 Goal
Samples...
- End to end improvement (not isolated work)
- User visible change on the dashboard
- Reduced manual steps or reduced failure rate
Examples (pick one pattern):
1) "Dashboard shows latest 24h history for one room."
2) "API validates payloads with clear errors."
3) "Sensor events appear on UI within N seconds."
Capacity and Commitments
- Capacity is not wishful thinking
- Assume friction: setup, merge conflicts, debugging
- Protect integration time near the end
- Keep one buffer task (optional)
Simple capacity rule:
- Commit to 70% of what you think you can do
- Reserve 30% for integration + unknowns
"Leave room for reality"
Sprint #2 Planning
Sprint #2 Grooming
Grooming Checklist
- Each issue has clear scope
- Acceptance criteria are testable
- Dependencies are named
- Labels and milestones are correct
- Small enough to finish in the sprint
Ready-to-plan test:
- Can the assignee start without asking 3 questions?
- Can a reviewer verify "done" quickly?
- Is the interface (API/DB/UI) defined?
Norms for Sprint #2
- One source of truth: GitHub Issues
- Short updates in Slack, decisions in issues
- PR early, PR often (small merges)
- Raise blockers fast (team → TA → instructor)
Team ✓ > Communication > Software > Product
- Good coordination prevents technical debt
- Clear interfaces prevent rework
- Consistency beats heroics
Sprint #2 Grooming
Module 4
Development Processes in Industry 4.0
Standard processes for IoT and CPS: requirements, verification, secure delivery, and safe updates.
Today
- NIST standards for IoT/CPS process
- Process requirements: traceability, constraints, evidence
- Test Driven Development (TDD)
- V Model (brief)
- Agile/Scrum (brief)
- Beyond TDD: CI/CD, secure updates, monitoring

Stakeholders in IoT / CPS
- Users
- Developers
- Costs
- Cyberspace / Society
- Nature 🌸
- Regulations
Nature is a first-class stakeholder: energy use, sustainability, and environmental impact are part of system design.
NIST process anchors for IoT/CPS
- CSF 2.0: organize cybersecurity risk work
- SSDF: build software securely from the start
- SP 800-213 / 213A: define IoT device requirements
- NISTIR 8259A: device capability baseline
Checklist and vocabulary for “what good looks like”.
CSF shaped process loop (IoT/CPS)
- Plan risk work as a repeatable cycle
- Make security part of normal engineering
- Keep evidence: tickets, PRs, test reports
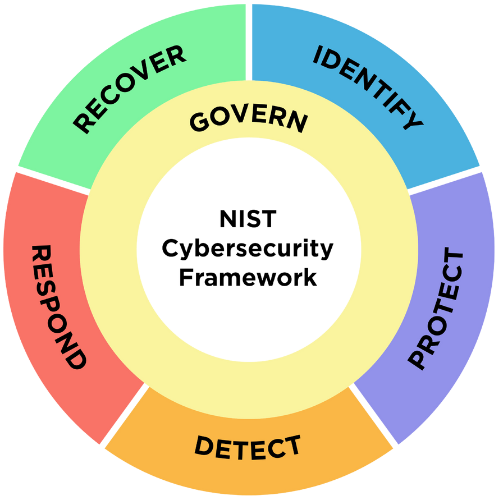
CSF: Govern
- Decide acceptable risk
- Assign ownership
- Record decisions
- Require evidence
{
"csf": "govern",
"artifact": "risk_entry",
"risk_id": "R-001",
"decision": "accept_with_controls",
"severity": "high",
"owner": "team_lead",
"controls": ["tests", "staged_update"],
"evidence": ["ticket", "pr", "tests"]
}CSF: Identify
- Give everything an ID
- Track versions
- Know ownership
- Classify data
{
"csf": "identify",
"artifact": "asset_record",
"device_id": "uuid",
"type": "soil_sensor",
"firmware": "1.3.0",
"owner": "greenhouse-a",
"location": "room-3",
"data_class": "internal"
}CSF: Protect
- Encrypt data
- Control access
- Secure defaults
- Verify updates
{
"csf": "protect",
"artifact": "security_controls",
"encryption": ["tls", "at_rest"],
"auth": "token_rbac",
"secure_defaults": true,
"signed_updates": true,
"rollback": true
}CSF: Detect
- Log events
- Monitor health
- Detect anomalies
- Alert operators
{
"csf": "detect",
"artifact": "alert_rule",
"signal": "humidity",
"condition": "<5 or >95",
"severity": "high",
"action": "alert",
"channel": "oncall"
}CSF: Respond
- Contain the issue
- Assess impact
- Fix or mitigate
- Communicate
{
"csf": "respond",
"artifact": "incident",
"incident_id": "INC-202",
"severity": "high",
"containment": "quarantine_device",
"status": "open",
"owner": "oncall"
}CSF: Recover
- Restore service
- Verify stability
- Learn and improve
- Prevent recurrence
{
"csf": "recover",
"artifact": "recovery_record",
"incident_id": "INC-202",
"strategy": "staged_rollout",
"rollback": true,
"verification": "health_checks",
"followup": "add_tests"
}SSDF
Build software securely from the start
- Security is part of the development process
- Risks are addressed before release
- Evidence is produced continuously
- Aligned with modern supply chain threats
{
"framework": "NIST SSDF",
"goal": "secure_by_design",
"scope": ["code", "dependencies", "build", "release"],
"principle": "shift_left",
"outputs": ["evidence", "traceability", "repeatability"]
}SSDF: Prepare the Organization
- Define secure coding rules
- Set roles and responsibilities
- Require baseline security checks
- Train teams on common risks
{
"ssdf": "prepare",
"artifact": "secure_dev_policy",
"owner": "engineering",
"required_checks": ["tests", "lint", "sast"],
"branch_rules": ["pr_required", "1_reviewer", "checks_green"],
"secrets_policy": "no_secrets_in_repo",
"training": "owasp_basics",
"evidence": "policy_versioned"
}SSDF: Protect the Software/Data
- Protect source control
- Protect secrets
- Track dependencies
- Sign build artifacts
- Example: IoT Light Sensor App
{
"ssdf": "protect",
"artifact": "supply_chain_controls",
"repo": ["protected_main", "signed_commits"],
"secrets": ["vault", "rotate"],
"dependencies": "sbom",
"artifacts": "signed",
"access": "least_privilege",
"evidence": "audit_logs"
}SSDF: Produce Well Secured Software
- Threat model the system
- Use secure design patterns
- Review code changes
- Test security continuously
{
"ssdf": "produce",
"artifact": "secure_build_pipeline",
"design": ["threat_model", "secure_defaults"],
"reviews": "pr_review_required",
"testing": ["unit", "integration", "sast"],
"build_gate": "fail_on_high",
"traceability": "ticket_to_pr",
"evidence": "pipeline_reports"
}Security Regression Test
Injection-style input
- Assume hostile input
- Reject anything not ISO date
- Lock behavior with a test
- Prevent reintroduction of bugs
def test_usage_date_rejects_injection(client):
payloads = [
"2026-02-02' OR '1'='1",
"2026-02-02--",
"$ne",
'{"$gt":""}',
"../etc/passwd",
"not-a-date"
]
SSDF: Respond to Vulnerabilities
- Intake reports and triage
- Patch quickly and safely
- Publish advisories if needed
- Prevent recurrence with tests
- Example: IoT Light Sensor Security Policy
{
"ssdf": "respond",
"artifact": "vuln_workflow",
"intake": "security_issue_template",
"triage": ["severity", "exploitability"],
"fix": ["patch", "regression_tests"],
"release": "staged_rollout",
"verify": "post_update_checks",
"evidence": "advisory_or_ticket"
}SSDF in one release
- Policy and roles set the baseline
- Controls protect code and artifacts
- Pipelines enforce secure build gates
- Vulnerability response feeds back to backlog
{
"ssdf": "release_loop",
"artifact": "release_record",
"gates": ["review", "tests", "sast", "sbom", "signing"],
"deploy": "staged",
"monitor": "health_checks",
"rollback": true,
"traceability": "tickets",
"evidence": "release_notes"
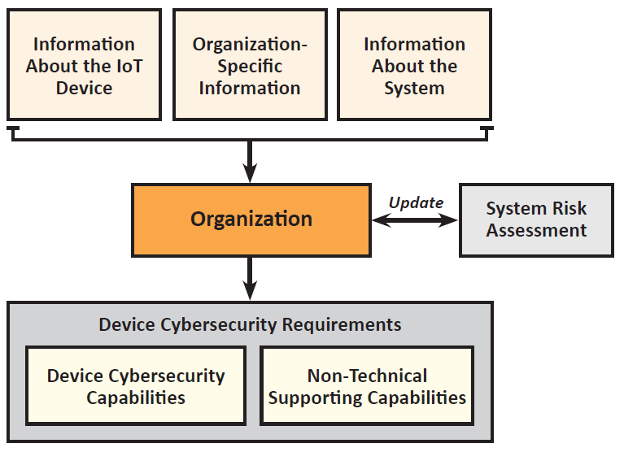
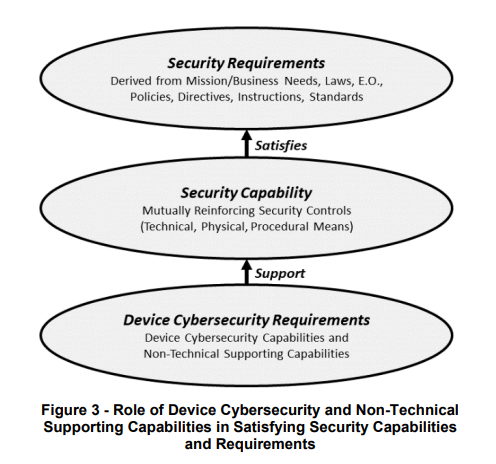
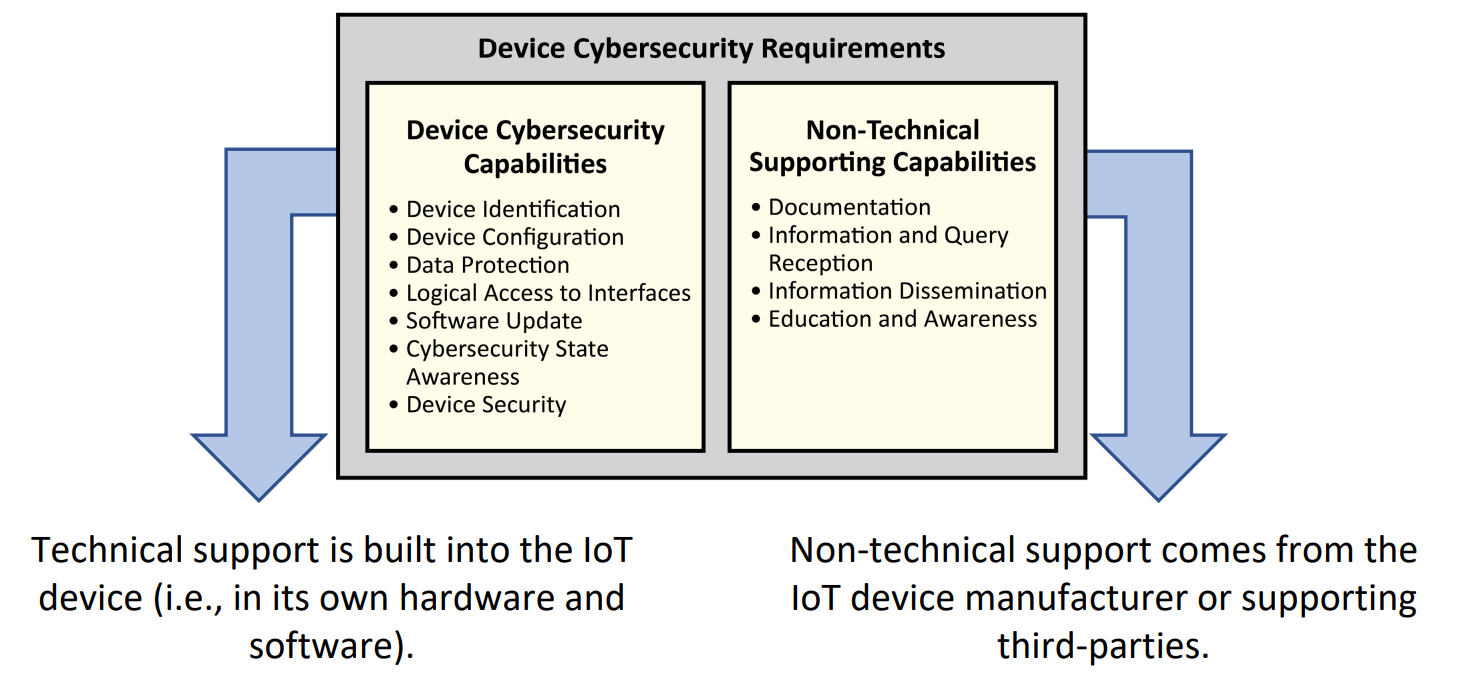
}SP 800-213 / 213A
Defining IoT device requirements
- What the device must support
- What the manufacturer must provide
- Focused on risk and lifecycle
- Used for procurement and design
Device Identification & Configuration
- Unique device identity
- Stable identifiers over time
- Secure initial configuration
- No shared default credentials
Know which device is operating.
{
"device": {
"device_id": "6f9c2c4e-3a91-4c2b-9e6d-1b7a9c21e4a8",
"type": "light_sensor",
"model": "LS-100",
"hardware_rev": "A",
"firmware_version": "1.2.3"
},
"provisioning": {
"provisioned_at": "2026-02-02T18:12:00Z",
"provisioned_by": "factory",
"initial_config": "secure_defaults",
"credentials": "unique_per_device"
}
}Data Protection & Interfaces
- Protect data in transit and at rest
- Clearly defined interfaces (API, ports)
- Limit exposed services
- Prevent unauthorized access
Goal: reduce attack surface.
Software Update & Lifecycle
- Secure update mechanism (OTA)
- Signed and verified updates
- Rollback capability
- Defined support lifetime
Goal: devices remain safe after deployment.
Logging, Monitoring & Evidence
- Log security relevant events
- Support monitoring and diagnostics
- Provide evidence for audits
- Enable incident response
- Example Demo IoT Light Sensor
Goal: prove correct and secure behavior.
Process requirements in IoT/CPS
Traceability
- Requirement ↔ design ↔ code
- Requirement ↔ tests ↔ evidence
- Ticket IDs link the chain
Constraints
- Safety limits and failure modes
- Timing and real time behavior
- Power, memory, bandwidth
- Regulatory and privacy needs
In CPS, constraints are requirements. They must be tested and shown as evidence.
Traceability as a deliverable
- Every change starts with a ticket
- PR references ticket
- Tests produce proof
- Release notes point back to evidence
IoT device requirements (what you demand from the device)
- Identity and authentication
- Secure configuration and defaults
- Patchability and secure updates
- Logging, telemetry, and audit
Test Driven Development
- Write a failing test (behavior)
- Implement the smallest fix
- Refactor safely (tests stay green)
- Repeat in small steps
For CPS, TDD helps keep updates safe and predictable.
TDD: tests by layer
Unit (fast)
- Pure rules and thresholds
- Parsers and validators
- Scheduling and time logic
Integration (real)
- Sensor → API
- API → database
- Database → dashboard
- Update → device behavior
TDD example (Room light sensor)
- Behavior: low light in room triggers alert
- Test defines acceptable light range
- Logic stays simple and explicit
// tests first (pseudo)
expect(shouldAlert({ lux: 8 })).toBe(true); // too dark
expect(shouldAlert({ lux: 22 })).toBe(false); // normal
expect(shouldAlert({ lux: 45 })).toBe(false); // bright but acceptable
// minimal implementation
function shouldAlert(r) {
return r.lux < 10;
}Beyond TDD: CI/CD gates and evidence
- Build and test on every PR
- Security scans as checks
- Artifacts versioned and traceable
- Release notes tied to tickets
This is how teams keep “quality” consistent over time.
Beyond TDD: secure update process (OTA)
- Signed build artifacts
- Staged rollout (canary)
- Rollback plan
- Post update verification
In CPS, updates are engineering work, not an afterthought.
Beyond TDD: monitoring and incident response
- Telemetry and logs
- Anomaly detection
- Incident playbooks
- Post incident fixes feed backlog
V Model (brief)
- Best when assurance is high
- Plan tests while defining requirements
- Strong traceability from requirements to tests
CPS teams often use V Model thinking for evidence, even inside Agile delivery.
Agile / Scrum
- Short iterations, frequent feedback
- Backlog → sprint → increment
- Works well for UI and integration learning
Keep it disciplined: Definition of Done includes tests and evidence.
Questions?
In IoT/CPS: process is part of the product.
Early Validation of Device Data Behavior
- Validate sensor data behavior early, before hardware is ready
- Focus on how data should evolve over time, not on software logic
- Define normal ranges, trends, noise, and drift
- The digital twin becomes the reference for “expected device behavior”
- Real device data is later compared against this reference
Digital Twin: Real Entity vs Model
IoT and CPS Communicate and Control Through Data
In Industry 4.0 systems, physical devices and cyber physical systems do not interact directly. All sensing, reasoning, and control happens through data. A digital twin operates at the same data interface as the real sensor and can therefore simulate it.
Why Use a Digital Twin?
- Safety tests cannot cover every real condition
- Some test conditions are difficult or expensive to reproduce
- Example: lighting changes, glare, shadows, placement, rain, etc.
- Tests tell us if code follows rules for selected cases
- A digital twin tells us if the system still behaves as expected over time
- The twin is stable; the real world is not
- Deviation from the twin is a signal to investigate
- Flashing and installing software takes time





Digital Twin = Comparison Over Time
Practical View: Twin Predicts Expected Lux
- The twin encodes assumptions: day/night cycle, clouds, attenuation
- No sensor input is used here
- This code stays unchanged after deployment
# twin_sim.py
def predicted_lux(ts, cloud_cover, cfg):
h = ts.hour + ts.minute / 60
if h < cfg.sunrise_hour or h > cfg.sunset_hour:
return cfg.night_lux
span = cfg.sunset_hour - cfg.sunrise_hour
x = (h - cfg.sunrise_hour) / span
daylight = math.sin(math.pi * x)
attenuation = 1.0 - 0.75 * cloud_cover
return cfg.night_lux + (cfg.peak_lux - cfg.night_lux) * daylight * attenuationPractical View: Evaluating the Real Device
- Store both predicted and observed values
- Compute deviation metrics
- Look for trends, not single failures
# twin_eval.py
pred = [d["lux_pred"] for d in readings]
obs = [d["lux_obs"] for d in readings]
errors = [o - p for o, p in zip(obs, pred)]
mae = sum(abs(e) for e in errors) / len(errors)
print("Mean Absolute Error:", round(mae, 2))If the device changes behavior, the deviation grows - even if tests still pass.
In Industry 4.0, development does not stop at deployment.
- Tests protect correctness at a point in time
- Digital twins protect correctness over time
- The same twin works before and after deployment
- Only the data source changes: simulated → real
Example: Same Data Shape (Real Sensor vs Digital Twin)
- The CPS reads one record shape:
device_id,ts,lux - Real device writes
luxfrom hardware - Digital twin writes
luxfrom the model - Everything downstream stays identical (API, DB, dashboard, alerts)
{
"device_id": "ls-100-0001",
"room_id": "room-101",
"ts": "2026-02-04T18:00:00Z",
"lux_source": "real",
"lux": 128.4
}Why Integrate the Digital Twin into Automation?
-
Generate real-time data
The twin produces timestamped sensor data at the same rate as a real device, so pipelines, dashboards, and alerts run continuously. -
Generate conditional data
Edge cases can be produced on demand: darkness, glare, drift, stuck sensors, or invalid readings, conditions that are hard to test with hardware. -
Test expected behavior
Automation validates trends and reactions over time, not just single inputs: thresholds, anomaly detection, and control decisions.
Automation: On Git Push Run Twin Simulation + Basic Gate
- Developer pushes to a feature branch
- GitHub Actions runs
pytest - Then runs
twin_sim.pyandtwin_eval.py - Fail the workflow if the twin metrics exceed a threshold
- Old habit, solid result: quality is enforced before merge
name: twin-gate
on:
verify:
runs-on: ubuntu-latest
steps:
...
- name: Twin simulate (writes to DB)
env:
MONGO_URI: ${{ secrets.MONGO_URI }}
DB_NAME: light_sensor_db
DEVICE_ID: ls-100-0001
run: python twin/twin_sim.py
Data Contracts in IoT Systems
Interfaces Are Where Failures Happen
Sensor Payload Structure
{
"device_id": "ls-100-0001",
"timestamp": "...",
"lux": 215.4
}
Units Are Part of the Contract
Timestamps Define Order
Time rooms Must Be Explicit
Schema Versioning
"schema_version": "1.1"
Backward Compatibility
Contracts Enable Automation
Why This Matters for CPS
Today
- Review Software Engineering Process
- Sprint #2 Demo | Retrospective | Planning | Grooming
Review: What is a “Process”?
- Process = repeatable way to turn inputs into outputs
- Inputs: requirements, tickets, constraints, code, data
- Activities: design, implement, test, review, deploy
- Outputs: artifacts you can point to (PR, tests, build, docs)
- Outcome: the real effect in the world (reliability, safety, learning)
- WIP (Work In Progress): unfinished work that slows flow and hides problems
Sprint #2 Chart
- This chart shows flow, not speed
- Green reflects growing understanding of the work
- Purple shows validated completion
- Flat areas mean work was in progress or blocked
- Steep rises indicate alignment and resolution
- The gap represents uncertainty and risk
- Sprint #2 is steadier because foundations were already in place
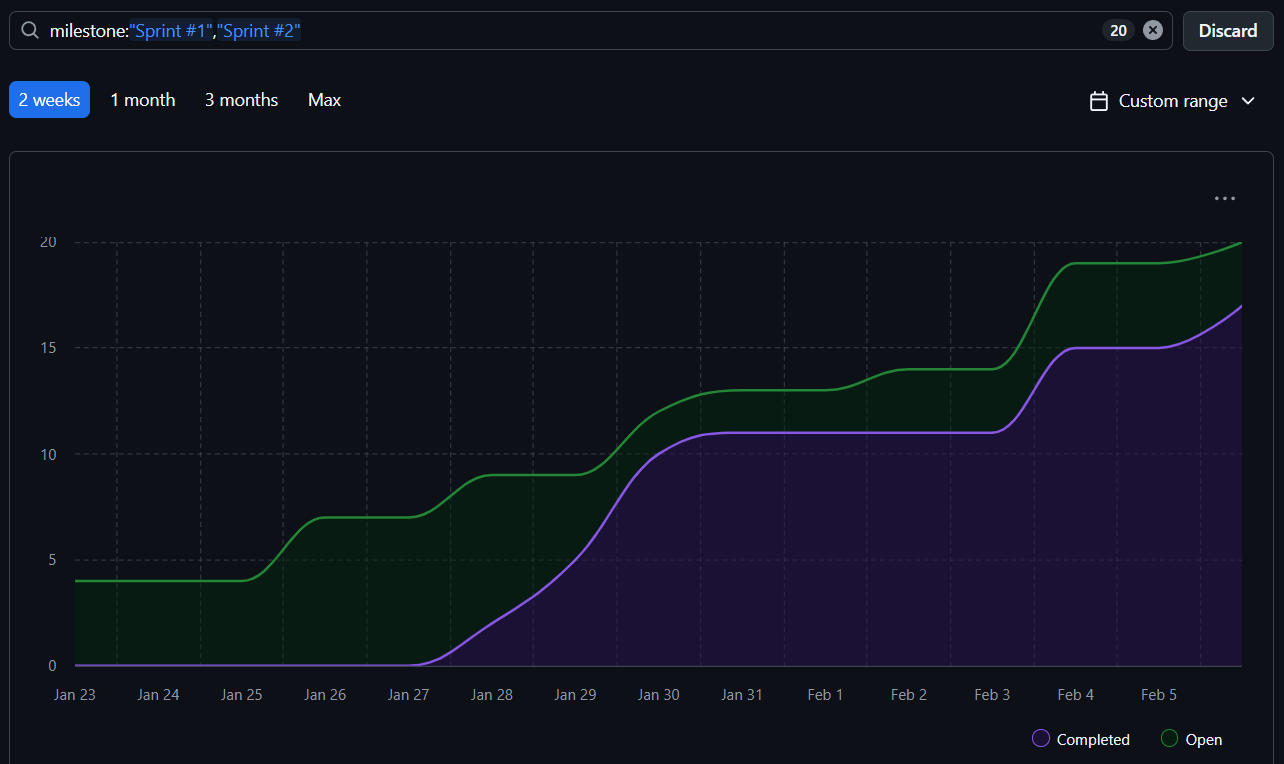
WIP = 1
- WIP = Work In Progress
- WIP = 1 means the team works on one thing at a time
- Nothing new starts until the current work is finished
- Finishing creates flow; starting creates delay
- Problems surface faster when there is no place to hide
- Quality improves because attention is not split
- This is old wisdom from manufacturing and queues
Push vs Pull (Tickets)
Push
- Work is assigned regardless of capacity
- Creates queues and multitasking
- Progress looks busy but finishes late
- Risk accumulates silently
Pull
- Work is taken only when there is capacity
- Directly enforces WIP limits
- Completion drives the system
- Predictability improves over time
Why This Matters
- WIP = 1 + pull creates finish-first behavior
- The system optimizes for completion, not activity
- Flow reveals bottlenecks (blockers) early
- This is how teams move from chaos to control
User Stories (What? Why?) vs Tasks (How?)
- User stories describe intent: what value the user needs
- A user story is a container, not the work itself
- Tasks do the work: coding, testing, wiring, documenting
- Multiple tasks usually implement one user story
- Tasks are concrete and finishable; stories stay abstract
- Progress is real only when tasks are done
- Stories close when all required tasks are complete
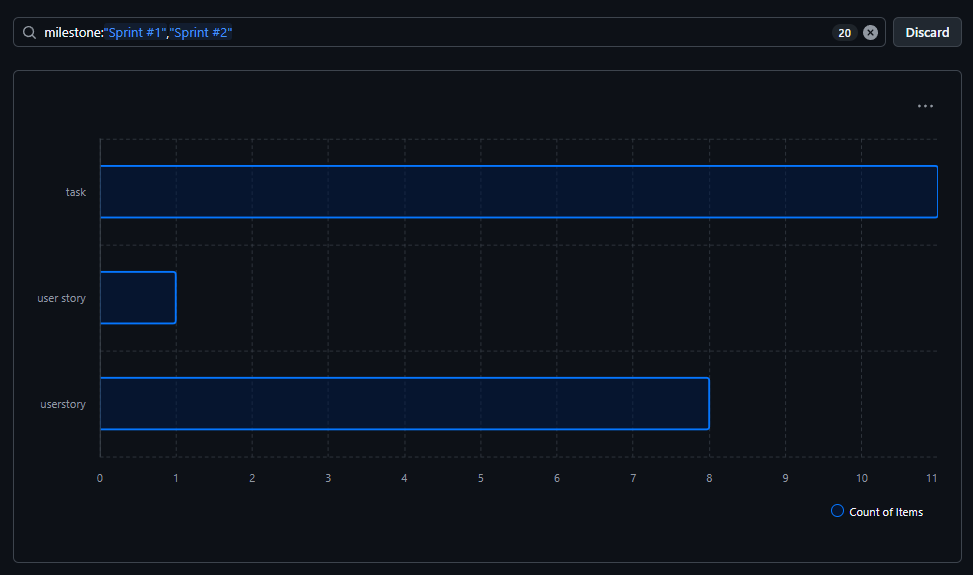
Sprint #2 Demo
- Show a working increment
- Run the happy path end to end
- Focus on behavior, not slides
- State clearly what is done vs not done

Sprint #2 Retrospective
- What went well
- What caused friction or delay
- Where assumptions were wrong
- One concrete improvement for next sprint
- Focus on process, not people
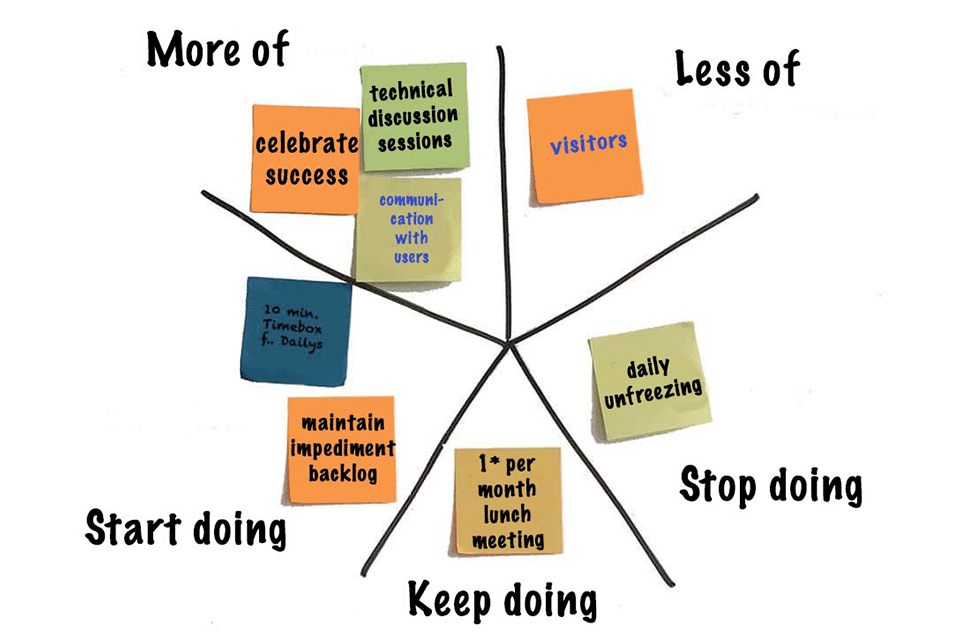
Sprint #2 Planning
- Agree on a clear sprint goal
- Select work that directly supports the goal
- Confirm scope fits the timebox
- Define Done before starting

Sprint #2 Grooming
- Clarify requirements and constraints
- Split oversized or vague tasks
- Identify dependencies and risks early
- Reduce WIP by finishing before starting more

Module 5
Architectural Design for Industry 4.0 Applications
- Structure for scale and integration
- Decisions that are costly to reverse
- Diagrams that answer real questions
Agenda
- Introduction to Software Architecture
- Architecture drivers and tradeoffs
- Architectural styles and patterns
- UML for architecture documentation
- Structural diagrams (many examples)
- Behavior diagrams (core examples)
- PlantUML workflow (how to generate diagrams)
- Case study: Room Light Sensor IoT App
- Practice questions
Software Architecture (Concept)
What is Software Architecture?
- A shared understanding of system structure
- Early choices that constrain later work
- System boundaries: inside vs outside
- Decisions you pay for if wrong
“Architecture represents the decisions you wish you could get right early.”
: Ralph Johnson
Technology Choices for MVP 1
- SensorWhich hardware measures light (lux) or just ON/OFF state?
- DatabaseWhat should store events and current state?
- Programming LanguageWhat runs the API and business logic?
- Server TechnologyHow is the API hosted and exposed?
- InterfacesWhich API Endpoints required?
- Data ModelHow is data structured and related?
- DeploymentCI-CD or manual deployment?
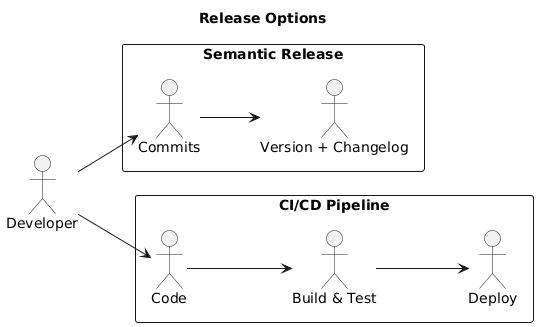
Architecture Drivers
- Modularity (structure and boundaries)
- Separation of concerns (clear responsibility split)
- Scalability (growth without redesign)
- Maintainability (ease of change)
- Performance (latency and throughput)
- Security (protection and access control)
- Observability (logs, metrics, diagnostics)

Running Example: Room Light Sensor IoT App
| Part | Responsibility | Boundary Question |
|---|---|---|
| Sensor Device | Measures light and emits events | What is done on device vs server? |
| Firmware | Packages readings, handles retries | How much logic lives on constrained hardware? |
| Ingestion API | Validates and accepts payloads | What is trusted at the edge? |
| Authentication | Identifies devices and users | How are devices provisioned and revoked? |
| Storage | Persists sensor events | Events only, or current state too? |
| Read Model | Stores current room state | How fresh must reads be? |
| Rules Engine | Evaluates thresholds and conditions | Sync calls, or async events? |
| Alerting | Notifies on anomalies | Who is notified and how often? |
| Dashboard | Displays room state and history | Read model shape and latency? |
| API Gateway | Single entry point for clients | How much routing and policy lives here? |
| Logging | Captures system behavior | What must be observable in production? |
| Deployment | Runs and scales services | Where are scaling and failure handled? |
Core Payload
{
"room_id": "CTC-114",
"light_state": "ON",
"lux": 350,
"timestamp": "2026-02-09T09:15:00-08:00",
"device_id": "sensor-ctc-114-01"
}

Architectural Styles
Architecture Style Comparison
| Style | Best When | Main Risk | Typical Signal |
|---|---|---|---|
| Monolith | Small team, fast iteration, simple ops | Scaling and release coordination | One repo, one deploy |
| Layered | Clear separation and testability | Layer violations, slow cross layer changes | UI → API → domain → data |
| Microservices | Independent ownership and scaling | Operational complexity, distributed debugging | Many deploys, strong contracts |
| Event Driven | Streams, decoupling, replay, audit | Event schema governance, ordering, replay complexity | Bus + projections |
Structural
| Diagram | Purpose |
|---|---|
| Component | Service boundaries and dependencies |
| Deployment | Runtime nodes and network boundaries |
| Package | Code organization and allowed dependencies |
| Class | Core data structures and relationships |
Behavior
| Diagram | Purpose |
|---|---|
| Sequence | Messages exchanged over time |
| Activity | Workflow and decision logic |
| State Machine | Valid states and transitions |
| Use Case | Actors and system goals |
UML and PlantUML: Chronological Timeline
| Year | Item | What It Is | Context / Impact |
|---|---|---|---|
| 1980s | State Machines | Formal modeling of states and transitions | Adopted from automata theory and control systems |
| Early 1990s | Class Diagrams | Object oriented structure modeling | Booch method and OMT (Rumbaugh) |
| 1994 | Sequence Diagrams | Time ordered message interaction | OOSE by Ivar Jacobson |
| 1995 | Use Case Diagrams | Actors and system goals | Requirements driven modeling |
| 1996 | Activity Diagrams | Workflow and control flow modeling | Business process representation |
| 1997 | UML 1.0 | Unified Modeling Language | Standardization by Booch, Rumbaugh, Jacobson (OMG) |
| 1997 | Component Diagrams | Service and module boundaries | Architecture level modeling |
| 1997 | Deployment Diagrams | Runtime nodes and infrastructure | Operational and physical layout |
| 2009 | PlantUML | Text based UML diagram generator | Diagrams as code, version controlled |
Layered Architecture
@startuml
title Layered (Nested): Sensor → Backend → Database + Frontend
skinparam componentStyle rectangle
skinparam shadowing false
top to bottom direction
package "Frontend" {
component "Web Dashboard"
}
package "Backend" {
component "API"
component "Rules"
}
package "Database" {
database "DB"
}
package "Sensor" {
component "Sensor Device"
}
"Sensor Device" --> "API": POST /events
"Web Dashboard" --> "API": GET /rooms/{id}
"API" --> "Rules"
"API" --> "DB": read/write
@enduml
Client–Server Deployment
@startuml
title Client Server Deployment (Room Light Sensor)
skinparam componentStyle rectangle
skinparam shadowing false
left to right direction
node "Client: Browser" as Browser {
artifact "Dashboard UI" as UI
}
node "Client: Sensor Device" as Sensor {
artifact "Firmware" as FW
}
node "Server" {
artifact "HTTP API" as API
database "Sensor DB" as DB
}
FW --> API: HTTPS POST /events
UI --> API: HTTPS GET /rooms/{id}
API --> DB: SQL queries
@enduml
Monolith Architecture (Room Light Sensor)
@startuml
title Monolith (Room Light Sensor)
skinparam componentStyle rectangle
skinparam shadowing false
left to right direction
component "RoomLightApp (single deploy)" as App {
[Ingestion]
[Query API]
[Rules Engine]
[Alerting]
[Admin UI]
}
database "Sensor DB" as DB
node "Sensor Device" as Sensor
node "User Browser" as Browser
Sensor --> App: POST /events
Browser --> App: GET /dashboard
App --> DB: read/write
[Ingestion] --> [Rules Engine]
[Rules Engine] --> [Alerting]
[Query API] --> DB
[Ingestion] --> DB
@enduml
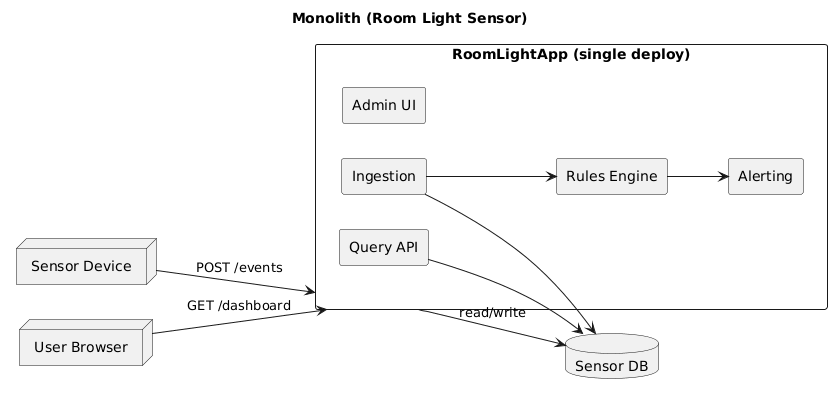
Microservices Architecture (Room Light Sensor)
@startuml
title Microservices (Room Light Sensor)
skinparam componentStyle rectangle
skinparam shadowing false
left to right direction
node "Sensor Device" as Sensor
node "User Browser" as Browser
component "API Gateway" as GW
component "Ingestion Service" as Ingest
component "Room Query Service" as Query
component "Rules Service" as Rules
component "Alert Service" as Alert
queue "Event Bus" as Bus
database "Events Store" as EventsDB
database "Rooms Read Model" as RoomsDB
Sensor --> GW: POST /events
Browser --> GW: GET /rooms/{id}
GW --> Ingest: forward event
Ingest --> EventsDB: append event
Ingest --> Bus: publish LightEvent
Rules --> Bus: subscribe LightEvent
Rules --> Alert: create alert
Rules --> RoomsDB: update room state
GW --> Query: forward query
Query --> RoomsDB: read room state
@enduml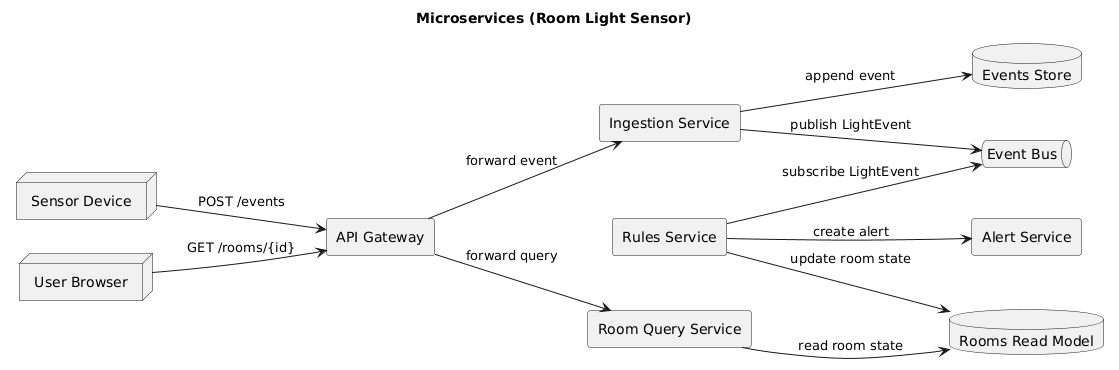
Event Driven Architecture
@startuml
title Event Driven Architecture (Room Light Sensor)
skinparam componentStyle rectangle
skinparam shadowing false
left to right direction
component "Ingestion" as Ingest
queue "Event Bus" as Bus
component "Projection Builder" as Project
component "Rules Engine" as Rules
component "Dashboard API" as API
database "Event Store" as ES
database "Read Model" as RM
Ingest --> ES: append LightEvent
Ingest --> Bus: publish LightEvent
Project --> Bus: subscribe LightEvent
Project --> RM: build room state
Rules --> Bus: subscribe LightEvent
Rules --> Bus: publish AlertEvent
API --> RM: query room state
@enduml
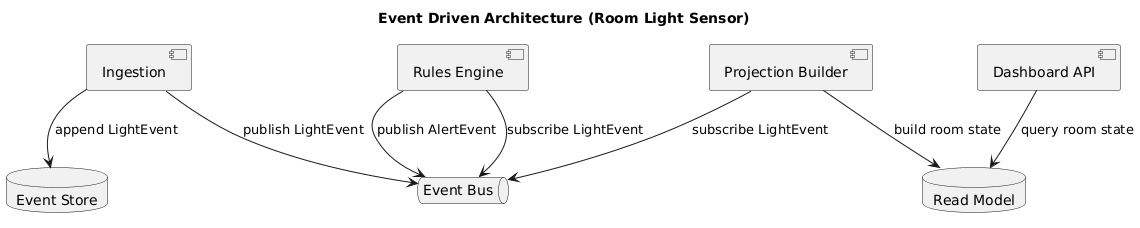
Continuous Architecture
| Concept | Description |
|---|---|
| Definition | Architecture that evolves continuously as the system changes |
| Assumption | Requirements, scale, and technology will change over time |
| Practice | Architecture work is part of regular development, not a one time phase |
| Environment | DevOps, CI/CD, cloud native systems |
| Diagram Rule | Why it matters |
|---|---|
| Every component shows a version | Version changes can break architecture assumptions |
| Languages are explicit | Example: Python 3.11, Java 21 |
| Databases are explicit | Example: PostgreSQL 16, MongoDB 8.0 |
| Infrastructure is explicit | Example: Linux 6.x, Nginx 1.26 |
| Diagrams are time scoped | Architecture is valid for a specific point in time |
Example in diagrams:
API Service (Python 3.11)
Database (MongoDB 8.0)
-
Technology version explorer:
releasetrain.io/arch -
Continuous Architecture (research overview):
ScienceDirect
Behavior Diagrams (What happens)
- Use case: actors and goals
- Sequence: messages over time
- Activity: workflow and branching
- State machine: allowed states and transitions
| Question | Pick |
|---|---|
| Who does what? | Use case |
| Who talks to whom, in what order? | Sequence |
| What is the pipeline logic? | Activity |
| What states are legal? | State machine |
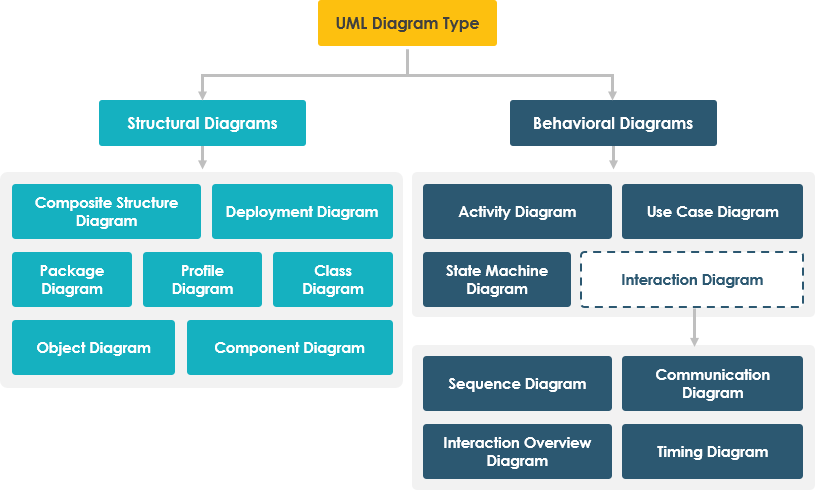
Use Case Diagram (Room Light Sensor)
@startuml
title Use Case Diagram (Room Light Sensor)
skinparam shadowing false
left to right direction
actor "Building Admin" as Admin
actor "Sensor Device" as Sensor
rectangle "Room Light System" {
usecase "Submit Light Reading" as UC1
usecase "View Room Status" as UC2
usecase "Configure Threshold" as UC3
usecase "Receive Alert" as UC4
}
Sensor --> UC1
Admin --> UC2
Admin --> UC3
Admin --> UC4
UC1 ..> UC4: include
@enduml
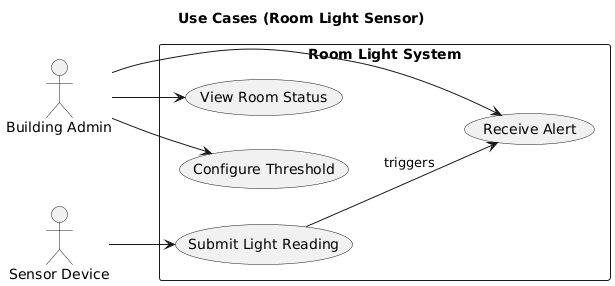
Sequence Diagram (Sensor Sends Event)
@startuml
title Sequence Diagram: Sensor Sends Event
skinparam shadowing false
skinparam participantStyle rectangle
actor "Sensor" as S
participant "API" as API
participant "Validator" as V
database "DB" as DB
participant "Rules Engine" as R
participant "Alert Service" as A
S -> API: POST /events
API -> V: validate(payload)
V --> API: ok
API -> DB: insert LightEvent
API -> R: evaluate(LightEvent)
R -> A: create alert
note right of R
only if threshold violated
end note
API --> S: 202 Accepted
@enduml
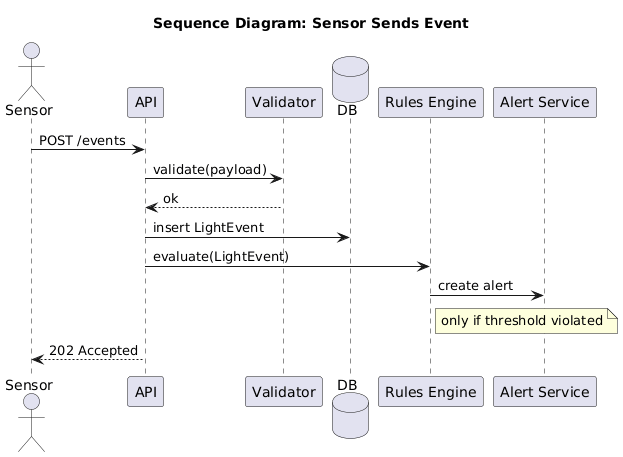
Sequence Diagram (Dashboard Query)
@startuml
title Sequence Diagram: User Views Room
skinparam shadowing false
skinparam participantStyle rectangle
actor "User" as U
participant "Dashboard" as D
participant "API" as API
database "Read Model DB" as RM
U -> D: open room page
D -> API: GET /rooms/CTC-114
API -> RM: query current state
RM --> API: RoomState
API --> D: JSON RoomState
D --> U: render UI
@enduml
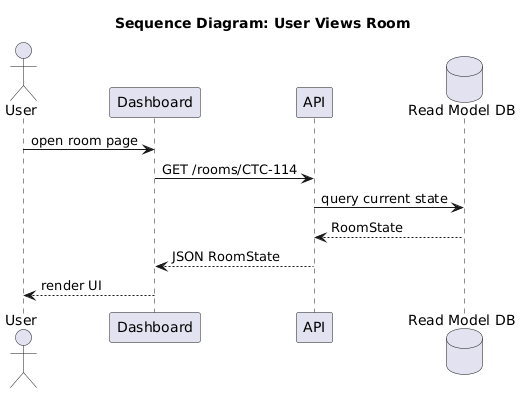
Activity Diagram (Validate and Store)
@startuml
title Activity Diagram: Ingestion Pipeline
skinparam shadowing false
start
:Receive payload;
:Parse JSON;
if (Schema valid?) then (yes)
if (Auth ok?) then (yes)
: Store LightEvent;
: Update RoomState;
if (Threshold violated?) then (yes)
: Create Alert;
else (no)
endif
: Return 202 Accepted;
else (no)
: Return 401 Unauthorized;
endif
else (no)
: Return 400 Bad Request;
endif
stop
@enduml
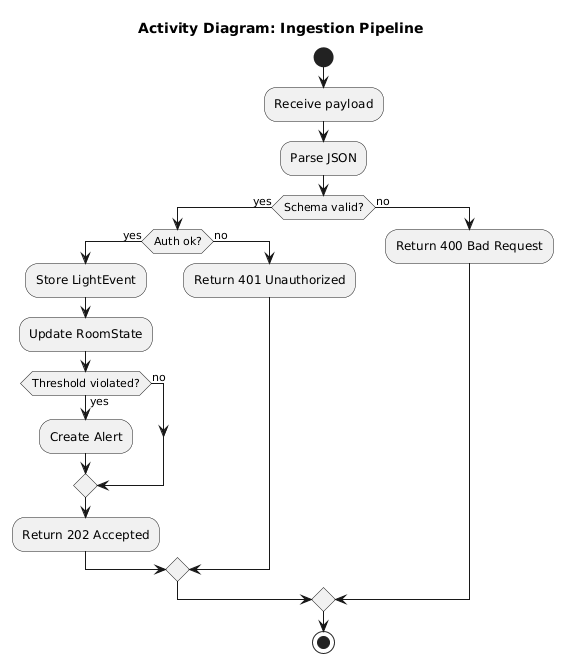
State Machine (Room Light State)
@startuml
title State Machine: Room Light State
skinparam shadowing false
[*] --> Unknown
Unknown --> On: LightEvent state=ON
Unknown --> Off: LightEvent state=OFF
On --> Off: LightEvent state=OFF
Off --> On: LightEvent state=ON
On --> Unknown: no events (timeout)
Off --> Unknown: no events (timeout)
@enduml
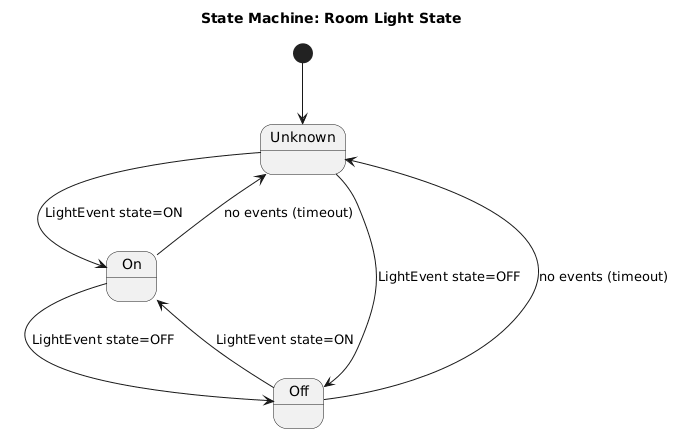
PlantUML Workflow
- Keep
.pumlin the repo (source of truth) - Generate SVG artifacts for slides and READMEs
- One diagram answers one question
- Name files by intent and scope
diagrams/
room_light_layered_component.puml
room_light_client_server_deploy.puml
room_light_monolith_component.puml
room_light_microservices_component.puml
room_light_event_driven_component.puml
room_light_sequence_ingest.puml
room_light_state_machine.puml
Modeling & Diagramming Resources
-
PlantUML: text based UML and architecture diagrams
https://plantuml.com -
PlantUML Online Server: render diagrams instantly
https://sujoyu.github.io/plantuml-previewer/ -
PlantUML GitHub: source code and examples
https://github.com/plantuml/plantuml
UML (Unified Modeling Language)
| Aspect | Description |
|---|---|
| Purpose | Standard visual language to model software structure and behavior |
| Focus | Classes, components, interactions, states, workflows |
| Typical Diagrams | Class, Sequence, Use Case, Activity, State Machine, Component |
| Strength | Widely taught, intuitive, good for communication |
| Limitation | Weak at expressing constraints, versions, and evolution over time |
Source (PDF):
OMG UML 2.5.1 Specification (PDF)
ADL (Architecture Def. Language)
| Aspect | Description |
|---|---|
| Purpose | Formally describe software architecture and its constraints |
| Focus | Components, connectors, configurations, versions |
| Examples | C4 Model, Acme, AADL, Wright, ArchiMate |
| Strength | Precise, analyzable, supports evolution and reasoning |
| Limitation | Less visual, steeper learning curve |
Sources (PDF):
An Introduction to Software Architecture: SEI (PDF)
Quality Attributes
| Attribute | Meaning for Room Light Sensor | Typical Design Lever |
|---|---|---|
| Performance | Ingest throughput and dashboard latency | Read model, caching, batching |
| Scalability | More rooms and devices without rework | Partitioning, async processing |
| Reliability | Survive network loss and device churn | Retry, queues, idempotency |
| Maintainability | Change rules and endpoints safely | Clear boundaries, tests |
| Security | Device identity and request integrity | Auth, signing, least privilege |
| Observability | Debugging and audit trail | Logs, metrics, traces |

Architecture Design Process (Practical)
| Step | Deliverable | Diagram Fit |
|---|---|---|
| 1. Requirements | Key flows and quality goals | Use case, activity |
| 2. Boundaries | Component diagram with externals | Component |
| 3. Runtime | Nodes and message flow | Deployment, sequence |
| 4. Data | Events, schema, storage choices | Class, component |
| 5. Risks | Failure modes and mitigations | Table + notes |
| 6. Document | PlantUML in repo, SVG exported | All |
Case Study: Monolith vs Microservices
| Option | Best When | Main Risk | Trigger to Reconsider |
|---|---|---|---|
| Monolith | Small team, fast iteration | Scaling and release coupling | Teams block each other on deploys |
| Microservices | Clear ownership and independent scaling | Operational overhead | Need independent deploy cadence |
| Event Driven | Stream processing and loose coupling | Schema governance | Many consumers need the same events |
Practice Questions
- Which UML diagram shows runtime nodes and network boundaries?
- Which style has the lowest operational overhead?
- Which behavior diagram shows messages over time?
- In event driven design, what contract must remain stable?
- Which structural diagram best shows service boundaries?
| Question | Answer |
|---|---|
| Nodes + boundaries | Deployment |
| Lowest ops overhead | Monolith |
| Messages over time | Sequence |
| Main stable contract | Event schema |
| Service boundaries | Component |
Takeaway
Today
Data Architecture First
- Motivation: data centric vs software or hardware centric
- Canonical model: nouns, keys, events, room state
- Normalization: stable interfaces across components
- MongoDB design: collections, indexes, validation
- Schema sharing: embedded ↔ backend ↔ frontend
- Frontend storage: caching and offline
- Evolution: versioning and compatibility rules
- Practice questions
Why Data Centric Architecture
- Data is the shared language between components
- Stable meaning lowers integration cost
- Events create audit trail and replay
- Dashboards require consistent definitions
- Scaling is safer when contracts are explicit
Code changes often; data meaning must remain stable.
| Centric | Starts with | Common failure |
|---|---|---|
| Hardware | device constraints | payload semantics drift |
| Software | services and endpoints | DTOs diverge per team |
| Data | canonical model | requires governance |
Canonical Data Model Sits Between Components
One schema defines meaning across firmware, API, database, and UI.
Canonical LightEvent
{
"schema_version": "1.0",
"event_id": "evt-20260211-000123",
"event_type": "LightEvent",
"timestamp": "2026-02-11T08:15:00-08:00",
"room_id": "CTC-114",
"device_id": "sensor-ctc-114-01",
"light_state": "ON",
"lux": 350,
"meta": {
"firmware_version": "0.4.2",
"battery_pct": 92,
"signal_rssi_dbm": -58,
"seq": 9912
}
}
Field Buckets
| Bucket | Fields |
|---|---|
| Context | room_id, device_id |
| Data | lux, light_state |
| Metadata | seq, firmware_version, rssi |
Standard Data Formats (Contract Discipline)
- UUID for stable ids (event_id, alert_id)
- ISO 8601 timestamp with timeroom offset
- Location as stable string key (room_id)
- Enums for states (ON/OFF/UNKNOWN)
- Numbers with units (lux as integer)
- Version in every payload (schema_version)
| Field | Format | Example |
|---|---|---|
| event_id | uuid v4 or prefixed uuid | evt-7f3a... or 7f3a... |
| timestamp | ISO 8601 | 2026-02-11T08:15:00-08:00 |
| room_id | canonical string | CTC-114 |
| device_id | canonical string | sensor-ctc-114-01 |
| light_state | enum | ON |
Data Model First: Start With Nouns and Keys
| Noun | Primary key | Stored in | Why it is stable |
|---|---|---|---|
| Room | room_id | rooms | maps to physical reality |
| Device | device_id | devices | provisioned identity |
| LightEvent | event_id | light_events | audit unit |
| RoomState | room_id | room_state | projection per room |
| Alert | alert_id | alerts | decision evidence |
Normalization: Stable Interfaces Across Components
| Rule | Do | Avoid | Why |
|---|---|---|---|
| One name per concept | room_id everywhere | roomId, room, rid | prevents mapping bugs |
| One type per field | lux integer | "350" string | safe queries and ranges |
| One time standard | timestamp ISO + Mongo Date | local time only | safe ordering and TTL |
| Enums | ON/OFF/UNKNOWN | free text | validation and UI logic |
Where to Validate Schema
- Embedded: build payloads that match the schema
- API: validate JSON schema and return friendly errors
- MongoDB: enforce guardrails with collection validators
- Frontend: validate responses in dev and keep types strict
Rule: validate at the boundary, guardrail at the database.
| Layer | Purpose | Strength |
|---|---|---|
| API validation | reject bad input | best error messages |
| DB validation | prevent drift | last line of defense |
| Type generation | share contract | fewer integration bugs |
{
"collMod": "light_events",
"validator": {
"$jsonSchema": {
"bsonType": "object",
"required": ["_id","event_id","ts","room_id","device_id","light_state"],
"properties": {
"_id": { "bsonType": "string" },
"event_id": { "bsonType": "string" },
"ts": { "bsonType": "date" },
"room_id": { "bsonType": "string" },
"device_id": { "bsonType": "string" },
"light_state": { "enum": ["ON","OFF","UNKNOWN"] },
"lux": { "bsonType": "int", "minimum": 0 }
},
"additionalProperties": false
}
},
"validationAction": "error"
}
MongoDB Validation Notes
- validationAction=error stops bad writes
- validationLevel=moderate enforces on inserts and updates
- additionalProperties=false prevents silent drift
- Keep meta bounded to avoid “junk fields” growth
MongoDB Collections (Options)
| Collection | Purpose | Key fields |
|---|---|---|
| rooms | room metadata | room_id |
| devices | device registry | device_id, room_id |
| light_events | append only events | event_id, room_id, ts |
| room_state | current state projection | room_id |
| alerts | rule outcomes | alert_id, room_id |
How MongoDB Helps a Data Centric Architecture
| MongoDB feature | Use in our project | Benefit |
|---|---|---|
| Document model | store LightEvent as one document | easy ingestion, minimal joins |
| Compound indexes | (room_id, ts desc) | fast recent history queries |
| TTL indexes | optional retention on light_events | automatic cleanup |
| Validators | schema guardrails | data quality over time |
| Change Streams | push updates to UI (optional) | near real time dashboards |
MongoDB Index Suggestions
| Collection | Index | Query it supports |
|---|---|---|
| devices | unique(device_id) | auth and registry lookups |
| devices | (room_id, device_id) | list devices in room |
| light_events | (room_id, ts desc) | recent events per room |
| light_events | (device_id, meta.seq desc) | detect duplicates or gaps |
| alerts | (room_id, created_ts desc) | show recent alerts per room |
| room_state | unique(room_id) | dashboard read by room |
Alerts are Data
- Alerts are derived from events (rules)
- Store alerts to explain system behavior later
- Alerts are part of the audit trail
- Dashboards can show alert history and status
Store and log decisions as data.
{
"alert_id": "alrt-20260211-000045",
"schema_version": "1.0",
"timestamp": "2026-02-11T08:15:02-08:00",
"room_id": "CTC-114",
"device_id": "sensor-ctc-114-01",
"type": "LIGHT_STUCK_ON",
"severity": "WARN",
"explain": {
"rule": "on_duration_minutes > 120",
"value": 131
},
"linked_event_id": "evt-20260211-000123"
}
Alert Alg.: Light Stuck ON
- Goal: detect if a room light stays ON too long
- Input: recent LightEvent stream for a room
- Output: Alert document (with explanation)
| Rule | Example |
|---|---|
| ON duration threshold | ON > 120 minutes |
| Noise filtering | ignore brief toggles < 1 minute |
| Dedup | use event_id + meta.seq |
Pseudo logic
1) fetch recent events for room (sorted by ts)
2) find last OFF -> next ON segment
3) compute duration ON
4) if duration > threshold:
write Alert + link last event
The alert result should be reproducible from stored events.
MongoDB Helps Alerts
- Compound index supports “recent room events”
- Aggregation pipeline can compute durations and windows
- Store alert history for dashboards
- TTL can expire low value alerts if desired
Mongo supports both operational queries and analytic style pipelines.
// recent events for room (fast with index)
db.light_events
.find({ room_id: "CTC-114" })
.sort({ ts: -1 })
.limit(200)
// write alert as a first class document
db.alerts.insertOne({
alert_id: "alrt-20260211-000045",
room_id: "CTC-114",
type: "LIGHT_STUCK_ON",
severity: "WARN"
})
Alert Alg.: Sudden Lux Drop
- Goal: detect potential sensor obstruction or failure
- Input: sliding window of lux values
- Output: Alert with baseline and delta
| Concept | Example |
|---|---|
| baseline | median of last 10 readings |
| drop threshold | delta >= 200 lux |
| state condition | only if light_state=ON |
{
"type": "SUDDEN_LUX_DROP",
"severity": "INFO",
"explain": {
"baseline_median": 340,
"current": 120,
"delta": 220,
"window": 10
}
}
Explain fields make alerts defensible and debuggable.
Schema Across the Stack
- Keep schema files in the repo (
schema/) - Generate validators for backend (JSON schema)
- Generate types for frontend (TypeScript)
- Embed a minimal mapping table or struct
- Every payload includes schema_version
One schema + language bindings
repo/
schema/
light_event/1.0.json
room_state/1.0.json
alert/1.0.json
backend/
validate/
frontend/
types/
embedded/
payload/
Frontend Storage Strategy
- Store RoomState snapshots
- Cache selected room_id
- Optionally cache recent events
- Never invent new field names in UI
{
"schema_version": "1.0",
"room_id": "CTC-114",
"light_state": "ON",
"lux": 350,
"last_event_id": "evt-20260211-000123",
"cached_at": "2026-02-11T08:15:05-08:00"
}
UI stores projections, not the raw firehose.
Evolution Rules (Compatibility)
| Change | Allowed | Rule | Example |
|---|---|---|---|
| Add optional field | Yes | backward compatible | meta.temperature_c |
| Add required field | New version | bump schema_version | require building_id |
| Rename field | Not directly | support both then deprecate | roomId -> room_id |
| Change enum values | Rare | new version + mapping | avoid ON/OFF changes |
Practice Questions
- Why validate schema in both API and MongoDB?
- What makes an id stable and trustworthy?
- Why store events separately from room_state?
- What alert fields make debugging easier?
| Topic | Expected direction |
|---|---|
| Schema validation | boundary + guardrail |
| Identifiers | uuid, canonical keys |
| Events vs state | truth vs projection |
| Indexes | (room_id, ts desc) |
| Alerts | explain fields + links |
Takeaway (MVP 1)
Sprint #3
Deployment Arch. (Draft)
- Room Node: ESP32 + VEML7700 sensor
- Client: Web Dashboard (browser)
- Server: Flask API + MongoDB
- WiFi connects room node to backend
- Internet connects client to backend
- Backend enforces schema and stores events
- Folder Structure
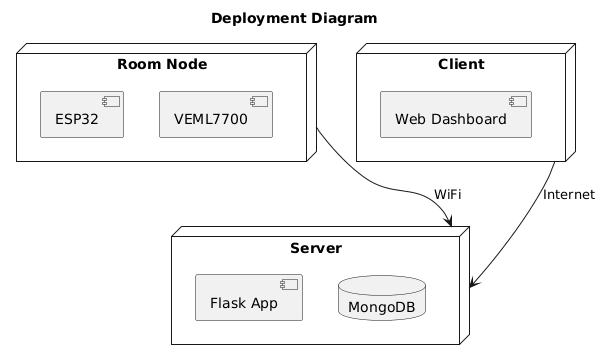
System Overview (Draft)
- Embedded builds canonical LightEvent JSON
- Backend API validates schema + enforces rules
- MongoDB stores events, state, alerts
- Frontend reads RoomState projection
- Admin manages rooms, devices, users
- All components share the same schema contract
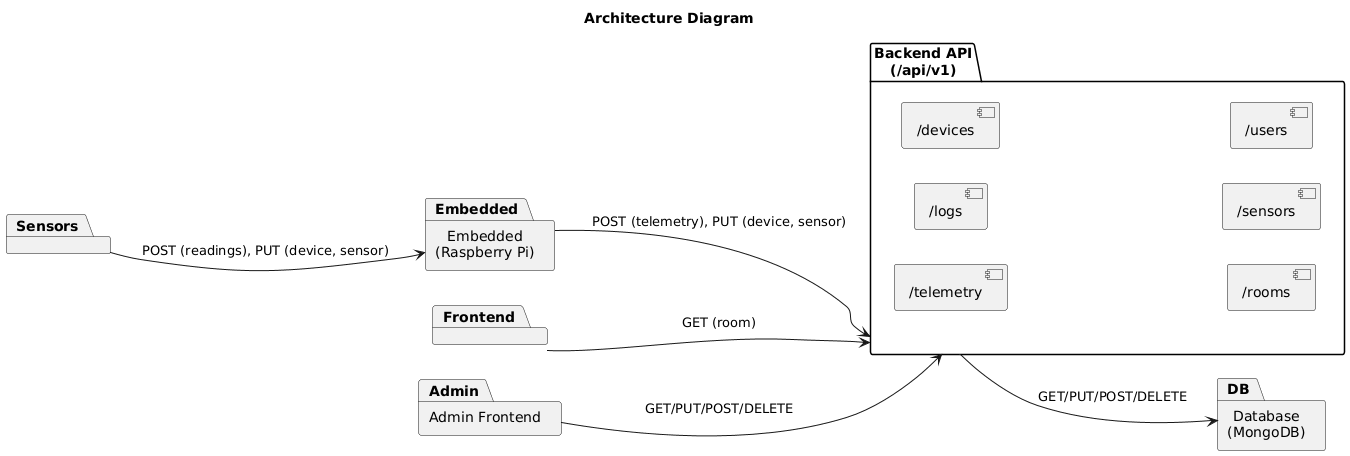
Schema: rooms
{
"$jsonSchema": {
"bsonType": "object",
"required": ["_id","room_id","building","room_number","created_at","updated_at"],
"properties": {
"_id": {"bsonType":"string"},
"room_id": {"bsonType":"string"},
"building": {"bsonType":"string"},
"room_number": {"bsonType":"string"},
"floor": {"bsonType":["int","long"]},
"tags": {"bsonType":"array","items":{"bsonType":"string"}},
"created_at": {"bsonType":"date"},
"updated_at": {"bsonType":"date"}
},
"additionalProperties": false
}
}
Schema: devices
{
"$jsonSchema": {
"bsonType": "object",
"required": ["_id","device_id","room_id","device_type","status","provisioned_at"],
"properties": {
"_id": {"bsonType":"string"},
"device_id": {"bsonType":"string"},
"room_id": {"bsonType":"string"},
"device_type": {"enum":["light_sensor"]},
"status": {"enum":["ACTIVE","DISABLED","RETIRED"]},
"firmware_version": {"bsonType":"string"},
"provisioned_at": {"bsonType":"date"},
"last_seen_at": {"bsonType":"date"}
},
"additionalProperties": false
}
}
Schema: light_events
{
"$jsonSchema": {
"bsonType": "object",
"required": ["_id","event_id","schema_version","ts","room_id","device_id","light_state"],
"properties": {
"_id": {"bsonType":"string"},
"event_id": {"bsonType":"string"},
"schema_version": {"bsonType":"string"},
"ts": {"bsonType":"date"},
"room_id": {"bsonType":"string"},
"device_id": {"bsonType":"string"},
"light_state": {"enum":["ON","OFF","UNKNOWN"]},
"lux": {"bsonType":["int","long"],"minimum":0},
"meta": {
"bsonType":"object",
"properties": {
"seq": {"bsonType":["int","long"],"minimum":0},
"battery_pct": {"bsonType":["int","long"],"minimum":0,"maximum":100}
},
"additionalProperties": false
}
},
"additionalProperties": false
}
}Schema: room_state
{
"$jsonSchema": {
"bsonType": "object",
"required": ["_id","room_id","light_state","last_event_id","last_ts","updated_at"],
"properties": {
"_id": {"bsonType":"string"},
"room_id": {"bsonType":"string"},
"light_state": {"enum":["ON","OFF","UNKNOWN"]},
"lux": {"bsonType":["int","long"],"minimum":0},
"last_event_id": {"bsonType":"string"},
"last_ts": {"bsonType":"date"},
"updated_at": {"bsonType":"date"}
},
"additionalProperties": false
}
}
Schema: alerts
{
"$jsonSchema": {
"bsonType": "object",
"required": ["_id","alert_id","ts","room_id","type","severity","linked_event_id"],
"properties": {
"_id": {"bsonType":"string"},
"alert_id": {"bsonType":"string"},
"ts": {"bsonType":"date"},
"room_id": {"bsonType":"string"},
"device_id": {"bsonType":"string"},
"type": {"enum":["LIGHT_STUCK_ON","SUDDEN_LUX_DROP","DEVICE_OFFLINE"]},
"severity": {"enum":["INFO","WARN","CRITICAL"]},
"linked_event_id": {"bsonType":"string"},
"explain": {"bsonType":"object"}
},
"additionalProperties": false
}
}
Module 5
Architectural Decisions: Display Resolution
- Display hardware shapes what you can show
- Resolution affects layout, density, and readability
- Visualization choices depend on pixels and size
Same data
Different screens
Different decisions
Today
- Phone vs embedded vs desktop constraints
- Browser as a display runtime
- Flexbox layout as a response strategy
- Visualization tradeoffs (tables vs charts)
- Practical rules: density, typography, interaction
| Decision | Why it matters |
|---|---|
| Target resolution | controls information density |
| Input method | mouse vs touch vs none |
| Rendering runtime | browser vs native UI |
Concept: Hardware Constraints Shape the Data Story
Key Terms
- Resolution: pixels available (e.g., 1920×1080)
- Pixel density: how packed pixels are (PPI)
- Viewport: usable area in browser or app
- Density: how much data you show at once
More pixels ≠ better UI
More pixels = more options
But you still must choose:
- font size
- spacing
- what to hide
- what to summarize
Three Display Targets (Architecture Reality)
| Target | Typical constraint | UI consequence | Visualization bias |
|---|---|---|---|
| Phone | small viewport + touch | stacked layout, bigger tap rooms | summaries, short tables, small multiples |
| Embedded | fixed screen + limited compute | few screens, minimal interaction | single KPI, status, trend sparkline |
| Desktop | large viewport + mouse/keyboard | multi panel dashboards | wide tables, comparisons, drill downs |
Phone (Small Viewport)
- Show fewer columns
- Prefer cards over wide tables
- Summarize first, drill down second
- Touch friendly spacing is non negotiable
| Good | Risk |
|---|---|
| top metrics + list | hidden context |
| filters as chips | filter overload |
Phone pattern:
1) KPI summary row
2) short list (top N)
3) tap → details view
Embedded (Fixed Screen)
- Fixed resolution means fixed layout
- Compute limits restrict fancy charts
- Use stable fonts and high contrast
- Prefer simple visuals: status and trend
| Good | Risk |
|---|---|
| one screen status | no exploration |
| large readable text | low data density |
Embedded pattern:
- ONE KPI
- ONE status color
- ONE small trend (sparkline)
- ONE timestamp ("last updated")
Desktop (Wide View)
- More columns become usable
- Side by side comparisons are natural
- Filters can remain visible
- Keyboard helps data entry and search
| Good | Risk |
|---|---|
| dense tables | visual clutter |
| multi panel view | too many widgets |
Desktop pattern:
Left: filters
Center: table
Right: chart summary
Bottom: details / logs
Browser as a Display Runtime
- Same URL can serve multiple screen classes
- Viewport changes during use (resize)
- Device pixel ratio affects rendering
- Responsive layout is an architectural choice
| Browser reality | Design response |
|---|---|
| unknown viewport | breakpoints |
| variable input | keyboard + touch safe UI |
| network variability | loading states + caching |
Flexbox (Responsive Layout Tool)
- Natural for rows that wrap into columns
- Good for cards, KPIs, toolbars
- Supports reflow without rewriting HTML
- Pairs well with breakpoints
/* Example idea: cards reflow */
.dashboard {
display: flex;
flex-wrap: wrap;
gap: 12px;
}
.card {
flex: 1 1 320px; /* grows, shrinks, min width */
}
Visualization Choice Depends on Resolution
- Tables: precise values, many rows
- Charts: trends, comparisons, shape
- Small screens push you toward summaries
- Large screens allow both at once
| Screen | Prefer first | Then add |
|---|---|---|
| Phone | chart summary / KPIs | short table (top N) |
| Embedded | KPI + status | sparkline |
| Desktop | table + filters | chart panel |
Density Rules (Practical)
| Rule | Why | Example |
|---|---|---|
| Do not squeeze text | readability collapses first | reduce columns instead |
| Summarize before detail | small screens need a story | KPI row → drill down |
| Use progressive disclosure | prevents clutter | details panel / modal |
| Make interaction match input | touch needs bigger targets | buttons not tiny links |
Same Dataset, Three Layout Architectures
Architecture Questions to Ask
- What is the smallest supported viewport?
- What must be visible without scrolling?
- What interaction is expected (touch, mouse, none)?
- What is the largest safe table width?
- What is the fallback when charts do not fit?
| Decision | Locks you in |
|---|---|
| Fixed layout | embedded only assumptions |
| Responsive layout | more testing across devices |
| Chart heavy UI | rendering cost and legibility risk |
Takeaway
- Display resolution is a hardware constraint
- Hardware constraints drive UI architecture
- UI architecture shapes data visualization
- Flexbox helps reflow the same content
Treat display as architecture, not styling.
Hardware → Layout → Visualization
If you ignore hardware,
your dashboard will fail in production.
Module 6
Legal Constraints for Industry 4.0 Applications
- Regulatory requirements that shape architecture
- Technical controls tied to legal obligations
- User stories that operationalize compliance
How Legal Requirements Change Over Time
- “Reasonable security” evolves with technology
- Industry standards influence legal expectations
- Older protocols become harder to defend
- Patchability determines long-term compliance
What was acceptable security in 2012 may not be acceptable in 2026.
Example: BLE 4.0 → BLE 4.2
| Year | Bluetooth Version | Security Impact | Legal Risk Implication |
|---|---|---|---|
| 2010 | BLE 4.0 | Basic pairing; limited privacy protections | Considered acceptable at the time |
| 2014 | BLE 4.2 | Improved LE Secure Connections (stronger encryption) | New baseline for “reasonable security” |
How Legal Updates Impact Software Updates
- Regulatory guidance evolves (privacy, security expectations)
- New vulnerabilities redefine “reasonable security”
- Industry standards shift (e.g., BLE security, TLS versions)
- Legal exposure increases if systems cannot adapt
- FOTA enables compliance corrections post-deployment
- NFR (security, logging, performance) must support audit defensibility
- Release checklists must include compliance verification
How do legal requirements impact backlog priority?
- Legal risk can override feature urgency
- Security updates may become mandatory
- Regulatory deadlines shift sprint focus
- Unpatchable systems increase liability exposure
When laws or standards evolve, backlog ordering must change. Compliance-driven work can move ahead of features.

Feature First Thinking
- Features drive visible progress
- Bug fixes react to issues
- Legal and security treated as overhead
- Firmware update mechanism delayed
This order increases long-term legal and operational risk.
Initial Backlog Priority
Legal Risk Forces Reordering
- Privacy violations trigger regulatory exposure
- Security weaknesses increase negligence risk
- Unpatchable devices amplify liability
Legal requirements are structural, not optional.
Backlog Reordered
Legal Requirements Depend on Region
- Laws apply based on where the product is sold or deployed
- Cloud location can affect jurisdiction
- User location may trigger privacy obligations
- Security expectations differ by region
A room light sensor deployed in California, Germany, or Japan may face different regulatory obligations.
Top Global Legal Frameworks
| Region | Key Regulation | Impact on IoT App |
|---|---|---|
| European Union | GDPR (General Data Protection Regulation) | Strong privacy rights, deletion, data minimization |
| United States (California) | CCPA / CPRA | Access and deletion rights, transparency obligations |
| United States (Federal) | FCC + FTC | RF compliance and reasonable security expectations |
| United Kingdom | UK GDPR + IoT Security Regulations | Secure-by-design and credential requirements |
FOTA Enables Legal Compliance
- Security patches require remote updates
- Legal defects must be correctable after deployment
- Patch capability reduces long-term exposure
Without secure update capability, compliance cannot be maintained.
Backlog Reordered Again
Non Functional Requirements (NFR)
- Security
- Performance
- Availability
- Reliability
Legal defensibility depends on security controls and logging.
Stabilized Backlog Order
Mature Engineering Order
- 1. FOTA (update capability)
- 2. Legal compliance
- 3. NFR foundation
- 4. Feature expansion
You cannot promise compliance without patchability.
Final Defensible Priority
Core acronyms (part 1)
| Acronym | Definition | Why it matters in a room light sensor IoT app |
|---|---|---|
| FCC | Federal Communications Commission | If your sensor uses WiFi/BLE, radio compliance and interference constraints matter |
| FTC | Federal Trade Commission | Security and privacy claims must match what your app actually does |
| NIST | National Institute of Standards and Technology | Common reference for reasonable security controls and evidence |
| CCPA | California Consumer Privacy Act | If data can relate to a person/household, rights to access and delete may apply |
| HIPAA | Health Insurance Portability and Accountability Act | Applies if light sensor data is tied to patient identity in healthcare contexts |
Core acronyms (part 2)
| Acronym | Definition | Why it matters in a room light sensor IoT app |
|---|---|---|
| CSF | Cybersecurity Framework (NIST CSF) | A simple structure for controls: Govern/Identify/Protect/Detect/Respond/Recover |
| SSDF | Secure Software Development Framework (NIST) | Defines secure build and release practices that support legal defensibility |
| RBAC | Role Based Access Control | Limits who can view room level readings or change automation settings |
| TLS | Transport Layer Security | Encrypts API traffic from sensor gateway to backend |
| TTL | Time To Live (data expiry) | Enforces retention policies by deleting old sensor readings automatically |
Core acronyms (part 3)
| Acronym | Definition | Why it matters in a room light sensor IoT app |
|---|---|---|
| API | Application Programming Interface | Backend endpoints must be authenticated, logged, and rate limited |
| SBOM | Software Bill of Materials | Supports supply chain accountability for firmware and dependencies |
| CVE | Common Vulnerabilities and Exposures | Known issues in dependencies can affect negligence posture |
| NTP | Network Time Protocol | Consistent timestamps make logs credible during investigations |
| PII | Personally Identifiable Information | Room + timestamp + device owner can become personal data in context |
Additional Legal & Compliance Acronyms
| Acronym | Definition | Room Light Sensor IoT Example |
|---|---|---|
| EMI | Electromagnetic Interference | Sensor radio must not disrupt nearby medical or lab equipment. |
| EMC | Electromagnetic Compatibility | Device must tolerate interference while operating correctly in Room 114. |
| UL | Underwriters Laboratories (Safety Certification) | Power supply and enclosure must meet electrical safety expectations. |
| SLA | Service Level Agreement | Contract may require 99% uptime for building lighting controls. |
| DPIA | Data Protection Impact Assessment | Assessment may be required if occupancy patterns are inferred from lighting data. |
| IR | Incident Response | Defined process if unauthorized dashboard access occurs. |
| MTTR | Mean Time To Recovery | Metric for how quickly lighting service is restored after firmware failure. |
| MTBF | Mean Time Between Failures | Hardware reliability metric for deployed room sensors. |
| FOTA | Firmware Over The Air | Secure remote updates to room light sensors with rollback capability. |
| ISO | International Organization for Standardization | ISO 27001-style controls may influence enterprise deployment requirements. |
Legal requirement types
- Wireless compliance (FCC)
- Consumer protection (FTC)
- Privacy rights (CCPA)
- Building energy controls (Title 24)
- Reasonable security (NIST as reference)
Room light sensor IoT examples
- WiFi module certification + antenna config recorded per hardware revision
- Dashboard claims match measured sampling interval and documented accuracy tests
- Deletion workflow removes Room readings for a device_id and logs the request
- Acceptance test checklist proves daylighting behavior meets configured requirements
- Control matrix maps TLS, RBAC, signed updates to CSF outcomes with evidence links
Data minimization requirement
- Collect only what is needed for the feature
- Separate identifiers from sensor readings
- Implement retention with TTL, not manual cleanup
Room light sensor IoT example
- Payload stays minimal: {room_id, light_state, timestamp}
- device_id lives in a separate registry table with restricted access
- Raw readings expire after 30 days; monthly aggregates retained longer
Secure update requirement
- Updates must be authenticated and integrity protected
- Failure handling must be safe and recoverable
- Update actions must be auditable
Room light sensor IoT example
- Firmware images are signed; device verifies signature before install
- Rollback to last known good version if boot fails or toggling becomes unstable
- Update log includes device_id, version, timestamp, result (success/failure)
Why this belongs in system design
- Industry 4.0 connects sensors, networks, and decisions
- Legal risk is evaluated through foreseeable harm and reasonable practice
- Privacy, safety, and reliability overlap in deployed systems
- Documentation becomes evidence of due care
Room light sensor example
- Occupancy inference from light patterns (privacy)
- Automation turns lights on/off (safety and usability)
- Firmware updates control behavior (security)
- Dashboard shows room status (access control)
Legal outcomes you plan for
- Regulatory enforcement (fines, injunctions, recalls)
- Civil lawsuits (negligence, product liability)
- Contract disputes (SLA, warranties)
- Incident response and breach notification
Engineering response
- Treat compliance as non functional requirements
- Define controls and evidence for each requirement
- Use standards like NIST to reduce ambiguity
Regulatory authority mapping (high level)
| Area | Federal (examples) | California (examples) | Room light sensor notes |
|---|---|---|---|
| Wireless / RF | FCC | Deployment policies | WiFi/BLE modules and interference constraints |
| Consumer protection | FTC | State consumer law | No deceptive accuracy/security claims in dashboard or marketing |
| Privacy | Sector laws (context) | CCPA | Room_id can become personal in smart home or workplace contexts |
| Healthcare | HIPAA; FDA (context) | State privacy overlays | If deployed in clinics, tie to patient info triggers stronger rules |
| Building energy | Federal programs (context) | Title 24 | If used for lighting controls, Title 24 acceptance tests matter |
Legal sources by technical layer
| Layer | What law cares about | Room light sensor example evidence |
|---|---|---|
| Hardware | interference, safety, reliability | module cert refs; HW revision; calibration notes |
| Firmware | update integrity, safe defaults | signed releases; rollback plan; update logs per device_id |
| Backend | security, access control, logging | RBAC design; auth logs; rate limiting settings |
| Data | privacy, retention, breach readiness | data inventory; TTL policy; deletion workflow logs |
| UI | transparency, accurate claims | screenshots of notices; settings; claim text version history |
| Ops | response readiness, accountability | incident runbook; postmortem; alert rules |
FCC Part 15 (wireless devices)
- Emissions constraints reduce interference
- Testing and labeling expectations
- Module choices affect certification scope
Room light sensor example
- Sensor node uses WiFi to send {room_id, light_state, timestamp}
- Pick certified module; track antenna config per HW revision
- Store test evidence with release artifacts
Deployment safety expectations
- Lighting affects visibility and hazard reduction
- Calibration affects outcomes
- Environment affects sensor accuracy
Room light sensor example
- Define safe fallback: if sensor is uncertain, do not oscillate lights
- Commissioning checklist per room
- Record calibration metadata and thresholds
Device identity and traceability
- Traceability supports recalls and incident response
- Identifiers can become personal data in context
Room light sensor example
- device_id identifies a unit installed in Room 114
- Separate device registry from readings table
- Inventory exports support incident scoping
Supply chain risk
- Counterfeit or insecure modules increase exposure
- Third party firmware can carry vulnerabilities
Room light sensor example
- Maintain BOM and firmware dependency list
- Track CVEs for WiFi stack / crypto library
- Store supplier evidence in repo or release folder
California connected device security expectations (practical)
- Reasonable security features expected for connected devices sold in CA
- Credential hygiene is a core theme
Room light sensor example
- No shared default password for device admin pages
- Secure provisioning (unique creds)
- Signed firmware updates
User Story: FCC evidence bundle
User Story: As a release manager, I need to attach RF compliance evidence to each hardware release so we can support certification and audit requests.
Room Light Sensor Example: For the Room 114 sensor batch, the release folder records module certification id and antenna type used.
Acceptance Criteria
- Release folder includes module certification references
- HW revision and antenna config recorded
- Test report reference stored
- Label artwork stored with version history
User Story: Calibration traceability
User Story: As a deployment engineer, I need a calibration and acceptance workflow so the installed system meets safety expectations in real environments.
Room Light Sensor Example: When Room 114 is commissioned, store threshold values and operator id, then schedule recalibration after HVAC season change.
Acceptance Criteria
- Calibration procedure documented and versioned
- Acceptance checklist completed per site
- Calibration metadata stored (timestamp, operator, device_id)
- Recalibration schedule defined
User Story: Secure provisioning
User Story: As a security engineer, I need secure device provisioning so devices cannot be deployed with shared credentials.
Room Light Sensor Example: Provision Room 114 device with unique token; provisioning log records device_id and timestamp, not the secret.
Acceptance Criteria
- Unique credentials per device or per tenant
- Provisioning uses a secure channel
- Credentials are not printed in plaintext logs
- Provisioning events are auditable
User Story: Hardware revision mapping
User Story: As an incident responder, I need to map incidents to hardware revisions so we can scope impact and recalls accurately.
Room Light Sensor Example: If a sensor batch in Room 114–120 misreports, filter by HW revision and deployment date to scope impact.
Acceptance Criteria
- Device inventory includes HW revision, FW version, serial
- Lookup is fast and exportable
- Inventory changes are logged
- Recall scope can be generated by filters
User Story: Supply chain evidence
User Story: As a compliance owner, I need supplier and component evidence so we can defend reasonable procurement practices.
Room Light Sensor Example: For each room sensor, store BOM snapshot and confirm no known CVE in the WiFi SDK version.
Acceptance Criteria
- BOM includes vendor + part identifiers
- Supplier attestations stored
- Component firmware versions tracked
- Known vulnerability review logged per release
Product liability and duty of care
- Foreseeable harm drives duty of care
- Defective control logic can create liability
- Safe defaults and clear limitations matter
Room light sensor example
- Avoid oscillation: debounce and hysteresis for light_state
- Conservative fallback on missing readings
- Log all automated toggles with reason codes
FTC consumer protection (claims)
- No deceptive accuracy, security, or savings claims
- Statements must match real behavior
Room light sensor example
- If dashboard says 'real time', define sampling interval
- If claim 'secure', document controls (TLS, signed updates)
- If claim 'saves energy', keep measurement method
Secure update pipeline
- Patchability reduces negligence risk
- Unsafe updates increase exposure
Room light sensor example
- Signed firmware releases stored per version
- Rollback if new firmware causes rapid toggling
- Telemetry: update success rate per device_id
Logging and audit trails
- Logs support dispute resolution and incident response
- Time and integrity matter
Room light sensor example
- Use NTP on gateway for consistent timestamps
- Log changes to thresholds and automations
- Protect logs with access controls
Access control and authentication
- Weak auth is often framed as unreasonable security
- Shared credentials are risky
Room light sensor example
- RBAC: faculty vs building ops vs student view
- Separate 'view sensor state' from 'change automation' rights
- Rate limit login attempts
User Story: Signed firmware updates
User Story: As a security engineer, I need firmware updates to be signed and verified so unauthorized code cannot run on devices.
Room Light Sensor Example: When Room 114 sensor updates to v1.3.2, the device logs signature verification success and stores the previous version for rollback.
Acceptance Criteria
- Firmware images are signed during build
- Device verifies signature before install
- Failed verification prevents install
- Update events are logged with device_id and version
User Story: Rollback and safe recovery
User Story: As an operations engineer, I need rollback support so devices can recover from failed updates without unsafe behavior.
Room Light Sensor Example: If Room 114 begins toggling rapidly after update, safe mode holds lights steady and rolls back to the last good version.
Acceptance Criteria
- Device keeps last known good version
- Automatic rollback after repeated boot failure
- Safe mode uses conservative defaults
- Rollback is recorded in audit logs
User Story: Accuracy claim evidence
User Story: As a product owner, I need test evidence for any accuracy claim so we can defend statements under consumer protection scrutiny.
Room Light Sensor Example: If the app claims 95% correct light_state detection, store the test set from rooms with different daylight conditions.
Acceptance Criteria
- Accuracy tests defined with dataset and conditions
- Results stored and versioned
- Claim text references the tested condition scope
- Regression tests run for each release
User Story: Default safe state
User Story: As a safety reviewer, I need a documented default safe state so the system behaves predictably when sensor input is missing or inconsistent.
Room Light Sensor Example: If Room 114 sensor stops reporting for 10 minutes, backend sets status to 'unknown' and prevents automated toggles.
Acceptance Criteria
- Safe state defined per deployment domain
- Validation checks implemented
- Fallback behavior tested
- Safe state events logged with reason codes
User Story: Dashboard access control
User Story: As an administrator, I need role based dashboard access so only authorized users can view or change settings.
Room Light Sensor Example: commonly can view aggregated building statistics, but only building ops can change Room 114 thresholds.
Acceptance Criteria
- Roles defined (viewer, operator, admin)
- Actions require proper role
- All admin changes are audit logged
- Account lifecycle supports disable/remove
User Story: Rate limiting and abuse protection
User Story: As a backend engineer, I need rate limiting so the system resists brute force and denial of service scenarios.
Room Light Sensor Example: If an attacker spams /api/rooms/114/state, throttle requests and alert ops.
Acceptance Criteria
- API endpoints have per identity limits
- Lockout policy for repeated failures
- Alerts for anomalous traffic
- Logs include source metadata for investigation
User Story: Operational logging schema
User Story: As an incident responder, I need a consistent logging schema so we can reconstruct timelines and root causes.
Room Light Sensor Example: A single incident report can show: sensor reading spikes → backend decision → UI toggle → operator override.
Acceptance Criteria
- Event types standardized across components
- Timestamps are consistent and timeroom safe
- Log retention aligns with policy
- Export supports incident review
When sensor data becomes personal data
- Link to person/household via account or device owner
- Infer behavior via patterns (occupancy and schedules)
- Combine with identifiers (device_id, room_id)
Room light sensor example
- Room 114 + timestamp can reveal when a lab is occupied
- Device registry ties device_id to a building owner
- Dashboard exports can become sensitive without controls
California privacy thinking (CCPA style)
- Transparency about collection and use
- Rights often require retrieval and deletion workflows
- Retention should match purpose
Room light sensor example
- Document what fields are stored and why
- Support deletion by device_id or deployment id
- Use TTL to enforce retention in DB
Retention and deletion must be implemented
- Retention is not just policy text
- Backups and archives need rules too
Room light sensor example
- Keep raw readings 30 days, aggregate monthly metrics for 12 months
- Backups expire on schedule
- Deletion requests are logged and confirmed
Breach readiness
- Incident response steps must be defined
- Preserve evidence and timelines
Room light sensor example
- Alert on unusual dashboard access
- Preserve logs for investigation
- Runbook includes who to notify and what to capture
User Story: Data inventory
User Story: As a privacy owner, I need a data inventory so we know what we collect, where we store it, and why.
Room Light Sensor Example: Inventory explicitly lists: room_id, light_state, timestamp, device_id, and whether each is needed for function.
Acceptance Criteria
- Inventory lists fields, purpose, storage location, retention
- Updated when schema changes
- Review occurs each sprint or release
- Inventory is accessible to engineering and compliance
User Story: Deletion by device_id
User Story: As a user, I want to request deletion of data associated with my device so my data is not retained beyond purpose.
Room Light Sensor Example: Deleting Room 114 device data removes raw readings and severs links from device registry while keeping aggregated anonymous stats.
Acceptance Criteria
- Deletion endpoint exists with authentication
- All relevant tables are covered
- Deletion is logged with a request id
- User receives confirmation or status
User Story: Retention TTL policy
User Story: As a system owner, I need automatic TTL deletion so retention is enforced consistently without manual steps.
Room Light Sensor Example: A nightly job expires sensor readings older than 30 days for each room, with a report of deleted counts.
Acceptance Criteria
- TTL enforced at DB or scheduled job level
- TTL applies to raw readings and logs per policy
- Exceptions documented (e.g., incident hold)
- Deletion metrics are monitored
User Story: Data minimization mode
User Story: As a product owner, I need a privacy preserving mode so deployments can reduce risk by collecting fewer identifiers.
Room Light Sensor Example: In privacy mode, payload omits device_id at the API boundary and uses a short lived token instead.
Acceptance Criteria
- Config toggles remove/avoid unnecessary fields
- Analytics still possible via aggregation
- Change is documented and tested
- Default prefers minimal collection
User Story: Access auditing
User Story: As a compliance owner, I need to audit who accessed sensitive data so we can investigate incidents and support accountability.
Room Light Sensor Example: Every request to /api/rooms/114/history is logged with user id and purpose tag.
Acceptance Criteria
- Read access to sensitive endpoints is logged
- Logs include actor, action, target, timestamp
- Alerts for unusual access patterns
- Reports exportable for review
User Story: Breach runbook
User Story: As an incident commander, I need a breach runbook so the team can respond quickly and preserve evidence.
Room Light Sensor Example: If unauthorized access occurs, the runbook captures affected rooms, timeframe, and exported datasets.
Acceptance Criteria
- Runbook defines triage steps and roles
- Evidence collection steps included
- Communication templates prepared
- Post incident review process defined
User Story: Data sharing controls
User Story: As a security reviewer, I need controls for third party data sharing so we do not leak more than necessary.
Room Light Sensor Example: If exporting to a building analytics tool, share only aggregated daily counts, not per minute room_id history.
Acceptance Criteria
- Outbound data flows documented
- Field level minimization enforced
- Vendor access reviewed periodically
- Contracts and policies referenced in docs
How NIST relates to legal requirements
- Regulators and courts ask about reasonable security
- NIST provides widely accepted frameworks and controls
- Mapping to NIST helps show due care
Room light sensor example
- Use CSF to structure controls per sprint
- Use SSDF to justify secure build and release steps
- Store evidence for each control in release folder
NIST CSF functions
- Govern
- Identify
- Protect
- Detect
- Respond
- Recover
Room light sensor mapping idea
- Protect: TLS + signed updates
- Detect: alert on anomaly access
- Respond: incident runbook and postmortem
NIST SSDF (secure development)
- Integrate security into development lifecycle
- Vulnerability handling and patch discipline
- Supply chain awareness (dependencies and firmware)
Room light sensor example
- Dependency scanning before release
- Security checklist in CI pipeline
- SBOM stored with firmware builds
NIST 800-53 style control families (simplified)
- Access control
- Audit and accountability
- Incident response
- System integrity
Room light sensor example
- RBAC for dashboard
- Audit logs for room history access
- Incident runbook for compromise
- Signed firmware and rollback
User Story: NIST control matrix
User Story: As a compliance owner, I need a control matrix mapping legal expectations to NIST outcomes so we can demonstrate reasonable security.
Room Light Sensor Example: Matrix row: 'reasonable security' → CSF Protect → TLS everywhere → config + penetration test notes.
Acceptance Criteria
- Matrix includes requirement, NIST reference, implementation, evidence
- Matrix updated on major feature changes
- Evidence links point to logs/tests/docs
- Matrix reviewed at release time
User Story: CSF based sprint review
User Story: As a project lead, I want to review CSF outcomes each sprint so security controls remain visible and measurable.
Room Light Sensor Example: Sprint demo: show rate limit logs for room endpoints and a dashboard of failed auth attempts.
Acceptance Criteria
- Sprint checklist includes at least one CSF outcome
- Demo includes evidence (logs/tests)
- Backlog includes a security task each sprint
- Risks tracked and updated
User Story: Secure release checklist (SSDF aligned)
User Story: As a release manager, I need a secure release checklist aligned with NIST SSDF so releases are consistent and defensible.
Room Light Sensor Example: Release v1.4 includes: signed firmware, TLS config check, TTL job test, rollback test evidence.
Acceptance Criteria
- Checklist covers signing, scanning, tests, rollback
- Checklist stored with release artifacts
- Exceptions require written justification
- Checklist completion is auditable
Healthcare domain (high stakes)
- HIPAA if tied to patient identity
- Higher expectations for audit and access controls
- Validation and change control are emphasized
Room light sensor example
- In a clinic, room lighting linked to patient scheduling becomes sensitive
- Audit every access to room history
- Restrict who can change automation rules
Automotive domain (safety critical)
- High expectation for traceability
- Failures can trigger recalls and liability
Room light sensor analogy
- Treat control decisions like safety decisions: validate inputs, log outputs, fail safe on uncertainty
Retail domain (privacy centric)
- Analytics can become surveillance
- Transparency and minimization reduce risk
Room light sensor example
- If used to infer shopper behavior by room, aggregate data and limit retention
- Make analytics optional and access controlled
Industrial domain (workplace safety)
- Safety and reliability dominate
- Maintenance must be operationalized
Room light sensor example
- In labs, avoid flicker hazards; require calibration checks
- Alarm on sensor anomalies and degraded performance
Smart buildings / campus (California focus)
- Title 24 energy and control requirements
- Occupancy signals can be sensitive
Room light sensor example
- Acceptance testing for lighting controls and daylighting rooms
- Privacy by design for room occupancy inference
User Story: Hospital audit logging
User Story: As a hospital security officer, I need audit logs for all configuration changes so we can investigate incidents and meet accountability expectations.
Room Light Sensor Example: Changing Room 114 daylight threshold requires admin role and produces an audit log entry.
Acceptance Criteria
- All config changes are logged with actor and timestamp
- Logs are access controlled
- Logs retained per policy
- Reports exportable for review
User Story: Safety focused fail safe mode
User Story: As a safety reviewer, I need a fail safe mode so inconsistent readings do not create unsafe lighting behavior.
Room Light Sensor Example: If lux value fluctuates near threshold, debounce prevents rapid toggling in Room 114.
Acceptance Criteria
- Inconsistent readings trigger conservative default behavior
- Override available where appropriate
- Fail safe events logged with reason codes
- Fail safe behavior tested with documented cases
User Story: Privacy preserving analytics
User Story: As a building operator, I need privacy preserving analytics so we can report trends without exposing room level behavior.
Room Light Sensor Example: Weekly report shows building-wide counts rather than Room 114 minute-by-minute history.
Acceptance Criteria
- Only aggregated metrics are stored long term
- Raw per room history retention is short
- Access to raw history is restricted
- Exports redact identifiers by default
Project: payload and identifiers
- room_id can be sensitive in context
- device_id should be handled carefully
- timestamps can infer schedules
Concrete implementation in the app
- Use minimal payload: {room_id, light_state, timestamp}
- Store device_id in a separate registry table
- Add TTL retention policy for readings
Project: compliance as user stories
- Convert obligations into backlog items
- Attach evidence artifacts to each story
Evidence bundle examples
- Data flow diagram
- Control matrix (legal → NIST → evidence)
- Signed release + update logs
- Deletion workflow + TTL report
- Incident runbook skeleton
What to remember
- Map requirements to hardware, software, and data layers
- Use NIST to explain reasonable security and controls
- Evidence is part of the release: tests, logs, diagrams
Module 6
Legal Constraints for Software Updates
- Scope of legal requirements (Federal, State, Sector-Specific)
- How regulations translate into update obligations
- Risk-based patch management expectations
- Evidence and audit readiness as part of release
- Defined accountability for monitoring updates
HIPAA Security Rule (United States)
- Applies nationwide to covered entities & business associates
- Protect electronic health information
- Implement reasonable safeguards
- Ongoing risk management required
- Address known vulnerabilities
- Monitoring Security officer & IT security team
Software Update Implications
- Patch known vulnerabilities promptly
- Maintain documented patch policy
- Log and audit update activity
- Validate updates before deployment

FDA Cybersecurity (United States)
- Applies nationwide to regulated medical device manufacturers
- Secure design lifecycle required
- Postmarket vulnerability monitoring
- Secure update capability required
- Safety validation of changes
- Monitoring: Manufacturer cybersecurity team & quality assurance
Software Update Implications
- Signed firmware updates
- Secure OTA mechanism
- Rollback capability
- Risk impact analysis per release
- Validation test documentation
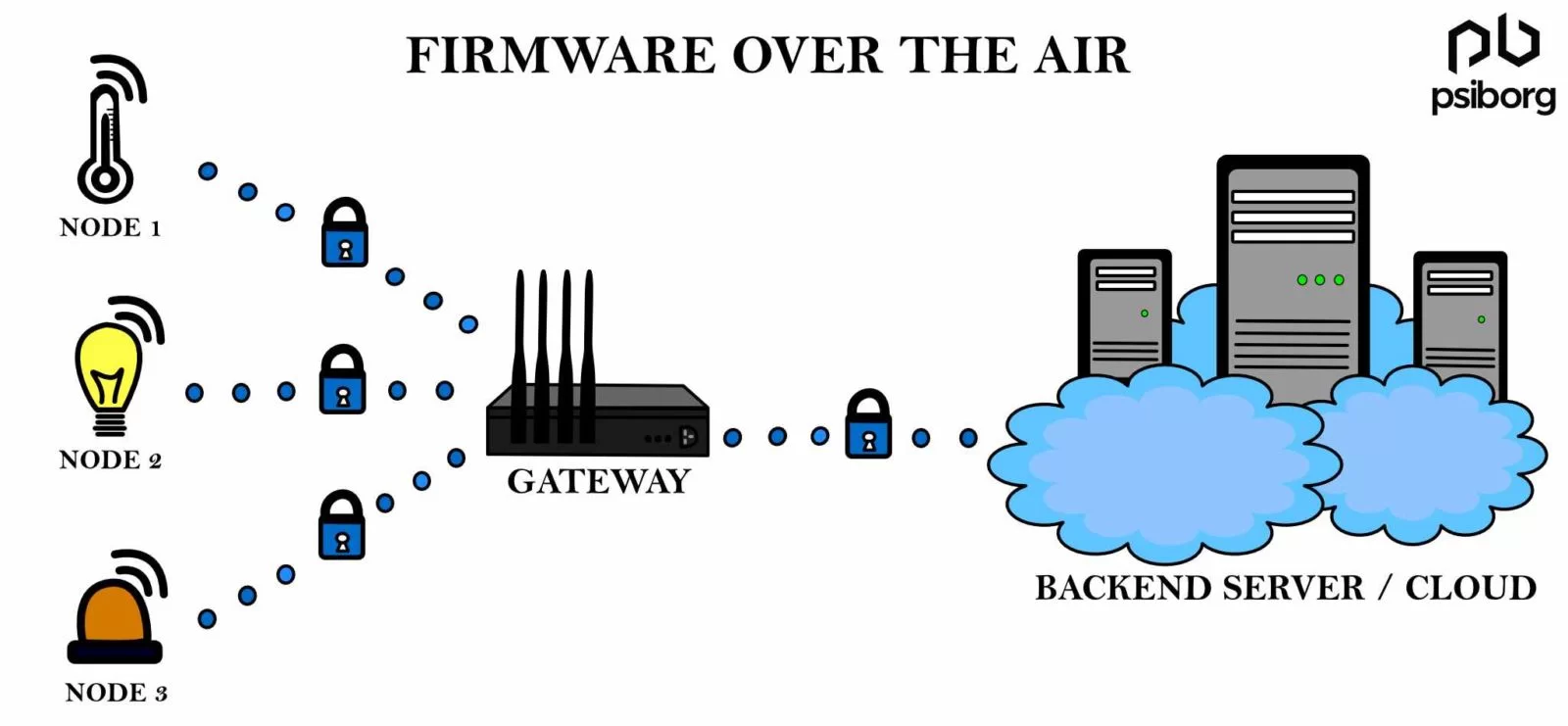
Secure FOTA Mechanism: End-to-End Encrypted
Device Cert
Signature Verify
Mutual Authentication
Key Pinning
Token Validation
Rate Limit
SHA-256 Hash
Version Control
Rotation Policy
Access Control
Install Logged
Outcome Recorded
Integrity Check
No Immediate Flash
Runtime Self-Test
Revert if Failure
End-to-End Secure Update Requirements
Signed Images
Rollback Control
Certificate Pinning
Authenticated Routing
Update Orchestration
Audit Logging
Hash Validation
Access Control
Rotation Policy
Secure Storage
Challenges of Third-Party Software Stacks

Related Research Resource
For a detailed exploration of software update maintenance and legal alignment, see the research article:
https://se4cps.github.io/lab/research/2025-04-23-edi40.html
This source provides empirical context, dependency analysis, and maintenance frameworks that inform legal requirements for IoT software updates.
Module 7
Testing, Verification, Validation
- V-Model definitions
- Test levels + V‑Model
- TDD + AAA
- Unit / Component / Integration / System / Acceptance
- API testing for IoT ingestion
IoT Light Sensor Thread
+-------------+ HTTPS/REST +--------------+ SQL +--------------+
| Sensor | -----------> | Backend API | -----> | Database |
| (ESP32/PI) | | (Flask/Py) | | (MongoDB) |
+-------------+ +--------------+ +--------------+
| |
| MQTT (optional) | WebSocket/REST
v v
+-------------+ +-------------+
| Edge Gateway| | Dashboard |
+-------------+ +-------------+
Testing vs Verification vs Validation
- Verification: artifact correctness (req/design/code)
- Validation: user/business fit
- Testing: defect discovery by execution
Comparison
| Aspect | Verification | Validation | Testing |
|---|---|---|---|
| Primary focus | Specs + artifacts | Outcomes | Runtime behavior |
| Methods | Reviews, static analysis | UAT, field trials | Unit→System, regression |
| IoT Light Sensor | API/DB contract review | Facilities confirms value | Send payload; verify DB + UI |
Verification
- Requirements review
- Design review
- Code review
- Static analysis
IoT Light Sensor: verification targets
- Payload schema + enums
- API contract (codes/errors/auth)
- DB constraints + indexes
- Replay/spoof assumptions
Validation
- Acceptance testing
- Usability + trust checks
- Field trials
IoT Light Sensor: validation questions
- Dashboard supports a decision (energy, safety)
- Alerts actionable (low false positives)
- Works under building constraints (Wi‑Fi, drift)
Test Levels
- Unit: function/module
- Component: service boundary
- Integration: service + DB/cache/queue
- System: end-to-end stack
- Acceptance: user scenarios
V‑Model alignment
Requirements <-------------------------> Acceptance Tests
System Design <-------------------------> System Tests
Component Des. <-------------------------> Integration Tests
Implementation <-------------------------> Unit Tests
Testing
The Goal of Testing
But to discover where it is wrong.
Where Errors Can Exist
- Software can be wrong
- Data can be wrong
- Test cases can be wrong
It does not eliminate it.
Testing Characteristics by Level
UNIT
- Many tests
- Very fast
- Fully automated
- Run on every commit
- Low cost per test
COMPONENT
- Fewer than unit
- Automated
- Slightly slower
- Mock dependencies
INTEGRATION
- Moderate count
- Slower (DB/network)
- CI pipeline stage
- Real infrastructure
SYSTEM
- Few tests
- Much slower
- Staging environment
- Full stack
ACCEPTANCE
- Very few
- Often manual or semi-auto
- Business validation
- Highest execution cost
Test Levels (Stack View)
+----------------------------+
| ACCEPTANCE |
+----------------------------+
▲
+----------------------------+
| SYSTEM |
+----------------------------+
▲
+----------------------------+
| INTEGRATION |
+----------------------------+
▲
+----------------------------+
| COMPONENT |
+----------------------------+
▲
+----------------------------+
| UNIT |
+----------------------------+
Development ↔ Testing + Roles
LEFT SIDE (Build) RIGHT SIDE (Test) ROLE
Requirements ↔ Acceptance Test Client / Product Owner
System Design ↔ System Test QA / Test Engineer
Component Design ↔ Integration Test QA + Dev
Implementation ↔ Unit Test Developer
Key Idea:
Each development artifact has a matching
verification activity and responsible role.
Sensor Payload (contract)
{
"device_id": "ls-0081",
"room_id": "CTC-114",
"lux": 312,
"light_state": "ON",
"timestamp": "2026-02-23T08:15:30Z",
"fw_version": "1.2.0",
"nonce": "c4b8f0c3-2a0d-4d25-9f1c-acde1b7b7b8a"
}
Contract rules
Required: device_id, room_id, lux, light_state, timestamp, nonce
Ranges: lux 0..20000
Enums: light_state ON|OFF|AUTO
Time: timestamp within +/- 2 minutes (configurable)
Replay: nonce must be unique (reject duplicates)
AAA: Arrange: Act: Assert
History
- Popularized with early xUnit frameworks
- Strongly adopted with TDD (2000s)
- Became standard structure for unit tests
Concept
Arrange → Prepare inputs + environment
Act → Execute behavior
Assert → Verify outcome
Core Principle:
One behavior per test.
Why AAA Works at Every Test Level
UNIT
Arrange: payload
Act: validate()
Assert: return value
COMPONENT
Arrange: HTTP request + mock DB
Act: handler()
Assert: status + JSON
INTEGRATION
Arrange: DB + migrations
Act: POST endpoint
Assert: row inserted
SYSTEM
Arrange: deployed stack
Act: simulate sensor input
Assert: dashboard updates
AAA scales because the structure
of testing never changes.
Setup input
Execute
Verify
TDD + AAA
TDD loop:
1) Write failing test
2) Implement minimum to pass
3) Refactor (keep tests green)
AAA:
- Arrange
- Act
- Assert
AAA patterns by test level
| Level | Arrange | Act | Assert |
|---|---|---|---|
| Unit | payload | validate() | "ok" |
| Component | HTTP request | handler() | status 201 |
| Integration | DB ready | POST API | row saved |
| System | full system | send reading | UI updates |
Unit: validatePayload Function
// validatePayload.js
function validatePayload(p) {
if (!p.device_id) return "missing_device_id";
if (!p.room_id) return "missing_room_id";
if (p.lux < 0 || p.lux > 20000) return "bad_lux";
if (p.light_state !== "ON" &&
p.light_state !== "OFF" &&
p.light_state !== "AUTO") return "bad_state";
return "ok";
}
Unit Test (AAA): Negative Case
// Arrange
const payload = {
device_id:"ls-1",
room_id:"CTC-114",
lux:999999, // invalid
light_state:"ON"
};
// Act
const result = validatePayload(payload);
// Assert
console.assert(
result === "bad_lux",
"Unit Test failed: expected bad_lux"
);
console.log("Unit test complete");
Unit: validatePayload Function
// validatePayload.js
function validatePayload(p) {
if (!p.device_id) return "missing_device_id";
if (!p.room_id) return "missing_room_id";
if (p.lux < 0 || p.lux > 20000) return "bad_lux";
if (p.light_state !== "ON" &&
p.light_state !== "OFF" &&
p.light_state !== "AUTO") return "bad_state";
return "ok";
}
Unit Test (AAA): Positive Case
// Arrange
const validPayload = {
device_id: "ls-1",
room_id: "CTC-114",
lux: 350,
light_state: "ON"
};
// Act
const result = validatePayload(validPayload);
// Assert
console.assert(
result === "ok",
"Unit Test failed: expected ok"
);
console.log("Positive unit test complete");
Incorrect Implementation
// validatePayload.js (BUGGY VERSION)
function validatePayload(p) {
if (!p.device_id) return "missing_device_id";
if (!p.room_id) return "missing_room_id";
// ❌ BUG: wrong logic (should be OR, not AND)
if (p.lux < 0 && p.lux > 20000) return "bad_lux";
if (p.light_state !== "ON" &&
p.light_state !== "OFF" &&
p.light_state !== "AUTO") return "bad_state";
return "ok";
}
Unit Test (AAA): Should Fail
// Arrange
const invalidPayload = {
device_id: "ls-1",
room_id: "CTC-114",
lux: 999999, // invalid
light_state: "ON"
};
// Act
const result = validatePayload(invalidPayload);
// Assert (correct expectation)
console.assert(
result === "bad_lux",
"Unit Test failed: expected bad_lux"
);
console.log("Test finished");
Unit: validatePayload Function
// validatePayload.js
function validatePayload(p) {
if (!p.device_id) return "missing_device_id";
if (!p.room_id) return "missing_room_id";
if (p.lux < 0 || p.lux > 20000) return "bad_lux";
if (p.light_state !== "ON" &&
p.light_state !== "OFF" &&
p.light_state !== "AUTO") return "bad_state";
return "ok";
}
Unit Test (AAA): Failing Case
// Arrange
const invalidPayload = {
device_id: "ls-1",
room_id: "CTC-114",
lux: 999999, // invalid
light_state: "ON"
};
// Act
const result = validatePayload(invalidPayload);
// Assert (INTENTIONALLY WRONG EXPECTATION)
console.assert(
result === "ok", // <-- this is wrong
"Unit Test failed: expected ok"
);
console.log("Failing unit test complete");
Component Testing
(curl / Postman)
(Component Under Test)
or Test DB
Component: API Handler
// Simple handler
function postLight(req) {
if (req.body.lux < 0 || req.body.lux > 20000) {
return { status: 400, saved: false };
}
return { status: 201, saved: true };
}
Component Test (AAA)
// Arrange
const request = {
body: { lux: 300 }
};
// Act
const response = postLight(request);
// Assert
console.assert(
response.status === 201,
"Expected 201"
);
console.assert(
response.saved === true,
"Expected saved=true"
);
Component Testing with Postman
- Test API endpoints
- Verify status codes
- Validate JSON responses
- Test authentication
- Check error handling
- Simulate bad input
Postman Workspace
cURL Example
curl -X POST http://localhost:3000/api/v1/telemetry/light \
-H "Content-Type: application/json" \
-d '{
"device_id":"ls-1",
"room_id":"CTC-114",
"lux":300,
"light_state":"ON"
}'
What Each Part Means
- curl → Command-line HTTP client
- -X POST → HTTP method (send data)
- URL → API endpoint address
- -H → HTTP header
- Content-Type → JSON format
- -d → Request body (data payload)
Component Test (AAA): Valid
# Arrange
Valid JSON payload
# Act
curl -X POST http://localhost:3000/api/v1/telemetry/light \
-H "Content-Type: application/json" \
-d '{"lux":300,"light_state":"ON"}'
# Assert
201
{ "saved": true }
Component Test (AAA): Invalid
# Arrange
Invalid JSON (lux too high)
# Act
curl -X POST http://localhost:3000/api/v1/telemetry/light \
-H "Content-Type: application/json" \
-d '{"lux":999999,"light_state":"ON"}'
# Assert
400
{ "error": "bad_lux" }
Integration Testing
Integration Testing
(API Service)
(Database)
Integration Test (AAA): Backend
// Arrange
Valid payload ready
// Act
POST /api/v1/telemetry/light
{
"room_id": "CTC-114",
"lux": 300,
"nonce": "n-1"
}
// Expect backend to write to DB
Integration Test (AAA): Database
-- Assert: row inserted
SELECT lux
FROM light_readings
WHERE room_id='CTC-114'
ORDER BY ts DESC
LIMIT 1; -- expect 300
-- Assert: replay blocked
SELECT COUNT(*)
FROM light_readings
WHERE nonce='n-1'; -- expect 1
Integration Testing: Failure Case
(API Service)
(Constraints)
Database constraint?
Contract mismatch?
System Testing
System Testing (End-to-End)
Real components. Real data flow.
System Test (AAA)
# Arrange
System deployed
Sensor online
Room CTC-114 exists
# Act
Send reading:
lux = 300
room_id = CTC-114
# Assert
Dashboard shows:
Room CTC-114
Lux = 300
Status = ON
Risks
- Slow execution
- Expensive environment
- Hard to debug failures
- Multiple components involved
- Flaky tests (network, timing)
Opportunities
- Validates real behavior
- Detects integration issues
- Confirms business value
- Builds stakeholder trust
- Simulates production use
System Testing: Where Errors Can Occur
- Wrong sensor data
- Backend logic bug
- DB constraint failure
- UI not updating
- Network timeout
User Acceptance Testing (Validation)
User Acceptance Testing (Validation)
(Facility Manager)
Sensor → Backend → DB → Dashboard
After-hours lights → Alert generated → Energy saved
User Acceptance Testing (UAT)
Validation
- User needs
- Business goals
- Real-world usefulness
How to Do Validation
- Talk to users 👤
- Define success metrics
- Build small prototypes (MVP 1, MVP 2, etc.)
- Run pilot tests
- Collect feedback early (Sprint Demo)
Early Validation
- Prototype first
- Less formal testing
- Fast feedback
- Low cost of change
Late Validation
- Build everything first
- Heavy system testing
- Slow feedback
- High cost of change
Validation Timeline
IoT Validation Bottleneck
(Sensor Device)
Hardware changes slow.
Validation Phases
Verification
Verification
to specification.
Verification Example 1
lux must be between 0 and 20000
if (lux < 0 || lux> 20000)
Verification Example 2
POST returns 201 on success
return { status: 201 }
Verification Example 3
nonce must be unique
nonce TEXT UNIQUE
Verification Example 4
Questions?
Build it right
Find errors
Build the right thing
Unit Test Question
function isEven(n) {
return n % 2 === 0;
}
to verify that 4 is even.
Unit Test Answer (AAA)
// Arrange
const number = 4;
// Act
const result = isEven(number);
// Assert
console.assert(
result === true,
"Expected 4 to be even"
);
Module 8
Automation: V-Model & Agentic AI
- Automation foundations
- Verification vs Validation vs Testing
- GenAI vs AI Agentic vs Agentic AI
- IoT Light Sensor App use case
- LangChain + Ollama setup (VS Code)
Labor Market Outcomes: New York Fed Data
- Source: New York Fed: Outcomes by Major
- Unemployment & underemployment breakdowns by college major
- Shows variation in earnings & outcomes across fields
- Useful reference for workforce trend analysis
GitHub Framework Clone Trends
- “Clone” counts on GitHub are not a reliable adoption metric
- Automation and bot traffic can inflate clone statistics
- Some community signals suggest clone activity for many frameworks has plateaued or declined relative to past peaks
- Requires careful interpretation when used as a proxy for ecosystem growth
- See GitHub’s own documentation on interpreting clone/fetch metrics
Automation: Definition
- Execution of repeatable tasks via systems
- Minimizes manual intervention
- Improves reliability and throughput
IoT Light Sensor Flow:
Sensor → API → DB → Dashboard → Alert
Pipeline-driven automation.
Verification
- Are we building the system correctly?
- Focus: internal correctness
IoT Example:
- JSON schema correct?
- API contract valid?
- Database constraints enforced?
- Unit tests passing?
Validation
- Are we building the right system?
- Focus: business requirements
IoT Example:
- Does automation reduce energy waste?
- Is anomaly detection useful?
- Does dashboard meet stakeholder needs?
Testing Layers
- Unit Testing
- Integration Testing
- System Testing
- Acceptance Testing
1. Unit: sensor value parsing
2. Integration: sensor → backend
3. System: full pipeline
4. Acceptance: user workflow validation
Automation in IoT Light Sensor
- Automated data ingestion
- Threshold evaluation
- Event triggering
- Continuous logging
Trigger:
if lux < threshold:
alert()
Continuous execution.
Generative AI (GenAI)
- Content generation
- Text, image, audio synthesis
- Query-response interaction
Example:
"Generate test cases for sensor API"
Output:
- Documentation
- Sample code
No direct execution.
AI Agentic
- Single-task execution
- Performs explicit action
Example:
"Deploy backend service"
Agent:
- Executes deployment script
- Returns status
Agentic AI
- Multi-step orchestration
- Autonomous workflow execution
- Tool coordination
Workflow:
1. Run tests
2. Build container
3. Deploy
4. Monitor logs
5. Notify team
Comparison Summary
- GenAI = content generation
- AI Agentic = single action
- Agentic AI = workflow orchestration
GenAI → Output text
AI Agentic → Execute task
Agentic AI → Coordinate system operations
Agents for Documentation
- Generate README files
- Create API documentation
- Summarize architecture
Input:
- FastAPI routes
- Sensor schema
Output:
- Structured documentation
Agents for Test Generation
- Generate unit tests
- Produce edge cases
- Coverage suggestions
Agent:
- Analyze function
- Generate pytest
- Suggest missing scenarios
Agents for Implementation
- Generate boilerplate
- Refactor code
- Optimize logic
Example:
Generate FastAPI endpoint:
POST /sensor/data
Agents for Testing Automation
- Run CI pipeline
- Analyze logs
- Summarize failures
CI Agent:
- Execute tests
- Parse output
- Generate report
Agents for Deployment
- Build Docker image
- Push to registry
- Deploy service
- Health check validation
docker build .
docker push registry/app
kubectl apply -f deployment.yaml
Complex Agent Workflow (IoT)
1. Detect anomaly
2. Generate patch
3. Run regression tests
4. Deploy fix
5. Monitor metrics
Install Ollama
Download from ollama.com
ollama pull llama3
ollama serve
Install LangChain (CMD)
python -m venv venv
venv\Scripts\activate
pip install langchain
pip install langchain-ollama
Minimal Ollama Agent
from langchain_ollama import ChatOllama
llm = ChatOllama(model="llama3")
response = llm.invoke("Explain IoT testing")
print(response.content)
Engineering Principles
- Automate deterministic steps
- Verify correctness continuously
- Validate against requirements
- Use agents for orchestration
- Integrate automation into lifecycle
Automation + V-Model + Agentic Systems
= Scalable Engineering Practice
Midterm Exam: Friday, March 6
Time: 12:30 AM - 1:30 PM
Format
- 20 questions on paper
- 18 multiple-choice, 2 written response
- Allowed: 2 pencils
Scope
- Modules 1–7 (2–3 questions per module)
- Homework/Lab 1–3
- Sample Midterm 1
- Sample Midterm 1 Answer
Midterm Results
- Course: COMP-233: Software Engineering in Industry 4.0
- Due Date: March 6, 11:59 PM
- Average Score: 79.44 / 100
- Average Percentage: 79%
- Graded commonly: 9 of 11
Good overall performance. Next step: focus on improving system design and resource-aware thinking for IoT systems.
Class Performance
- Total commonly: 11
- Submissions graded: 9
- Average: 79%
Goal for next assessment: move the average into the 80–85% range.
Midterm Practice Questions
Why is software engineering important in the development of IoT/CPS systems?
- It ensures the reliability and robustness of the system process
- It helps manage the complexity of interconnected devices and teams
- It facilitates the integration of various components and technologies
- It ensures the system meets safety and regulatory standards
- All of the above
Answer:
E
What are some key differences between traditional software engineering and software engineering in IoT/CPS?
- Handling unstructured data
- Real-time sensor data processing
- Data-driven decision making
- Ensuring safety and reliability
- All of the above
Answer:
All of the above
What are the different levels of requirements in software engineering?
- Unstructured Requirements
- Epics
- User Stories
- Tasks
- All of the above
Answer:
E
Why are requirements important for IoT/CPS systems?
- They ensure the system meets user needs and expectations
- They help manage the complexity of interconnected devices
- They facilitate the integration of various components and technologies
- They ensure the system meets safety and regulatory standards
- All of the above
Answer:
E
What are the differences between Unstructured Requirements, Epics, User Stories, and Tasks in software engineering?
- Unstructured Requirements are detailed specifications, while Epics are high-level goals
- User Stories are broad objectives, while Tasks are specific actions
- Epics are large bodies of work that can be broken down into User Stories, which are further divided into Tasks
- Unstructured Requirements are informal and not well-defined, while Epics, User Stories, and Tasks are structured and detailed
- All of the above
Answer:
C
What is the difference between User Stories and Tasks?
- Stories are high-level, Tasks are specific
- Stories are detailed, Tasks are high-level
- Stories are actions, Tasks are objectives
- Stories add value, Tasks complete contributions
- All of the above
Answer:
D
What components does a User Story typically have in software engineering?
- Title
- Description
- Acceptance Criteria
- Effort
- All of the above
Answer:
E
What is the typical structure of a User Story in software engineering?
- As a user, I would like to [goal], so that [reason]
- As a [role], I want to [action], so that [benefit]
- As a [role], I need [requirement], because [justification]
- As a [role], I would like to [goal], so that [reason]
- All of the above
Answer:
E
What is a key difference between the Waterfall model and the V-Model in software development?
- The Waterfall model is iterative, while the V-Model is linear
- The V-Model emphasizes verification and validation at each development stage
- The Waterfall model supports parallel development and testing
- The V-Model does not include any testing phases
- Both models are identical in their approach
Answer:
B
What is a key difference between the V-Model and Agile Model in software development?
- The V-Model is iterative, while Agile is linear
- The V-Model emphasizes verification and validation at each development stage
- Agile supports continuous integration and delivery
- The V-Model does not include any testing phases
- Both models are identical in their approach
Answer:
C
What are the phases of the V-Model in software development?
- Requirements, Design, Coding, Unit Testing, Integration Testing
- Requirements, Design, Architecture, Module Design, Coding, Testing
- Requirements, Design, Coding, System Testing, Acceptance Testing
- Requirements, Architecture, Coding, Unit Testing, System Testing
- Requirements, Design, Coding, Integration Testing, Acceptance Testing
Answer:
B
Why can Scrum be integrated into the V-Model in software development?
- Scrum provides flexibility within the structured phases of the V-Model
- Scrum emphasizes continuous integration and delivery
- Scrum allows for iterative development and feedback within each phase
- Scrum improves team collaboration and communication
- All of the above
Answer:
E
How does Conway's Law relate to team structure and software architecture?
- Structure of a software system mirrors the communication structure of the team that built it
- It suggests that software architecture should be designed independently of team structure
- It implies that larger teams produce more complex software architectures
- It indicates that team structure has no impact on software architecture
- All of the above
Answer:
A
Why can Scrum be integrated into the V-Model in software development?
- Scrum allows for major changes to be made during sprints
- Scrum enables iterative software updates that do not impact validation
- Scrum supports continuous feedback and improvement for non-critical features
- Scrum improves team collaboration and communication during each phase
- Scrum is only used for documentation purposes
Answer:
B, C, D
How does the V-Model mitigate the risks associated with Conway's Law?
- By ensuring that the software architecture is designed independently of team structure
- By emphasizing verification and validation at each development stage
- By promoting continuous integration and delivery
- By reducing the complexity of software architectures
- All of the above
Answer:
B
How does the V-Model mitigate the risks with the Form, Storm, Norm, and Perform?
- By providing clear roles and responsibilities during Forming
- By emphasizing structured communication and conflict resolution during Storming
- By establishing standards and processes during Norming
- By ensuring continuous verification and validation during Performing
- All of the above
Answer:
E
Does the V-Model natively support cross-functional teams in software development?
- Yes, it fully integrates cross-functional teams
- No, it primarily focuses on sequential development phases
- Yes, but only in the testing phases
- No, it requires significant adaptation to support cross-functional teams
Answer:
B
Which aspects require the V-Model?

What is a key difference between the Incremental Model and the Sequential (Waterfall) Model?
- Incremental Model delivers the complete system at once, while the Sequential Model delivers it in parts
- Incremental Model allows for iterative development and feedback, while the Sequential Model follows a linear approach
- Incremental Model does not include any testing phases, while the Sequential Model emphasizes testing
- Incremental Model is used for small projects, while the Sequential Model is used for large projects
Answer:
B
What is the definition of software architecture?
- The process of writing code for software applications
- The high-level structure of a software system
- The detailed design of individual software modules
- The testing and validation of software systems
Answer:
B
Which of the following are architectural decisions in software development?
- Database selection
- Programming language choice
- Software framework selection
- Integrated Development environment
Answer:
A, B, C
What is the API-first approach in architectural design?
- Designing the user interface before the API
- Developing the backend logic before the API
- Prioritizing the design and development of APIFs
- Implementing database schemas before the API
Answer:
C
What is the role of feature toggles in architectural design?
- To enable/disable features without deploying new code
- To manage database schemas and configurations
- To design user interfaces and layouts
- To handle network settings and protocols
Answer:
A
How do feature toggles support the V-Model in real applications?
- By enabling features without redeploying code
- By managing database schemas and configurations effectively
- By designing user interfaces and layouts efficiently
- By handling network settings and protocols seamlessly
Answer:
A
Why does the event-driven model match well with IoT/CPS systems?
- It requires less power consumption
- It complicates user interface design
- Sensors trigger events in real-time
- It increasees the need for data storage
Answer:
A, C
Why is the layered model a good model for IoT/CPS systems?
- It simplifies user interface design
- It reduces the need for data storage
- It models sensors at the core layer
- It requires less power consumption
Answer:
C
Why are IoT/CPS systems impacted by legal constraints?
- Sensor-based realtime decisions impact safety
- They involve handling sensitive user data
- Battery powered components require safety measures
- They reduce the need for data storage
Answer:
A, B, C
In theory, are legal requirements more aligned with the Sequential or Incremental Model?
- Sequential Model
- Incremental Model
- Both equally
- Neither
Answer:
A
How does the V-Model align with legal requirements?
- By ensuring rapid development cycles
- By promoting team collaboration
- By tracing validation and verification
- By reducing development costs
Answer:
C
In a RACI chart, who is legally chargeable?
- Responsible role
- Accountable role
- Consulted role
- Informed role
Answer:
Accountable
Do legal requirements prevent errors in software, hardware, or data?
- Yes, they ensure no errors occur
- No, they do not prevent errors
- Yes, but only for software errors
- No, they only address compliance
Answer:
B
What mechanism do accountable roles use to mitigate risks in software development?
- Invest more in quality assurance processes
- Focus on feature development over quality
- Reduce the number of team members
- Ignore minor bugs to speed up development
Answer:
A
What is the difference between testing, verification, and validation?
- Testing ensures that the software functions correctly
- Verification checks if the software meets design specifications
- Validation ensures the software meets user needs and requirements
- All of the above
Answer:
All of the above
RACI Chart for a Software Development Project
| Task | Responsible | Accountable | Consulted | Informed |
|---|---|---|---|---|
| Requirement Gathering | ? | Project Manager | Stakeholders | ? |
| Design | Architect | Project Manager | ? | Stakeholders |
| Implementation | Developers | Technical Lead | Architect | Project Manager |
| Testing | QA Team | QA Lead | Developers | Project Manager |
| Deployment | DevOps Engineer | Technical Lead | QA Team | Stakeholders |
In a RACI chart, who is responsible for the Implementation task?
- Business Analyst
- Architect
- Developers
- QA Team
Answer:
Developers
How much of the V-Model's effort is typically allocated to testing?
- 10%
- 25%
- 50%
- 75%
Answer:
50%
Does testing in the V-Model happen in parallel with implementation or after implementation?
- In parallel with implementation
- After implementation
- Before implementation
- Not related to implementation
Answer:
After implementation
Which test levels in the V-Model require coding skills?
- Unit Testing
- Component Testing
- Integration Testing
- System Testing
Answer:
Unit Testing
What are the steps in the Arrange, Act, Assert (AApattern for unit tests?
- Arrange: Set up the necessary conditions and inputs for the test
- Act: Execute the functionality being tested
- Assert: Verify that the outcome matches the expected result
- All of the above
Answer:
All of the above
Will this unit test case be OK or NOK?
// Arrange
const a = 2;
const b = 3;
const expectedSum = 5;
// Act
const result = a + b - 1;
// Assert
console.assert(result === expectedSum, `Expected ${expectedSum}, but got ${result}`);
What does Test-Driven Development (TDmean in software development?
- Writing tests after the code is implemented
- Writing tests before the code is implemented
- Skipping tests to speed up development
- Only testing the final product
Answer:
Writing tests before the code is implemented
How does Test-Driven Development (TDalign with the V-Model in software development?
- Both emphasize early testing and validation
- Both require writing tests after implementation
- Both focus on rapid development cycles
- Both prioritize feature development over quality assurance
Answer:
Both emphasize early testing and validation
Why is Test-Driven Development (TDconsidered difficult in software development?
- It requires writing tests before the code is implemented
- It demands a thorough understanding of the requirements and design upfront
- It can slow down the initial development process
- It requires maintaining and updating tests as the code evolves
Answer:
It demands a thorough understanding of the requirements and design upfront
As a tester, if the software fails, do you go test levels down or up?
- Down
- Up
- Neither
- Both
Answer:
Down
Which test levels in V-Model for IoT/CPS can be more/less automated?
- Unit Testing
- Component Testing
- Integration Testing
- System Testing
- Acceptance Testing
Answer:
More automated: Unit Testing, Component Testing, Integration Testing
Less likely to be automated: System Testing, Acceptance Testing
How can sensor errors be identified and mitigated during testing in IoT/CPS systems?
- By using redundancy with multiple sensors
- By performing regular calibration of sensors
- By implementing error handling and logging mechanisms
- All of the above
Answer:
All of the above
During testing, the sensor is occasionally not working correctly. Please a paragraph with a plan how to find the error?
A legal regulation states that from March/2025 indoor plants cannot be watered using our system. How do you recommend addressing the issue in the current (MVP 1) plant watering project? How does it impact our process? Please provide a paragraph.
- Sprint #6 Demo: MVP Release
- Midterm Practice Questions
Why are unit tests easier to automate compared to component tests?
- They focus on small, isolated functions with minimal dependencies
- They require fewer external resources and configurations
- They run faster and provide immediate feedback
- All of the above
Will the following unit test pass or fail?
function add(a, {
return a + b + b;
}
function unittests() {
// Arrange
const a = 10, b = 5;
// Act
const result = add(a, b);
// Assert
console.assert(result === 15, `Test failed: expected 15, got ${result}`);
}
unittests();
Will the following unit test pass or fail?
function multiply(a, {
return a * b;
}
function unittests() {
// Arrange
const a = 4, b = 3;
// Act
const result = multiply(a, b);
// Assert
console.assert(result === 12, `Test failed: expected 12, got ${result}`);
}
unittests();
Will the following unit test pass or fail?
function subtract(a, {
return a - b;
}
function unittests() {
// Arrange
const a = 10, b = 5;
// Act
const result = subtract(a, b);
// Assert
console.assert(result === 4, `Test failed: expected 4, got ${result}`);
}
unittests();
Our flower inventory management system will be installed for outdoor plants in a different climate room. Please list five ways it will impact our current prototype and why?
In a flower inventory management system, where multiple features such as stock tracking, price updates, and order management are being developed simultaneously, there is little capacity for extensive review processes before merging. The need to push frequent updates quickly, such as adding new flowers to the database, adjusting prices based on seasonal demand, or managing promotions, requires a workflow that can handle continuous integration and deployment
Please explain three reasons why Feature GitFlow might not be suitable for this system?
When adding one feature to the flower inventory management system, what type of issue should you create?
- Epic Issue
- User Story Issue
- Task Issue
- Bugfix Issue
When planning a major upgrade to the flower inventory management system, which will include multiple related features, what type of issue should you create?
- Epic Issue
- User Story Issue
- Task Issue
- Bugfix Issue
Context:
- The hospital indoor light tracking system is extended to multiple departments and buildings.
- Real-time light status supports:
- Clinical decision-making
- Patient safety alerts
- Operational workflows
- The system must:
- Scale across locations
- Support independent feature deployment
- Ensure high availability
Question:
- Which phases of the V-Model are impacted (e.g., requirements, architectural design, integration testing, system validation, acceptance testing)?
- What specific changes are required in each impacted phase and its corresponding verification activity?
Module 9
Holiday Week
Module 10
Resource Constraints and Sustainability
Topics
- Resource Constraints in IoT
- Battery-Driven Software
- Network Bandwidth Constraints
- CPU and Processing Limits
- Data Optimization Techniques

Sustainability in IoT Systems
Design systems that minimize environmental impact.
- Battery Life: reduce power consumption
- Network Use: transmit only necessary data
- Hardware Lifetime: avoid unnecessary computation
- Data Efficiency: compress and batch messages
- Maintenance: fewer battery replacements
Goal: build IoT systems that are efficient, reliable, and environmentally responsible.

Constrained Resources in IoT Applications
- Storage: Limited storage restricts data that can be logged and retained
- Power: Battery-driven devices must minimize energy consumption
- Memory: Small RAM limits data processing and buffering
- Processing Power: Embedded CPUs cannot run heavy computations
- Network Bandwidth: Wireless communication often slow and expensive
Data Structures for Efficient Resource Usage
| Data Structure | Usage in IoT |
|---|---|
| Ring Buffer | Fixed memory, overwrites old data, good for streams |
| Array | Fast access, predictable memory, fixed-size datasets |
| Linked List | Dynamic size, flexible updates, more memory overhead |
| Hash Table | Fast lookup, useful for caching, extra memory cost |
| Queue | FIFO processing, task scheduling, event handling |
From Linear Storage → Ring Storage
- Sensor sends data every few seconds
- List keeps growing
- Embedded memory is limited
- Old data should be overwritten
Question:
Which line must change to turn this into a ring buffer?
class Storage:
def __init__(self, size):
self.size = size
self.data = [None]*size
self.index = 0
def append(self, value):
self.data[self.index] = value
# CHANGE THIS LINE
self.index = self.index + 1
Solution: Ring Buffer Index
Correct change:
self.index = (self.index + 1) % self.size
- % keeps the index inside the buffer size
- When the end is reached, the index returns to 0
- New values overwrite the oldest values
- Memory usage stays constant
Result: The list becomes a ring buffer instead of growing forever.
class Storage:
def __init__(self, size):
self.size = size
self.data = [None]*size
self.index = 0
def append(self, value):
self.data[self.index] = value
# RING BUFFER
self.index = (self.index + 1) % self.size
Battery-Driven Software
Battery-driven systems need software that reduces energy usage while preserving core functionality.
- IoT Sensors: Enter sleep mode when idle
- Wearables: Adjust display brightness automatically
- Environmental Monitoring: Reduce sampling frequency
- Smart Home Devices: Lower communication frequency

Adaptive Sync Interval
A light sensor can change how often it sends data based on room conditions.
- Stable Light: Sync every 6 hours
- Changing Light: Sync every 2 hours
- Critical Change: Sync every 30 minutes
function getSyncInterval(lightChanged) {
if (!lightChanged) return "6 hours";
return "30 minutes";
}
console.log(getSyncInterval(true));
Adaptive Sync Interval (Light Sensor)
- Stable light: sync rarely
- Light changing: sync more often
- Critical change: sync frequently
Goal: reduce network traffic and battery usage.
function getSyncInterval(hoursSinceChange){
if(hoursSinceChange < 6)
return "6 hours";
if(hoursSinceChange < 24)
return "2 hours";
return "30 minutes";
}
Adaptive Sync Based on Battery
- High battery: send updates frequently
- Medium battery: reduce sync rate
- Low battery: send only essential updates
Goal: extend device lifetime when the battery is low.
function getSyncInterval(battery){
if (battery > 60)
return "30 minutes";
if (battery > 20)
return "2 hours";
return "6 hours";
}
Network Bandwidth Constraints
| Connectivity | Typical Bandwidth |
|---|---|
| Bluetooth Low Energy | 0.1: 2 Mbps |
| Bluetooth Classic | 1: 3 Mbps |
| 4G LTE | 10: 100 Mbps |
| Wi-Fi | 100: 1000 Mbps |
Light Sensor Signal Volume
| Sampling Rate | Sensor Data Volume |
|---|---|
| 1 sample / minute | Very Low Traffic |
| 1 sample / second | Moderate Traffic |
| 10 samples / second | High Traffic |
| 100 samples / second | Very High Traffic |
Higher sampling rates increase network usage and battery consumption.
Optimizing Data Transmission
- Streaming: Send each reading immediately
- Compression: Reduce payload size
- Batching: Send multiple readings together
// Streaming
{ "lux":420 }
{ "lux":418 }
{ "lux":421 }
// Compression
{ "l":[420,418,421] }
// Batching
{ "lux":[420,418,421] }
GPS Data Compression with Polyline
- Polyline Encoding: Encodes paths compactly
- Delta Encoding: Sends only changes between points
- Compression: Further reduces transmission size
// Raw GPS coordinates
[
[37.7749, -122.4194],
[37.7750, -122.4195],
[37.7752, -122.4197]
]
// Polyline encoded
"c|peFf`ejVq}@n}@"
3 GPS points → short encoded string
JSON vs Protobuf
- JSON: Human-readable, easy to debug, but larger
- Protobuf: Compact binary format, smaller and faster
- Benefit for IoT: Less bandwidth, less storage, faster transfer
Flower Watering Payload: JSON vs Protobuf
| JSON | Protobuf |
|---|---|
|
|
JSON → Protobuf (Light Sensor)
Convert light sensor data to a smaller format.
- JSON: readable but larger
- Protobuf: compact binary format
- Saves bandwidth for IoT sensors
data = {
"sensor_id":12,
"lux":420
}
msg = LightReading(**data)
binary = msg.SerializeToString()
Example Payload
JSON
{
"sensor_id":12,
"lux":420
}
Protobuf
08 0C 10 A4 03
Rule: Avoid Continuous Loops
Problem: Busy loops waste CPU and battery.
- CPU runs continuously
- Battery drains faster
- Sensor is read even when nothing changes
- Not suitable for embedded IoT devices
// BAD: Continuous polling
while(true){
readLightSensor();
}
Preferred: Event-Based Design
Idea: Run code only when an event occurs.
- CPU sleeps most of the time
- Battery lasts longer
- Sensor triggers when value changes
- Common pattern in IoT firmware
// GOOD: Event-based sensor trigger
lightSensor.onChange((lux) => {
sendLightReading(lux);
});
Managing CPU Limitations
- Use simple algorithms
- Sample sensor less often
- Sleep between readings
- Reduce unnecessary processing
// High CPU usage
while(true){
readLight();
}
// Better approach
setInterval(readLight,5000);
Read sensor every 5 seconds instead of continuously.
Design Question
A battery-powered light sensor sends brightness data continuously.
How can we reduce resource usage?
- Battery
- Network traffic
- CPU usage
- Send only when light changes
- Batch multiple readings
- Compress sensor data
- Reduce sampling at night
Naive Sensor Loop
Reads and sends data 1/second.
- Continuous polling
- Frequent transmissions
- Higher battery usage
void loop() {
float lux = lightMeter.readLightLevel(); // 1/s
Serial.println(lux); // Send data every second
delay(1000); // Wake CPU again after 1s
}
⚠ Device wakes 60 times per minute even if light is stable.
Resource-Friendly Version
Send data on change.
- Fewer transmissions
- Longer sleep intervals
- Lower CPU and radio usage
float lastLux = -1;
void loop() {
float lux = lightMeter.readLightLevel();
if (abs(lux - lastLux) > 10) { // delta >10
Serial.println(lux);
lastLux = lux;
}
delay(5000); // Wake only every 5 seconds
}
✓ Device wakes 12 times per minute
✓ Transmits only when light changes
Resource Constraints Matrix
Think about how each constraint impacts our light sensor IoT project.
- Battery powered embedded device
- Wireless data transmission
- Limited memory and CPU
- Intermittent connectivity
Question:
How does each constraint influence system design?
| Constraint | Impact on Project |
|---|---|
| Battery | ? |
| Bandwidth | ? |
| Connectivity | ? |
| Storage | ? |
| CPU | ? |
Agenda
- Daily Quiz
- MVP #2 Goal
- Validation vs Verification vs Testing
- Sprint #8: #12 + Product Owner
- Sprint User Story Planning
Daily Quiz
- Why avoid continuous loops in IoT?
- What is a ring buffer?
- Why reduce network transmission?
- What is event-based design?
MVP #2 Goal
- System works end-to-end
- Sensor → Backend → Database → Dashboard
- Focus on correctness over features
- Validation - Verification - Testing
Validation
- Are we building the right system?
- Does it solve the user problem?
- Does dashboard reflect real-world use?
Verification
- Are we building the system correctly?
- Does code meet requirements?
- Is API returning expected values?
Testing
- Unit Testing
- Integration Testing
- System Testing
Planning
| Topic \ Sprint | SP#8 | SP#9 | SP#10 | SP#11 | SP#12 |
|---|---|---|---|---|---|
| Requirements Engineering | |||||
| Team Structure | |||||
| Development Process | |||||
| Architecture Design | |||||
| Legal Constraints | |||||
| Testing / Verification / Validation | |||||
| Resource Constraints | |||||
| Cyber Security | |||||
| Release Process | |||||
| Testing & Bug Fixing | |||||
| Final Presentation |
Sprint #8: #12
- Sprint 8 →
- Sprint 9 →
- Sprint 10 →
- Sprint 11 →
- Sprint 12 → Demo MVP 2
Product Owner
- Sprint 8 →
- Sprint 9 →
- Sprint 10 →
- Sprint 11 →
- Sprint 12 → Demo MVP 2
User Story Planning
- As a user, I want to see light data
- As a user, I want alerts on changes
- As a system, send only necessary data
Group Task
- Update validation user stories
- Update verification tasks
- Update test case tasks
Present in 10 minutes
Agenda
- Resource Constraints
- Daily Quiz
- Daily StandUp
Resource Constraints
- Limited Production Data
- Limited T-Role Engineers
- Limited Testing Resources
- Limited Test Environment Realism
- Limited Physical Accessibility (Maintenance)
- Limited Firmware Update Capacity
- Limited Observability (Monitoring & Debugging)
- Limited Interoperability (Heterogeneous Devices)
Limited Production Data
Testing vs Production Data
- Testing: Small, Clean, Controlled
- Production: Large, Noisy, Real
- Mismatch → Risk
Testing |██████░░░░░░░░░░░░░░░░| 20%
Production |████████████████████░░| 80%
Production Data Variety
- Format: JSON, CSV, Binary
- Value: Clean vs Noisy vs Missing
- Units: °C, °F, Lux, Volts
- Types: Int, Float, Boolean, String
{
"examples": [
{ "temp": 22.5, "unit": "C" },
{ "temp": 72.5, "unit": "F" },
{ "temp_raw": "10101101", "format": "binary" },
{ "temp": null },
{ "temp": "high" }
]
}
Semi-Structured Data
- Data: actual sensor readings
- Metadata: context (unit, type, timestamp)
- Flexible but organized
- Handles variability in production
{
"data": {
"light": 350
},
"metadata": {
"light": {
"unit": "lux",
"type": "int"
},
"timestamp": "2026-03-20T10:30:00Z",
"device_id": "sensor_101"
}
}
JSON Databases (NoSQL)
- Flexible Schema
- Handles Data Variety
- Scalable for IoT
- Real-Time Processing
IoT Devices
│
▼
JSON Data Stream
│
┌───────────┼───────────┐
▼ ▼ ▼
MongoDB Cassandra Redis
(Document) (Wide Col) (Key-Value)
│ │ │
└───────┬───┴───────┬───┘
▼ ▼
IndexedDB Applications
(Browser) (Dashboards)
Sample Project

Limited T-Role Engineers
- Need depth + breadth
- Hardware + Software + Data
- Rare skill combination
- Slows development
T-Shaped Skill
│ Depth
│
────┼──── Breadth
│
IoT = Embedded + Cloud + Data
Sample Project
Limited Testing Resources
- Few physical devices
- Costly test setups
- Hard to scale tests
- Limited coverage
Devices Available
Test Need: ██████████
Devices: ███
Gap → Untested cases
Sample Project
Test Environment Realism
- Lab ≠ Real World
- Missing noise & interference
- Limited variability
- Hidden failures
Lab Real World
Clean Noisy
Stable Variable
Predictable Uncertain
→ Mismatch Risk
Sample Project
Physical Accessibility
- Remote deployments
- Hard to repair devices
- Delayed maintenance
- Requires reliability
Device Location
Lab → Easy Access
Field → Hard Access
Fix Cost ↑ Distance ↑
Sample Project
Firmware Updates
- Limited flash space
- Risk of failure
- Bandwidth constraints
- No easy rollback
Old FW → New FW
[v1] → [v2]
Risk:
- Fail → Device breaks
- No rollback
→ Careful updates
Sample Project
Observability
- Limited logging
- Hard to debug remotely
- Low visibility
- Hidden system states
System State
Visible: ███
Hidden: ███████
→ Hard to diagnose issues
Sample Project
Interoperability
- Different devices & protocols
- Inconsistent data formats
- Integration challenges
- High system complexity
Devices
Sensor A → JSON
Sensor B → CSV
Sensor C → Binary
→ Integration Layer Needed
Sample Project
Questions?
QR Room Status System
Scenario:
Scan a QR code to check room status (light, occupancy) from anywhere.
Question:
What are the resource limitations?
User → Scan QR
│
▼
Mobile App
│
▼
Cloud / API
│
▼
IoT Sensor
│
▼
Room Status
Daily Quiz
- Short (5 questions)
- Concept-focused
- Fast feedback
- Reinforces learning
Learn → Test → Reflect
Q1 Q2 Q3 Q4 Q5
│ │ │ │ │
└──► Understanding
Duration: ~10 min
Daily StandUp
- Yesterday: What was done?
- Today: What next?
- Blockers: Any issues?
- Short & focused
Team Flow
Yesterday → Today → Blockers
│ │ │
└──────────► Progress ◄─┘
Time: ~5–10 min
Module 11
Cyber Security in Industry 4.0 Ecosystems
Protecting connected systems, data, and infrastructure.
Agenda
- SQL Injection
- Encryption
- Access Control
- Distributed DB Security
- Best Practices

IoT Cybersecurity
Cybersecurity Defects in IoT Software
- Data Leakage: Unauthorized exposure of sensitive data
- No Access to Data: Inability to access critical data
- Unauthorized Access: Gaining access without permission
- Data Corruption: Tampering with sensor data or device controls
- Insecure Communication: Unprotected data transfer between devices
- Lack of Device Authentication: Unverified devices

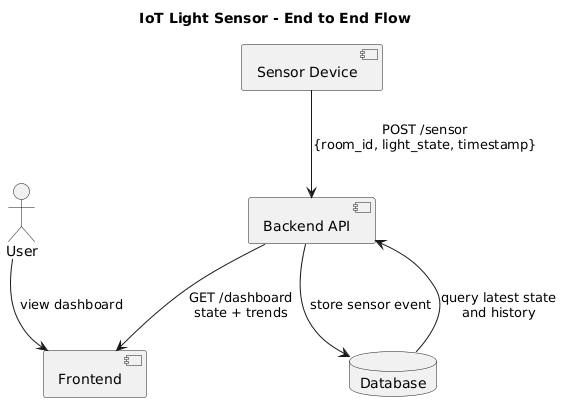
IoT Cybersecurity - Where to Start 🤔
Zero Trust in IoT Cybersecurity
Zero Trust: No device or user is trusted by default
- Continuous Auth: Verify at every step
- Least Privilege: Minimal access
- Segmentation: Isolate devices
- Dynamic Policy: Context-based rules
Aspects That Earn Zero Trust
- Data: Encrypt and restrict access
- Software: Monitor and validate
- Network: Segment and control
- OS: Enforce policies
- Devices: Authenticate continuously
- Rules: Dynamic policies
- People: Strong identity checks
IoT Device Cybersecurity Capability Core Baseline
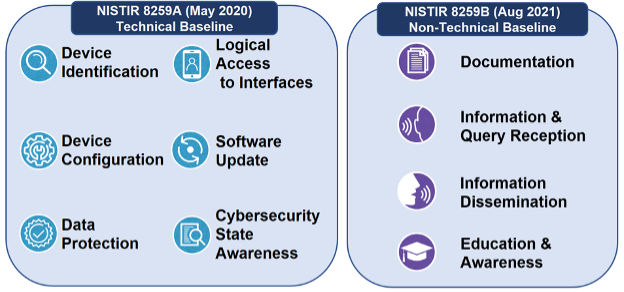
IoT Light Sensor Device
| Aspect | Light Sensor System |
|---|---|
| Device Identification | Unique device_id assigned to each sensor |
| Device Configuration | Configured room_id, sampling rate, thresholds |
| Data Protection | Encrypt sensor data and device credentials |
| Cybersecurity State Awareness | Monitor device status and abnormal readings |
| Logical Access to Interfaces | Restrict API/database access via roles |
| Software Update | Secure OTA updates with validation checks |
IoT Cybersecurity - Where to Start 🤔
Database Security
Database Access Control
Access Control Flow
What Is Access Control?
Controls who can access data
- Prevents unauthorized access
- Enforces least privilege
- Core to database security
- Authentication: Who are you?
- Authorization: What can you do?
- AuthN → identity check
- AuthZ → permission control
API Key & DB Connection
API Key
Restrict access via unique keys
- Map to roles
- Used in apps/services
- Rotate or revoke
DB URL
postgresql://username:password@host:port/database?sslmode=require- username: neondb_owner
- password: acts as key
- host: neon.tech
- database: neondb
- sslmode: encrypted
IP-Based Access Control
Restrict DB/API access to specific IP addresses
- Allow trusted IPs only
- Block external sources
- Used in firewall/DB
Access Control Models
- DAC: Owner controls access
- MAC: Based on security labels
- RBAC: Role defines permissions
Access Control Models: Use Case
| Model | Who Controls Access? | Access Logic | Example | Supported by Relational DBs |
|---|---|---|---|---|
| RBAC | System (via Roles) | User has role with permission | Doctor role can read patient record | ✅ Widely Supported |
| DAC | Record Owner | Owner grants access | Patient grants doctor access | ✅ Partially Supported |
| MAC | System (via Labels) | Access requires clearance | Only staff with "Confidential" clearance can read | ❌ Rarely Supported |
Role-Based Access Control (RBAC)
- Users → Roles → Permissions
- Centralized control
- Scales in large systems (from n*n to n)

RBAC in IoT Light Sensor App
Roles & Users
CREATE ROLE iot_user;
CREATE ROLE iot_admin;
CREATE ROLE iot_device;
CREATE USER alice WITH PASSWORD 'secure123';
GRANT user TO alice;Permissions
- READ (sensor data)
- WRITE (config/settings)
- ADMIN (full control)
Access Control
GRANT READ ON light_data TO user;
GRANT ALL ON light_data TO admin;
GRANT INSERT ON light_data TO device;Revoke
REVOKE READ ON light_data FROM user;
REVOKE ALL PRIVILEGES
ON ALL TABLES IN SCHEMA public
FROM PUBLIC;Granular Access Support
| Database | RBAC Support | IP-Based Access | API Key Control |
|---|---|---|---|
| SQLite | ❌ | ❌ | External Only |
| PostgreSQL | ✅ Column-Level | ✅ via pg_hba.conf | External Only |
| MariaDB | ✅ Roles + Fine-Grained | ✅ via host-based grants | External Only |
| OracleDB | ✅ RBAC + VPD | ✅ via network ACLs | External Only |
| MongoDB | ✅ Roles | ✅ via network/IP allowlist | External Only |
| Redis | ⚠️ Basic ACLs | ✅ via bind/firewall | External Only |
Summary
- Start with API key or user identity
- Use RBAC to simplify privilege logic
- Use GRANT/REVOKE for control
- Choose DB based on granularity needs
Question
Database Encryption

Plain Text vs. Encrypted Text (IoT Light Sensor App)
| Plain Text | Encrypted Text |
|---|---|
| Device ID: LightSensor_01 | LightSensor_01 |
| Light Level: 300 lux | 300 lux |
| User SSN: 123-45-6789 | U2FsdGVkX1+gTx4kV7K9Zw== |
PostgreSQL Example (IoT Light Sensor)
CREATE TABLE light_sensor_data (
id SERIAL PRIMARY KEY,
device_id TEXT,
light_level INTEGER,
location TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
CREATE TABLE user_data (
user_id SERIAL PRIMARY KEY,
name TEXT,
ssn TEXT
);
What Is Database Encryption?
- Converts sensitive data to unreadable form
- Requires a key for access
- Limits damage if data is exposed
Why Encrypt?
- Protect user data
- Support compliance
- Reduce breach impact
Types
- At Rest
- In Transit (SSL/TLS)
- Column-Level (SSN)
PostgreSQL Encryption (pgcrypto)
-- Enable extension
CREATE EXTENSION IF NOT EXISTS pgcrypto;
-- Insert (encrypt sensitive field)
INSERT INTO user_data (name, ssn)
VALUES (
'Alice',
pgp_sym_encrypt('123-45-6789', 'secret_key')
);
-- Sensor data (NOT encrypted)
INSERT INTO light_sensor_data (device_id, light_level)
VALUES ('LS_01', 300);
-- Decrypt SSN
SELECT
name,
pgp_sym_decrypt(ssn::bytea, 'secret_key') AS ssn
FROM user_data;
-- Read sensor data (plain)
SELECT device_id, light_level
FROM light_sensor_data;
TDE
- Automatic file encryption
- Managed by DB
- Low app impact
What to Encrypt?
- Encrypt: SSN, passwords, tokens
- Do not: sensor values (light level)
- Keep operational data fast
Key Management
- Use KMS/HSM
- Rotate keys
- Protect access
Performance
- CPU overhead
- Column-level selective
- Index carefully
Risks (No Encryption)
- Data exposure
- Network leaks
- Compliance issues
Tradeoffs
- + Security
- - Performance
- - Key complexity
DB Support
| DB | At Rest | Transit | Column | TDE |
|---|---|---|---|---|
| SQLite | ❌ | ❌ | ❌ | ❌ |
| PostgreSQL | ✅ | ✅ | ✅ | ❌ |
| MariaDB | ✅ | ✅ | ✅ | ✅ |
| OracleDB | ✅ | ✅ | ✅ | ✅ |
| MongoDB | ✅ | ✅ | ✅ | ⚠️ |
| Redis | ⚠️ | ✅ | ❌ | ❌ |
Summary
- Encrypt sensitive fields only
- Use SSL/TLS for transport
- Manage keys carefully
- Balance security and performance
Question
Database Fragmentation
Database Vertical Fragmentation for Privacy
- Separates identifiers from sensitive content
- Example: store patient names in one table/database, diagnoses in another
- Reduces risk of re-identification if breached
- Used in privacy-preserving and regulatory-compliant systems
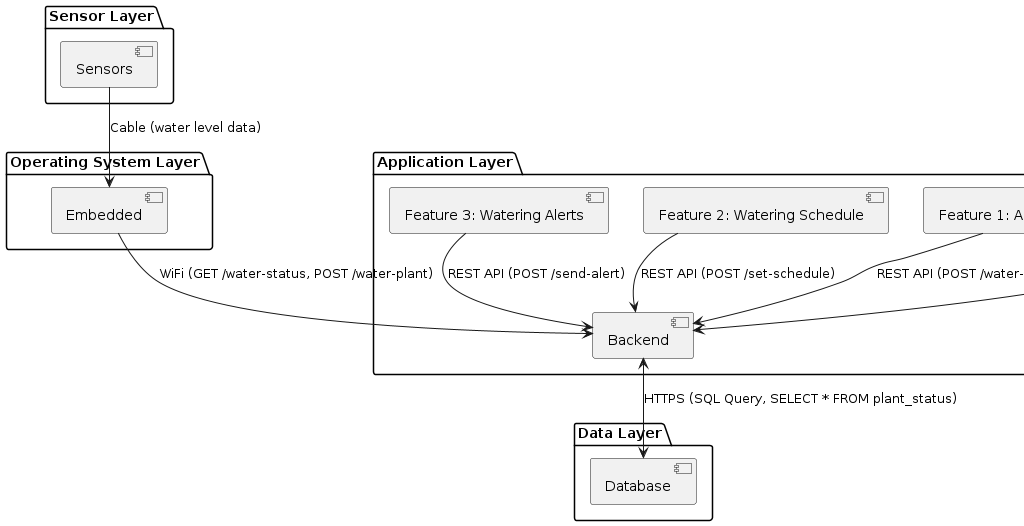
Database SQL Injection
What Is SQL Injection?
- Attacker manipulates SQL queries via user input
- Can expose, modify, or delete data
- Common in apps that use unsafe query building
Vulnerable Python Example
user = input("Enter username: ")
query = f"SELECT * FROM users WHERE name = '{user}'"
cursor.execute(query)
Injection Attack Example
Input: alice' OR '1'='1
Query: SELECT * FROM users WHERE name = 'alice' OR '1'='1'
Bypasses authentication and returns all users
Safe Python Example (Parameterized)
user = input("Enter username: ")
query = "SELECT * FROM users WHERE name = %s"
cursor.execute(query, (user,))
Using parameters prevents SQL injection
SQL Injection Prevention Tips
- Always use parameterized queries
- Never concatenate raw input into SQL
- Use ORM libraries (e.g., SQLAlchemy, Django ORM)
- Sanitize and validate input when needed
Database Query Log
Why Log SQL Queries?
- Track suspicious or slow queries
- Monitor access patterns
- Detect SQL injection attempts
- Improve performance and security
Basic Logging in Python
import logging
logging.basicConfig(level=logging.INFO)
query = "SELECT * FROM patients"
logging.info(f"Running query: {query}")
cursor.execute(query)
Logging Query with Parameters
query = "SELECT * FROM patients WHERE name = %s"
params = ("Alice",)
logging.info("Query: %s | Params: %s", query, params)
cursor.execute(query, params)
Enabling SQL Logs in Databases
- PostgreSQL:
log_statement = 'all' - MySQL/MariaDB:
general_log = ON - SQLite: Use logging in wrapper code
Best Practices for Query Logging
- Mask sensitive values in logs (e.g., passwords)
- Use rotating log files to manage size
- Centralize logs for analysis (e.g., ELK stack)
- Correlate with user actions for traceability
Questions
Which model develops more secure software?
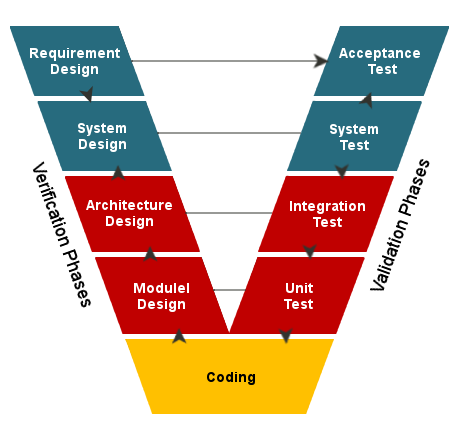

Case Study 1: Unauthorized Device Access
An IoT-enabled Light Sensor App is compromised when a hacker gains access to a user's device and manipulates watering schedules. The device was not properly secured and had default credentials. What security measure would have reduced the risk?
Case Study 2: Abnormal Usage Patterns
The Light Sensor App detects an unusual spike in watering requests from a single account, causing overwatering and potential damage to plants. What monitoring or anomaly detection strategy should be implemented?
Questions
Point-to-Point Security
Market Share of IoT Connectivity Technologies
| Connectivity Technology | Market Share (%) |
|---|---|
| Wi-Fi | 31% |
| Bluetooth | Approximately 27% |
| Cellular IoT (2G, 3G, 4G, 5G, LTE-M, NB-IoT) | Approximately 22% |
| Other Technologies (e.g., Zigbee, LoRa) | Approximately 20% |
Bluetooth Security by Versions
| Bluetooth Version | Release Year | Security Features |
|---|---|---|
| Bluetooth 1.0 & 1.0B | 1999 | Basic encryption (weak security), no pairing method |
| Bluetooth 2.0 + EDR | 2004 | Improved Data Rate, basic encryption and pairing |
| Bluetooth 3.0 + HS | 2009 | High-Speed transfer, improved security with AES encryption |
| Bluetooth 4.0 & 4.1 | 2010 & 2013 | Low Energy (LE) with stronger encryption, secure simple pairing |
| Bluetooth 4.2 | 2014 | Improved security with better privacy features, improved LE encryption |
| Bluetooth 5.0 & 5.1 | 2016 & 2019 | Improved range and connection security, more robust LE encryption |
| Bluetooth 5.2 | 2020 | Support for LE Audio, improved encryption, and secure data transfer |
Case Study: Point-to-Point Connectivity Security Breach
A plant watering system’s point-to-point Wi-Fi connection was compromised, allowing attackers to intercept and manipulate watering data. This disruption caused the system to water plants incorrectly. What security measures should have been implemented?
Relational Database Security Implementation
- Database Encryption PostgreSQL
- Diffie-Hellman Key Exchange
- Database Access Control
- Data Logging
- Pen Testing
- Software Vulnerabilities and Patches
- IoT Case Study
Database Encryption PostgreSQL
Create Extension
CREATE EXTENSION IF NOT EXISTS pgcrypto;
PGP Encryption
| Technical Aspect | PGP Encryption (Asymmetric) | Symmetric Encryption (AES, DES) |
|---|---|---|
| Key Type | Public-Private Key Pair | Single Shared Secret Key |
| Encryption Speed | Slower; computationally intensive | Faster; suitable for large data |
| Key Management | Complex; public key distribution required | Simpler; secure key sharing essential |
| Security Strength | High; secure over insecure channels | Medium to High; risk if key compromised |
| Use Case Examples | Email encryption, digital signatures | File encryption, database encryption |
Reference: PostgreSQL pgcrypto Documentation
Drop Table
DROP TABLE secure_data;
Create Table
CREATE TABLE IF NOT EXISTS secure_data(
id SERIAL PRIMARY KEY,
sensitive_info BYTEA NOT NULL
);
Insert Encrypted Data
INSERT INTO secure_data (sensitive_info)
VALUES (pgp_sym_encrypt('Secret Information', 'my_strong_password'));
Select Encrypted Data
SELECT id, ENCODE(sensitive_info, 'hex') AS encrypted_info
FROM secure_data;
Decrypt Data
SELECT id, pgp_sym_decrypt(sensitive_info, 'my_strong_password')
AS decrypted_info
FROM secure_data;
Diffie-Hellman Key Exchange
Key Concept: Diffie-Hellman allows two parties to establish a shared secret over an insecure channel, used for symmetric key encryption

Database Hashing PostgreSQL
Hashing vs. Encryption
- Hashing: One-way, irreversible; used for password storage and verification
- Encryption: Two-way, reversible; protects sensitive data, allows secure retrieval
Create User with SCRAM-SHA-256
SET password_encryption = 'scram-sha-256';
CREATE ROLE username WITH LOGIN PASSWORD 'your_secure_password';
List All Users and Roles
SELECT rolname, rolsuper, rolcreaterole, rolcreatedb, rolcanlogin
FROM pg_roles;
Create User with MD5 (Legacy)
SET password_encryption = 'md5';
CREATE ROLE username WITH LOGIN PASSWORD 'your_secure_password';
Database IP-Based (Network) Access Control PostgreSQL
Questions
Database User-Based Access Control
Create Users (Flower Store)
CREATE USER Bob PASSWORD 'bob_pass_123!';
CREATE USER Alice PASSWORD 'alice_pass_123!';
Grant Permissions to Users
-- Grant full access to Bob
GRANT ALL PRIVILEGES ON Flowers TO Bob;
-- Grant read-only access to Alice
GRANT SELECT ON Flowers TO Alice;
List and Switch Users
-- Show all users and roles
SELECT rolname FROM pg_roles;
-- Switch user temporarily
SET ROLE Alice;
-- Switch back
RESET ROLE;
Test Queries with User Permissions
-- Switch to user 'Alice' (read-only)
SET ROLE Alice;
-- Successful query (Alice can SELECT)
SELECT * FROM flowers;
-- Failed query (Alice cannot DELETE)
DELETE FROM flowers WHERE id = 1;
RESET ROLE;
-- Switch to user 'bob' (full access)
SET ROLE Bob;
-- Successful query (Bob can DELETE)
DELETE FROM flowers WHERE id = 1;
RESET ROLE;
Revoke User Access
REVOKE INSERT ON flowers FROM Bob;
Questions
Database Role-Based Access Control
Create Roles
CREATE ROLE viewer;
CREATE ROLE manager;
Create Users and Assign Roles
CREATE USER alice PASSWORD 'alice_pass';
CREATE USER bob PASSWORD 'bob_pass';
GRANT viewer TO alice;
GRANT manager TO bob;
Grant Permissions to Roles
GRANT SELECT ON flowers_core TO viewer;
GRANT SELECT, INSERT, UPDATE ON flowers_pricing TO manager;
Test Role-Based Access
GRANT alice TO current_user;
SET ROLE alice;
SELECT * FROM flowers_core;
SELECT * FROM flowers_pricing;
RESET ROLE;
Questions
Database Fragmentation
Split Table: Core Info
CREATE TABLE flowers_core (
id INTEGER PRIMARY KEY,
name TEXT
);
Split Table: Pricing Info
CREATE TABLE flowers_pricing (
id INTEGER PRIMARY KEY,
price REAL
);
Insert Fragmented Data
INSERT INTO flowers_core (id, name) VALUES (1, 'Rose');
INSERT INTO flowers_pricing (id, price) VALUES (1, 2.99);
Assign Access to Users
GRANT SELECT ON flowers_core TO viewer;
GRANT SELECT, INSERT, UPDATE ON flowers_pricing TO manager;
Questions
Database SQL Parameterized
Safe SQLite Parameter
github.com/SE4CPS/DMS/sql-param.py
Database Query Log PostgreSQL and SQLite
| Technical Area | Importance of Logging |
|---|---|
| Query Performance | Identify slow queries and optimize them |
| Security | Track unauthorized access attempts |
| Error Diagnosis | Understand and debug failed operations |
| Auditing | Maintain compliance and trace changes |
| Replication & Backup | Ensure consistency and troubleshoot issues |
-- In postgresql.conf:
logging_collector = on
log_directory = 'log'
log_filename = 'postgresql-%Y-%m-%d.log'
log_statement = 'all'
log_min_error_statement = error
log_min_messages = warning
Grant Access and Test as Alice
GRANT USAGE ON SCHEMA public TO Alice;
GRANT SELECT ON team1_flowers TO Alice;
-- GRANT ALL PRIVILEGES ON team1_flowers TO Alice;
GRANT Alice TO current_user;
SET ROLE Alice;
SELECT * FROM team1_flowers;
RESET ROLE;
SQLite Query Logs - Option 1
sqlite3 mydatabase.db
.echo ON
.tables
.schema
SQLite Query Logs - Option 2
sqlite3 mydatabase.db
.echo ON
.output my_log.txt
.schema
Questions
Database Encryption SQLCipher
Why Encrypted SQLite?
- Mobile: Android, iOS smartphones and tablets
- Wearables: Smartwatches, fitness trackers
- Smart TV: Securing user preferences and viewing history
- Desktop: Windows, macOS, Linux apps
- Compliance: Ensures GDPR, HIPAA, and security standards compliance
Clone SQLCipher Repository
SQLCipher Encryption
| Technical Aspect | SQLCipher | Standard SQLite |
|---|---|---|
| Encryption Method | Transparent AES-256 Encryption | No built-in encryption |
| Data-at-rest Security | Strong; protects database files on disk | Weak; plaintext data storage |
| Performance Impact | Moderate overhead due to encryption operations | Minimal; faster access (unencrypted) |
| Use Cases | Mobile apps, sensitive data storage | General-purpose lightweight storage |
| Key Management | Application-managed passphrase | Not applicable |
Reference: SQLCipher GitHub Documentation
Encrypting with SQLCipher
sqlcipher mydatabase.db
sqlite> PRAGMA key = 'your_secure_password';
sqlite> CREATE TABLE flowers(id INTEGER, name TEXT);
sqlite> INSERT INTO flowers VALUES (1, 'Rose');
sqlite> .quit
Questions
⚠️ No Access Control in SQLite
- SQLite does not support user roles or permissions
- Anyone with access to the database file has full control
- No built-in authentication or authorization
- Use OS-level file permissions or encryption (e.g., SQLCipher) for protection
Penetration Testing
Phases of Penetration Testing
- Planning and Reconnaissance: Gathering information about the target
- Scanning: Identifying vulnerabilities
- Exploitation: Attempting to exploit discovered vulnerabilities
- Post-Exploitation: Assessing the impact of the exploit
- Reporting: Documenting findings and recommendations
Common Penetration Testing Tools
- Metasploit: Used for discovering and exploiting vulnerabilities
- Nmap: Network scanning tool for identifying open ports
- Burp Suite: Used for testing web application security
- Wireshark: Network protocol analyzer for monitoring traffic
Penetration Testing Standards
- OWASP Testing Guide: A comprehensive guide for testing web application security
- PTES (Penetration Testing Execution Standard): Defines the processes and methodologies for performing penetration tests
- OSSTMM (Open Source Security Testing Methodology Manual): Provides a detailed methodology for security testing
- CREST: A professional certification and standards organization for penetration testers
Agenda
- Vulnerabilities & patches
- Zero-day risks
- Secure updates
- Export control (mobile)
- Obfuscation limits

Software Vulnerabilities and Patches
| Term | Description | Example |
|---|---|---|
| Vulnerability | A weakness in a system, application, or network that can be exploited by attackers. | Buffer overflow, SQL injection, Cross-Site Scripting (XSS). |
| Zero-Day Vulnerability | A security flaw that is exploited before the vendor has issued a patch or fix. | Stuxnet worm exploited multiple zero-day vulnerabilities in Siemens SCADA systems. |
| Zero-Day Attack | An attack that targets a zero-day vulnerability, often before it is discovered by the vendor. | Exploiting an unknown flaw in a browser before the vendor releases a patch. |
| Patch | A software update designed to fix vulnerabilities, bugs, or other issues in a system or application. | Security patch to fix a vulnerability in Windows OS. |
| Patch Management | The process of acquiring, testing, and deploying patches to systems and applications. | Regular updates to fix known vulnerabilities in server software. |
| CVE (Common Vulnerabilities and Exposures) | A publicly disclosed list of known cybersecurity vulnerabilities, each assigned a unique identifier. | CVE-2021-34527: Microsoft PrintNightmare vulnerability. |
| Exploit | A piece of software or code that takes advantage of a vulnerability to cause unintended behavior. | Exploiting a buffer overflow to gain remote code execution. |
| Vulnerability Scanner | Tools used to identify potential vulnerabilities in systems, applications, or networks. | Nessus, OpenVAS, Qualys. |
| Security Advisory | A notification from the vendor or organization about a discovered vulnerability and available patches. | Microsoft Security Advisory for the Windows SMBv1 vulnerability. |
| Security Flaw | A weakness or defect in a system or software that can be exploited to cause harm. | Outdated cryptographic algorithms in a secure communication protocol. |
| Security Update | An update aimed specifically at fixing security-related vulnerabilities. | Update to fix a vulnerability in Apache web server's SSL/TLS configuration. |
Why Are Software Updates Critical?
- Fix security flaws and prevent exploits
- Patch vulnerabilities before attackers exploit them
- Improve performance and compatibility
Zero-Day Vulnerabilities
A security flaw unknown to the vendor, leaving systems exposed until a patch is released.
- Attackers exploit before a fix exists
- Used in ransomware, espionage, and malware
- Examples: Stuxnet, Log4Shell, MOVEit breach
Secure Software Update Strategies
- Digitally sign updates to prevent tampering
- Implement rollback protection
- Use over-the-air (OTupdates securely
- Regularly scan for vulnerabilities
Export Control for IoT Apps
Export Control for IoT Apps
- Android / iOS
- Control access
- Protect flow
- End-to-end
{
"deviceId": "LS-1001",
"lux": 320
}Meaning in Mobile Apps
- Limit distribution
- Gate features
- Check region
- Secure updates
val sensor = sensorManager
.getDefaultSensor(Sensor.TYPE_LIGHT)Risk Areas
- Embedded logic
- Offline mode
- Device control
- Data leaks
func readLux(v: Float) {
print(v)
}Android Controls
- Restrict region
- Feature flags
- Check device
- Secure APK
val req = mapOf("lux" to 320)
api.post("/sensor", req)iOS Controls
- Region gating
- Server checks
- Secure store
- Controlled deploy
let body = ["lux": 320]
post("/sensor", body)Data and Encryption
- Encrypt data
- No hardcoding
- Min client logic
- Use backend
fetch("https://api/app/sensor", {
method: "POST"
})Access Control
- User check
- Role control
- Region filter
- Audit logs
if(user.region != "US"){
denyAccess()
}Code Obfuscation
- Hide logic
- Rename code
- Protect strings
- Raise effort
a.b(c){
return d+e;
}Limits of Obfuscation
- Not enough alone
- Still reversible
- No key safety
- Needs backend
const key = "SECRET123"Recommended Architecture
- Classify features
- Backend control
- Use flags
- Log access
// flow
App → API → Auth → DeviceIoT Case Study
Case Study: Accidental App Release
- Junior dev published dev app
- Wrong region enabled
- Not part of target market
- 5 unexpected downloads seen
- App includes IoT + sensor features
- App includes personal data
- Backend APIs are active
- No regional restriction enforced
- Possible export control impact
- Unknown user access
- What should be done?

Case Study: Greenhouse Monitoring
IoT sensors track soil moisture and sync data from on-device SQLite to a PostgreSQL server.
- How can sensor data be secured against tampering?
- What redundancy prevents data loss during connectivity issues?
Case Study: Smart Flower Delivery
Orders are tracked in PostgreSQL, while IoT delivery boxes log temperature and humidity.
- How can shipment data be encrypted?
- What access control prevents unauthorized tracking?
Case Study: Unauthorized Smart Home Access
A smart thermostat was remotely accessed without user consent.
What authentication and logging controls should prevent this?
Case Study: Tampered IoT Updates
An attacker replaced an IoT device’s firmware update with malicious code.
How should update mechanisms be secured?
Agenda
- 1. Safety requirements in IoT systems
- 2. Hazard analysis & risk modeling
- 3. Model-driven development (MDD) overview
- 4. UML for safety (use case, sequence, state diagrams)
- 5. Traceability: requirements → models → code
- 6. Code generation & safe implementation
- 7. Verification & validation (testing safety paths)
- 8. Secure & safe software updates in IoT

Safety (Accidental Harm)
- 1. Sensor failure → light stays OFF in dark
- 2. Wrong threshold → unsafe visibility
- 3. Timing delay → late activation
- 4. Fail-safe: default light ON if sensor fails
- 5. Goal: prevent accidents (e.g., people tripping)
Security (Intentional Harm)
- 1. Attacker disables sensor remotely
- 2. Unauthorized access to control light
- 3. Fake sensor data injected
- 4. Protection: authentication & encryption
- 5. Goal: prevent misuse or takeover
Recent Press: Software Safety Issues in IoT-like Systems
-
1. Ford trailer software recall
→ brake lights & signals may fail → crash risk
Read article -
2. Ford/Lincoln SUVs recall
→ rearview camera & ADAS disabled → reduced visibility
Read article -
3. iPhone MMS issue
→ messages not downloading → communication failure
Read article
- 1. Incorrect light readings → staff assume room is safe when it is dark
- 2. Missing data → monitoring system shows room as normal
- 3. Delayed readings → late awareness of unsafe lighting
- 4. Sensor drift → gradual misinterpretation of lighting conditions
- 5. Dashboard error → wrong room status displayed
- 6. Sensor reading deletes hospital database
- 7. Light data changes medication dosage automatically
- 8. Sensor reading reprograms medical devices
- 9. Light monitoring alters patient identity records
- 10. Sensor converts light data into billing charges

Access Control → Safety Across Domains
- Healthcare (Hospital IoT)
1. Only authorized staff access patient room data → prevents wrong decisions - Automotive (Connected Vehicles)
2. Only trusted software updates allowed → prevents unsafe vehicle behavior - Smart Home
3. Only residents control lighting/heating → avoids unsafe environments - Industrial IoT (Factories)
4. Restricted access to monitoring dashboards → prevents misinterpretation of hazards - Aviation Systems
5. Only certified systems/users access control data → ensures safe flight operations
Safety First in IoT Software Process
- 1. Safety begins at requirements (first step)
- 2. Early hazard identification prevents later failures
- 3. Models (UML) must include safety constraints
- 4. Code inherits safety from well-defined models
- 5. Late fixes are costly and unreliable
Module 12
Software Release Process in Industry 4.0
Delivering, updating, and maintaining systems in continuous operation.
Software Release Process in Industry 4.0
- Alpha, Beta, and Gamma testing
- Release channels (App Store, .apk)
- Staged releases and rollbacks
- Feedback channels and user analytics
- V-Process model for validation and verification
- Continuous Integration & Continuous Deployment (CI/CD)
- Over-the-Air (OTupdates for IoT devices
- Canary releases for risk mitigation
- Security & compliance checks (IEC 62443, NIST guidelines)
- Digital Twin testing for virtual release simulation
Alpha, Beta, and Gamma Testing
| Testing Type | Environment | Testers | Purpose |
|---|---|---|---|
| Alpha Testing | In-house (Lab environment) | Developers & Internal QA | Detect major bugs before external release |
| Beta Testing | Limited real-world environment | End-users (selected group) | Gather user feedback & identify usability issues |
| Gamma Testing | Final pre-release stage | End-users (public or wider audience) | Ensure system stability before full deployment |
Release Channels
- App Store (iOS)
- Google Play Store (Android)
- Direct .apk Distribution
- Enterprise App Stores
- Third-Party Marketplaces

Staged Releases
- Gradual rollout to a small percentage of users
- Monitor performance and user feedback
- Increase availability in controlled steps
- Rollback if critical issues arise
- Ensures stability before full deployment
Feedback Channels and User Analytics
- Surveys and Comment Forms
- In-app feedback options
- Real-time analytics and usage data
- Customer support interactions
- User reviews and ratings
V-Process Model for Validation and Verification
- Requirements Analysis: N/A
- System Design: Early releases for architecture validation
- High-Level Design: Component integration and unit tests
- Low-Level Design: Functional and system testing releases
- Implementation: Weekly sprint releases and unit testing
- Unit Testing: Unit test releases and feedback collection
- Integration Testing: Component and integration testing releases
- System Testing: Full system test releases and validation
- User Acceptance Testing (UAT): Final user testing release before production
- Deployment: Final deployment release after UAT validation
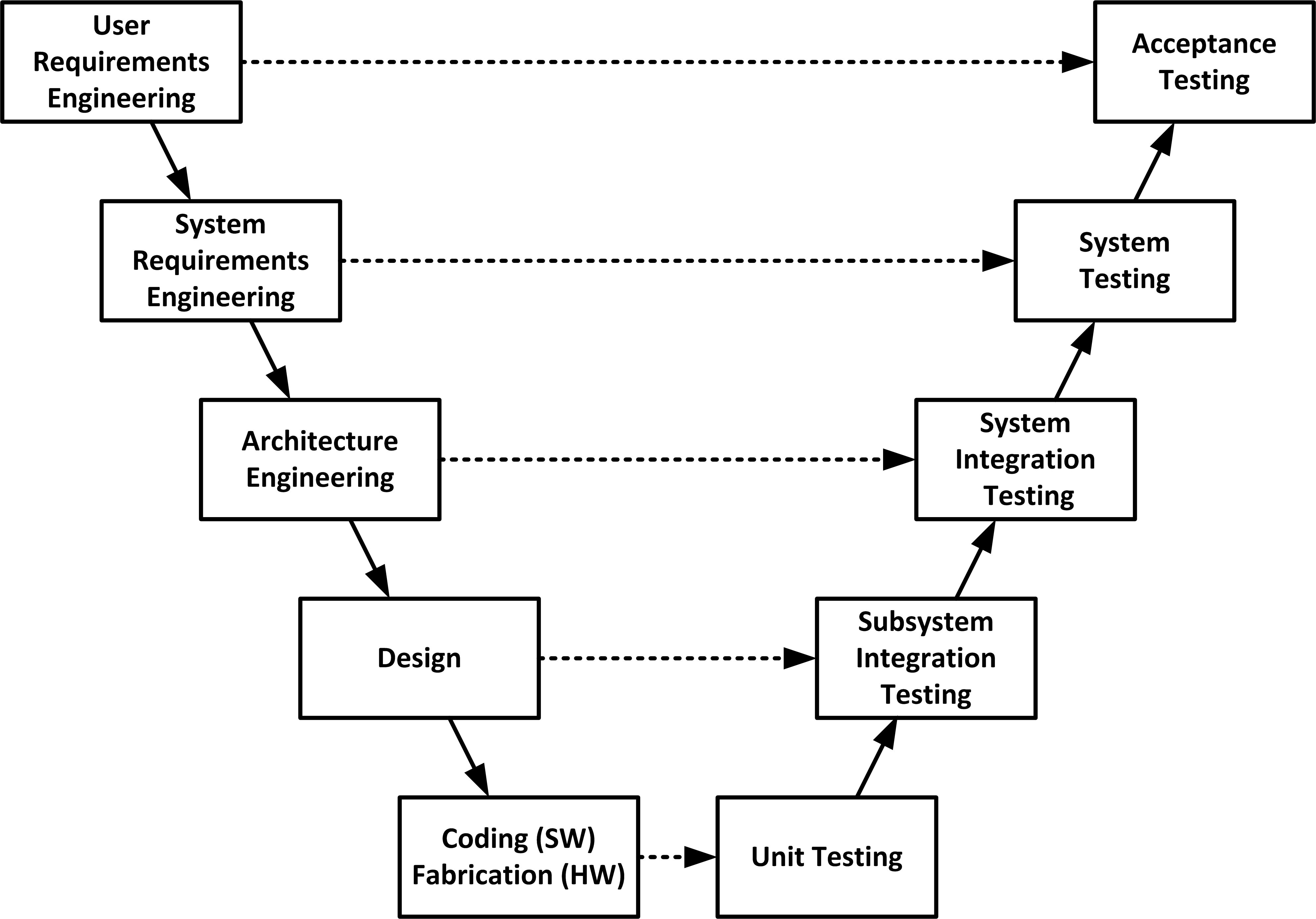
Continuous Integration & Continuous Deployment (CI/CD)
- Frequent, automated builds and testing
- Quick release cycle (sometimes multiple per day)
- Automated deployment to production after successful tests
- Helps ensure constant code quality and fast feedback
Semantic Release
- Semantic Release automates version management and package publishing based on the commit messages
- Automates the process of determining the next version number based on the commit history
- Uses **Conventional Commits** to determine version increments:
- Major: Breaking changes
- Minor: New features
- Patch: Bug fixes
- Automatically generates changelogs and publishes to the registry
Automatic Updates
Manual Updates
Ignore Updates
Over-the-Air (OTUpdates for IoT Devices
- OTA Updates allow remote firmware updates for IoT devices without requiring physical access
- Enables automatic or manual updates over a network connection (Wi-Fi, cellular, etc.)
- Critical for maintaining the security, functionality, and performance of IoT devices
- Provides a reliable way to deploy bug fixes, feature enhancements, and security patches remotely
- Can be done incrementally or in bulk, depending on the device and update method

Manual Updates for IoT Devices
- Manual Updates require physical or manual intervention to install firmware updates on IoT devices
- Typically done through a USB drive, SD card, or direct connection to a computer or server
- Offers full control over when and how the update is applied
- Useful in situations where network access is limited or security concerns restrict OTA updates
- May require the device to be brought in for maintenance or servicing

Security & Compliance Checks
- IEC 62443 is a series of international standards focused on securing Industrial Automation and Control Systems (IACS)
- NIST Guidelines (e.g., NIST SP 800-53, NIST IR 8259provide cybersecurity frameworks for IoT devices and networks
- Both frameworks emphasize risk management, secure communication, and the protection of sensitive data in connected systems
- Regular security audits and compliance checks are crucial for maintaining system integrity and ensuring adherence to legal and industry standards
- Ensuring compliance with these standards helps prevent unauthorized access, data breaches, and other security risks in IoT systems
Digital Twin Testing for Virtual Release Simulation
- Digital Twin is a virtual representation of a physical device, system, or process that is used for testing, monitoring, and simulation
- It enables real-time simulation and testing of device behavior, performance, and responses to updates or changes in a controlled environment
- Helps in validating the impact of firmware updates or system changes before deploying them to physical devices
- Reduces risks by identifying potential issues or failures in the virtual environment before the actual deployment
- Can simulate complex systems and provide insights into performance, lifecycle, and behavior in real-world conditions
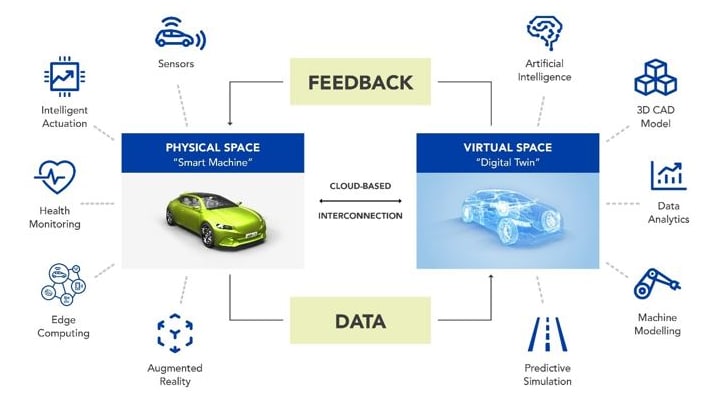
| Item | Light Sensor App |
|---|---|
| Alpha, Beta, and Gamma Testing | |
| Release Channels (App Store, .apk) | |
| Staged Releases and Rollbacks | |
| Feedback Channels and User Analytics | |
| V-Process Model for Validation and Verification | |
| Continuous Integration & Continuous Deployment (CI/CD) | |
| Over-the-Air (OTUpdates for IoT Devices | |
| Canary Releases for Risk Mitigation | |
| Security & Compliance Checks (IEC 62443, NIST Guidelines) | |
| Digital Twin Testing for Virtual Release Simulation |
Software Release Process in Industry 4.0
- Semantic Versioning in GitHub
- Release Notes with GH
- Staged Releases and Rollbacks
- Feedback Channels and User Analytics
Semantic Versioning in GitHub
Tagging versions for testing phases in IoT-Light-Sensor
v1.0.0-alpha- Alpha testingv1.0.0-beta- Beta testingv1.0.0-rc.1- Gamma (Release Candidate) testing
# Create and push an Alpha tag
git tag v1.0.0-alpha
git push origin v1.0.0-alpha
# Create and push a Beta tag
git tag v1.0.0-beta
git push origin v1.0.0-beta
# Create and push a Release Candidate (Gammtag
git tag v1.0.0-rc.1
git push origin v1.0.0-rc.1
Writing Release Notes in GitHub
📌 Create a Release
- Go to the repository: Light Sensor App Releases
- Click "Draft a new release"
- Enter a tag version (e.g.,
v1.0.0) - Add a title and detailed release notes
- Upload release assets (if needed)
- Click "Publish Release"
💻 Git CLI Commands
# Create a tag locally
git tag -a v1.0.0 -m "v1.0.0 - Alpha Release"
git push origin v1.0.0
# Create a GitHub release using GitHub CLI
gh release create v1.0.0 \
--title "Version 1.0.0" \
--notes "Initial alpha release of IoT-Light-Sensor."
Release Categories
- 🚀 Feature: New functionality added
- 🔧 Improvement: Enhancements or optimizations
- 🐛 Bug Fixing: Correcting issues or errors
- 🔒 Security Patch: Fixes for vulnerabilities
💻 GitHub CLI Command
gh release create v1.0.0 \
--title "v1.0.0 - Initial Release" \
--notes "Release Notes:
## 🚀 Features
- Added support for (#45)
- Implemented (#52)
## 🔧 Improvements
- Optimized sensor data
- UI for better usability
## 🐛 Bug Fixes
- Fixed API timeout issue (#60)
- Resolved UI bug in dashboard settings (#65)
## 🔒 Security Patch
- Patched vulnerability (#70)
Installation Methods
- Windows: Download the installer or use
winget - macOS: Use
brew install gh - Linux: Use
sudo apt install ghorbrew install gh
Verify
gh --version
Flask Backend - 10% Rollout
Backend Logic
- Generate random number between 0 and 1
- If ≤ 0.1, serve new feature (10% rollout)
- Otherwise, serve current feature
Python Code
from flask import Flask, jsonify
import random
app = Flask(__name__)
@app.route('/')
def homepage():
if random.random() <= 0.1:
return jsonify({"feature": "NewFeature"})
return jsonify({"feature": "CurrentFeature"})
app.run(debug=True)
Geographic Rollout (User Agent)
- Stage 1: Available in U.S
- Full Release: Global rollout
from flask import request
import geocoder
@app.route('/')
def check_geolocation():
g = geocoder.ip('me') # Get location based on IP
country = g.country
if country == 'United States':
# Stage 1: U.S. only
return "Feature available in U.S."
else:
# Full rollout
return "Feature available globally"
Geographic Rollout (Browser)
- Stage 1: Available in U.S
- Full Release: Global rollout
navigator.geolocation.getCurrentPosition(function(position) {
var lat = position.coords.latitude;
var lon = position.coords.longitude;
fetch(`https://api..?lat=${lat}&lng=${lon}`)
.then(response => response.json())
.then(data => {
if(data.countryName === 'United States') {
// Stage 1: Available in U.S.
console.log("Feature available in U.S.");
} else {
// Full release: Global rollout
console.log("Feature available globally.");
}
});
});Other Rollout Conditions
- Feature Flag Rollout
- User Role-based Rollout
- Device-based Rollout
- Time-based Rollout
- A/B Testing Rollout
- Canary Release Rollout
- ..
Users Feedback
- Go to the Issues tab
- Check for existing issues before submitting a new one
- Click "New Issue" and describe the problem or feature request
- Use clear titles and provide details
Example Issue
Title: "Watering schedule not triggering"
Description:
- Expected watering at 10 AM, but no action occurred.
- Soil moisture reading: 18% (should trigger watering).
- Logs show no errors.
Steps to reproduce:
1. Set watering threshold to 20%.
2. Wait for moisture to drop below 20%.
3. Observe no watering action.
How to Give Feedback
- Join the Slack workspace
- Go to the #feedback or relevant channel
- Describe your issue, suggestion, or question
- Tag relevant team members if needed
Feedback Channel
🚀 Feature Request
@dev-team Please add notification if soil moisture low?
Currently, users have to check manually.
🔍 Steps to reproduce:
1. Set up a plant with a low moisture threshold.
2. Observe that no notification is sent.
Monitored Data
- Page Views (e.g., how many times a page is viewed)
- Active Users (e.g., users currently on the site)
- Traffic Sources (e.g., search engines, direct visits, social media)
- User Behavior (e.g., time spent on pages, click events)
- Device & Location (e.g., mobile vs. desktop, geographic location)
- Bounce Rate (e.g., percentage of single-page visits)
- Conversion Rate (e.g., goal completions like sign-ups or purchases)
- New vs Returning Users (e.g., first-time vs. repeat visitors)
- Exit Pages (e.g., which page users leave the site from)
Insert This Code
<script src="googletagmanager.com/gtag/js?id=G-"></script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', 'G-XXXXXXXXXX'); // Replace with your GA ID
</script>
- HW + SW Integration and Release Process
- Quality vs Feature Scope
- Sprint Demo #9
Hardware Release Process in Industry 4.0

- No secrets on the device: Externalize sensitive data to avoid exposure
- Strict timeline: Ensure all integration steps are completed within deadlines
- Scalability: Plan for growth, ensuring the integration can handle increased load
- Monitoring and logging: Continuously track system performance and potential failures
- Compatibility: Ensure third-party hardware/software aligns with existing infrastructure.
- Security protocols: Use encryption and secure communication to protect data
- Version control: Manage updates and compatibility for seamless operation
- Integration risks: Potential issues with device failure, latency, compatibility, and security vulnerabilities
Data Volume Test

Today
Software Release Notes
- Software Version Baseline
- Security patches (CVEs)
- Community feedback signals
- Version changes (major / minor / patch)
- Risk identification in updates
Sprint Activities
- Sprint #9 Demo
- Sprint #9 Retrospective
- Sprint #10 Planning
Software Baseline
Baseline Items
- Source code version (tag/commit)
- Dependencies & libraries
- Configuration files
- Build artifacts (binaries, containers)
- Test cases & results
- Documentation
Version Examples
v1.2.0Git tag (stable release)requirements.txt,package.json.env, YAML configs- Docker image
app:1.2.0 - Unit test report (CI pipeline)
- Release notes & README
- Python baseline: 3.8+ (PyPy3 7.3.11+)
- Current backend: Python 3.10.12 (compatible)
System Version Baseline
| Component | Embedded System Version | Backend System Version |
|---|---|---|
| Operating System | ||
| Server | ||
| Programming Language (Python) | ||
| Programming Language (C/C++) | ||
| Database | ||
| API |
Versioning Exercise (Minor & Patch)
Scenario
- Current version:
1.0.0 - Two features added (no breaking changes)
- Five bug fixes
- What is the new version?
Answer
Versioning Exercise
Scenario
- Current version:
1.0.0 - One major API change
- New features added
- One bug fix
- What is the new version?
Answer
Releasing Order
Database
Backend
Frontend
Embedded
Communication Order
Internal
Developers / QA
Alpha
Internal testing
Beta
Selected users
External
Public users
Backward Compatibility
Key Principles
- New versions must support older clients
- Avoid breaking existing APIs
- Maintain stable data formats
- Deprecate features gradually
- Ensure safe upgrades without disruption
Examples
- API v2 still supports v1 requests
- Adding optional fields (no required changes)
- Database migrations preserve old schema
- Old firmware works with new backend
- Feature flags for gradual rollout
Release Notes vs Terms & Conditions
Release Notes
- What changed (features, fixes, patches)
- Version-specific information
- Technical details for developers
- Immediate impact of updates
- Short-term communication
Terms & Conditions
- Support lifecycle and duration
- User responsibilities and obligations
- Deprecation and upgrade policies
- Legal and compliance requirements
- Long-term expectations and guarantees
Support Lifecycle & Terms
What to Communicate
- Version support start and end dates
- Security patch availability window
- Upgrade and migration expectations
- Deprecation and sunset policy
- Responsibility of users vs provider
IoT Light Sensor Terms
This software version is supported for 12 months from release. During this period, security patches and critical bug fixes will be provided. After the support window, the version will be deprecated and no further updates will be issued. Users are responsible for upgrading to a supported version to maintain security and system reliability.
Sprint #9 Demo
Focus
- Show completed features
- Demonstrate working system
- Validate against requirements
- Highlight integration points
Artifacts
- Running application / demo
- Release notes summary
- Baseline version (vX.X.X)
- Test results / validation
Sprint #9 Retrospective
What Worked
- Successful features delivered
- Stable components
- Effective collaboration
What to Improve
- Integration issues
- Missed requirements
- Delays or bottlenecks
- Action items for next sprint
Sprint #10 Planning
Goals
- Define sprint objectives
- Select user stories
- Prioritize features
- Address risks
Planning
- Task breakdown
- Assign responsibilities
- Estimate effort
- Set sprint baseline
Automatic Release Notes Generation
Goals
- 1. Extract changes from commits, PRs, and issues
- 2. Classify updates (features, fixes, improvements)
- 3. Ensure consistent documentation format
- 4. Reduce manual effort and human error
Process
- 1. Collect data from version control (e.g., commit logs)
- 2. Apply rules or ML models for categorization
- 3. Generate structured summaries
- 4. Publish notes with each release cycle
Automatic Release Notes Generation
Concept
- 1. Generate release notes from repository activity
- 2. Use commit history between tagged releases
- 3. Reduce manual writing effort
- 4. Maintain consistent documentation
Commands
git fetch --tags
git log --oneline v0.9.0..v1.0.0
git tag
gh release view v1.0.0Repository Context
System Layers
- 1. Sensor → light ON/OFF events
- 2. Backend → processing and validation
- 3. Database → event storage
- 4. Frontend → visualization
- 5. Notification → alert rules
Release Sections
## Sensor
## Backend
## Database
## Frontend
## NotificationPrimary Inputs
Inputs
- 1. Commits between releases
- 2. Pull requests
- 3. Issues
- 4. Tags
Commands
git log --pretty=format:"%h %s"
gh pr list --state merged
gh issue list
git describe --tagsClassification of Changes
Categories
- 1. Features → new functionality
- 2. Fixes → bug corrections
- 3. Docs → documentation updates
- 4. Refactor → internal improvements
Commit Format
feat: add notification rule
fix: correct timestamp parsing
docs: update README
refactor: clean backend logicMapping to System Layers
Layer Mapping
- 1. Sensor → hardware interaction
- 2. Backend → API and logic
- 3. Database → schema and storage
- 4. Frontend → UI changes
- 5. Notification → alert system
Example Mapping
{
"app/": "Backend",
"dashboard/": "Frontend",
"twin/": "Digital Twin",
".github/workflows/": "CI/CD"
}Automation Script
Process
- 1. Extract commits between tags
- 2. Classify by prefix
- 3. Group by category
- 4. Output structured notes
Script
git log v0.9.0..v1.0.0 \
--pretty=format:"- %s" \
| grep "feat\|fix\|docs"GitHub Action Integration
CI/CD Integration
- 1. Trigger on tag creation
- 2. Run generation script
- 3. Publish release notes
- 4. Attach to GitHub Release
Workflow
on:
push:
tags:
- 'v*'
jobs:
release:
runs-on: ubuntu-latestExample Output
Release Notes
- 1. Feature: Added light duration alert
- 2. Fix: Corrected backend timestamp bug
- 3. Improvement: Faster dashboard updates
- 4. Refactor: Simplified event handling
Markdown Output
## Features
- Added light alert rule
## Fixes
- Fixed timestamp bug
## Improvements
- Optimized dashboardManual Release Workflow Overview
Concept
- 1. Release is triggered manually using workflow_dispatch
- 2. No automatic releases on push or PR
- 3. Full control over when a version is created
- 4. Ensures stable and deliberate releases
Trigger
on:
workflow_dispatch:Branch Control (Production Only)
Logic
- 1. Workflow can be started manually from any branch
- 2. Execution is restricted to production branch
- 3. Prevents accidental releases from development branches
- 4. Guarantees releases reflect deployed state
Condition
if: github.ref == 'refs/heads/production'Version Tag Computation
Process
- 1. Retrieve latest version tag
- 2. Default to v0.0.0 if none exists
- 3. Parse semantic version components
- 4. Increment patch version
Code
LAST_TAG="$(git tag --list 'v*' \
--sort=-version:refname | head -n 1)"
NEXT_TAG="v${MAJOR}.${MINOR}.$((PATCH + 1))"Tag Creation and Push
Steps
- 1. Configure Git identity for automation
- 2. Check if tag already exists
- 3. Create tag from current commit
- 4. Push tag to remote repository
Commands
git tag "$TAG" "${GITHUB_SHA}"
git push origin "$TAG"Release Notes Generation
Outcome
- 1. Create GitHub release from tag
- 2. Automatically generate release notes
- 3. Include commits and merged PRs
- 4. Maintain structured release history
Command
gh release create "$TAG" \
--generate-notes \
--latestSystem Components with Release Notes Integration
- Sensor captures environmental data
- Embedded system processes raw signals
- Backend manages logic and APIs
- Database stores system state and history
- Frontend visualizes system behavior
- Release notes summarize changes across all components
Automatic API Documentation
Automatic API Documentation
Concept
- 1. Generate API docs directly from code
- 2. Keep documentation synchronized with implementation
- 3. Reduce manual documentation effort
- 4. Improve consistency and accuracy
Example (OpenAPI)
{
"openapi": "3.0.0",
"paths": {
"/api/light": {
"get": {
"summary": "Get light status"
}
}
}
}Sources of API Documentation
Inputs
- Code annotations or decorators
- Route definitions in backend
- Data models and schemas
- Request and response structures
Example (Node.js)
app.get('/api/light', (req, res) => {
res.json({ status: "ON" });
});Documentation Generation Process
Steps
- Parse code or annotations
- Extract endpoints and parameters
- Build structured specification (OpenAPI)
- Render into human-readable format
Command
npx swagger-jsdoc -d config.js -o swagger.json
npx swagger-ui-expressIntegration with CI/CD
Automation
- Generate docs on each commit or release
- Validate API schema automatically
- Publish documentation artifacts
- Keep docs versioned with releases
Workflow Example
steps:
- run: npm install
- run: npm run generate-docs
- run: npm run deploy-docsBenefits of Automatic API Docs
Advantages
- Always up-to-date documentation
- Faster onboarding for developers
- Reduced maintenance cost
- Improved API reliability and testing
Output
GET /api/light
Response:
{
"status": "ON",
"timestamp": "2026-04-03T10:00:00Z"
}Automatic Monitoring
Monitoring Uptime & Slack Alert Notifications
Concept
- 1. Continuously monitor system uptime and availability
- 2. Detect failures or abnormal behavior in services
- 3. Trigger alerts when thresholds are violated
- 4. Notify teams in real-time via Slack
Key Components
- 1. Health checks (API / endpoint monitoring)
- 2. Monitoring tools (cron, uptime services)
- 3. Alert rules (timeouts, failures)
- 4. Notification channel (Slack webhook)
Example (Slack Webhook)
curl -X POST $SLACK_WEBHOOK \
-H 'Content-type: application/json' \
--data '{
"text": "🚨 Backend is DOWN"
}'Example (Health Check)
curl -f https://api.example.com/health \
|| curl -X POST $SLACK_WEBHOOK \
--data '{"text":"API Failure"}'Example (Cron Job)
*/5 * * * * /scripts/health-check.shLogging Error/Crash Logs
Sample JSON Logs (UTC Timestamp)
Sensor
{
"component": "sensor",
"timestamp": "2026-04-03T18:25:43Z",
"level": "error",
"message": "Light sensor read failure",
"device_id": "sensor-001"
}Embedded
{
"component": "embedded",
"timestamp": "2026-04-03T18:25:45Z",
"level": "error",
"message": "GPIO interrupt timeout",
"firmware_version": "1.2.0"
}Backend
{
"component": "backend",
"timestamp": "2026-04-03T18:25:47Z",
"level": "error",
"message": "Database connection failed",
"endpoint": "/api/light",
"status_code": 500
}Frontend
{
"component": "frontend",
"timestamp": "2026-04-03T18:25:50Z",
"level": "error",
"message": "Failed to fetch API data",
"url": "/api/light",
"browser": "Chrome"
}System Error Timeline (UTC)
Sensor
Read failure
Embedded
GPIO timeout
Backend
DB failure
Frontend
API fetch error
Exception Handling and Logging with Try-Catch
Process
- Wrap critical operations in try block
- Catch exceptions using except block
- Capture error details (message, type, timestamp)
- Send structured log to central logging endpoint
- Decide recovery action (retry, fallback, fail gracefully)
Python Example
LOG_ENDPOINT = "https://iot-light-sensor..."
def send_log(error_message):
log = {
"component": "backend",
"timestamp": datetime.utcnow().isoformat() + "Z",
"level": "error",
"message": error_message
}
requests.post(LOG_ENDPOINT, json=log)
try:
response = requests.get("https://iot-light...")
response.raise_for_status()
except Exception as e:
send_log(str(e))
# decide how to proceedModule 13
Integrating AI with Industry 4.0 Ecosystems
How AI supports building and running an IoT indoor light monitoring system.
The IoT Indoor Light Monitoring System
- Reads lux levels and occupancy per room
- Sends sensor data to backend every 5 seconds
- Stores all readings in a time series database
- Displays live readings on a web dashboard
- Shows historical trends per Room per day
- No actuation: monitor and display only
AI Supports Two Things
- The process: how the team builds the system
- The product: what the system shows the user
- Process AI helps developers write, test and debug code
- Product AI helps users understand sensor data faster
- Both roles are active at the same time
- Neither requires changing the sensor hardware
AI for the Process: LLM as Coding Assistant
- Dev types a prompt; LLM generates sensor driver code
- LLM explains unfamiliar library functions on demand
- Suggests fixes when the lux reading returns null
- Generates MongoDB schema from a plain English description
- Tools: GitHub Copilot, Claude, ChatGPT inside the IDE
-- Developer prompt to LLM:
"Write a Python function that reads
lux from a BH1750 sensor on ESP32
and posts JSON to /api/reading"
-- LLM generates:
def read_and_post(room_id):
lux = bh1750.read()
requests.post("/api/reading", json={
"room": room_id,
"lux": lux,
"ts": time.time()
})
AI for the Process: Automated Test Generation
- Describe the function; LLM writes the unit tests
- Covers happy path and edge cases automatically
- Tests null readings, out of range lux, network failure
- Reduces time spent writing repetitive test scaffolding
- Works for embedded, backend and frontend layers
- Human still reviews and approves each generated test
def test_valid_lux_posts_correctly():
mock_post(status=200)
read_and_post("room_a")
assert last_post["lux"] > 0
def test_null_lux_is_skipped():
mock_sensor(returns=None)
result = read_and_post("room_a")
assert result is None
def test_network_failure_is_logged():
mock_post(raises=ConnectionError)
read_and_post("room_a")
assert "error" in log.last()
AI for the Process: Docs and Code Review
- LLM reads a function and writes its docstring
- Generates a README from the folder structure
- Reviews a pull request and flags logic issues
- Explains why a sensor reading drifts over time
- Produces architecture diagrams from code descriptions
- Keeps documentation in sync as code changes
AI for the Product: Anomaly Detection
- ML baseline learns normal lux range per Room per hour
- Flags a Room reading 3x above or below the baseline
- Example: Room B at 2 lux at 10am: sensor fault likely
- Example: Room A at 900 lux in a windowless room
- Alert shown on dashboard with Room and timestamp
- Algorithm: Isolation Forest on MongoDB time series
AI for the Product: Occupancy Prediction
- ML model trained on PIR and lux history per room
- Predicts whether a Room will be occupied next hour
- Prediction shown on dashboard as a confidence badge
- Helps building manager plan maintenance visits
- Features: hour of day, day of week, recent motion count
- Model: lightweight Random Forest retrained each week
AI for the Product: Natural Language Queries
- User types a plain English question on the dashboard
- LLM translates it to an MongoDB query automatically
- Returns a readable answer with the actual numbers
- No SQL knowledge needed by the building manager
- Every query is logged for audit and improvement
AI for the Product: RAG Grounds the LLM
- LLM alone cannot see live sensor readings
- RAG retrieves fresh MongoDB data into the prompt
- LLM answer is grounded in real readings not guesses
- Knowledge base also holds ISO lux standards and manuals
- Query: "Is Room C lux compliant with ISO 9241?" works
- Stays accurate without retraining when readings change
AI for the Product: Daily Summary Generation
- At end of day LLM reads all Room readings from MongoDB
- Produces a plain English summary of the day automatically
- Highlights which rooms had anomalies or unusual trends
- Compares today against the 7 day average per room
- Summary appears on dashboard and can be exported
- No human effort needed to write the daily report
AI in the Full Picture
- Process AI accelerates every V-Model phase
- Product AI makes the dashboard more intelligent
- Neither requires changing sensor hardware
- Both use the same underlying LLM technology
- Start with one use case: add more incrementally
- Human remains in the loop for all decisions
V-Model: AI Touches Every Phase
- Requirements: LLM drafts user stories from notes
- System Design: LLM compares architecture options
- Arch. Design: LLM generates sequence diagrams
- Module Design: LLM suggests data model schema
- Coding: LLM writes sensor driver and API code
- Unit Testing: LLM generates test cases per function
- Integration: LLM explains why pipeline breaks
- System Testing: ML model validated on held out data
- Acceptance: LLM checks requirements are all met
Questions?
Sample Final Exam
Sample Final Exam
- Covers all 13 modules of the semester
- Mix of scenario questions and design questions
- Focus on IoT pipeline and V-Model phases
- Focus on choosing the right AI layer for a problem
- Download: Final Sample 1
- Download: Final Sample 2
Sample Question 1: Architecture
- A lux sensor sends readings every 5 seconds
- A building manager views a live dashboard
- Draw and label the full system architecture
- Name the database type most suitable for this data
- Where would you place an ML model in this pipeline?
Sample Question 2: V-Model
- You are testing the lux sensor driver module
- Which V-Model phase does this belong to?
- What does the corresponding design phase produce?
- Write one test case for a null lux reading
- At which phase would you test the full pipeline?
- What is the acceptance criterion for the dashboard?
Sample Question 3: Choosing the AI Layer
- For each scenario choose the best AI technique
- A: Room B always shows wrong lux on Monday mornings
- B: Manager asks "What was the peak lux in Room A today?"
- C: Dashboard should warn before a sensor reading drifts
- D: Report must cite the ISO 9241 standard for each room
Sample Question 4: Design Scenario
- Design the AI layer for the light monitoring dashboard
- Users are non-technical building managers
- They need answers without writing any SQL
- They need to know when a sensor reading is unusual
- Draw the architecture and label each AI component
- Justify each AI choice in one sentence per component
Sample Question 5: Process AI in V-Model
- You are at the Unit Testing phase
- Your sensor driver function reads lux and posts to API
- How can an LLM assist at this phase specifically?
- Write the prompt you would give to the LLM
- What would you check before accepting LLM tests?
- What human judgment is still required here?
-- Your prompt to the LLM:
"Write pytest unit tests for this function.
Cover: normal lux value, null return,
network timeout, and lux above 65000."
-- LLM generates 4 test functions.
-- You review each one and check:
- does the test assert the right thing?
- does the mock match the real interface?
- is the edge case realistic?
-- Human judgment still needed:
- are these the right edge cases?
- does the test reflect real hardware?
Questions?
Sprint 10
Sprint #10 Goal
- Sensor reads lux and occupancy every 5 seconds
- Edge node sends JSON payload to backend
- Backend validates and writes to MongoDB
- Dashboard shows live lux value per room
- Dashboard shows occupancy status per room
- All two rooms visible on one screen simultaneously
Code Review
| Embedded | BH1750_sensor2.ino |
| Backend | app.py |
| Frontend | dashboard.html |
Product and Product Validation
- Did we implement, test, and link requirements?
- Did we implement, test, and link architecture?
- Did we implement, test, and link software?
LLM in V-Model: Help Building Apps
- Requirements: LLM drafts user stories from meeting notes
- System Design: LLM compares InfluxDB vs MongoDB for lux data
- Module Design: LLM proposes BH1750 driver interface contract
- Coding: LLM writes the ESP32 lux POST function
- Unit Testing: LLM generates pytest cases for null lux readings
- Acceptance: LLM checks all requirements are traceable in code
LLM in GitHub Copilot:Writing the Light Sensor Code
- GitHub Copilot is an LLM embedded directly in the IDE
- Dev opens the ESP32 sketch:Copilot reads the full file
- Prompt: "add BH1750 lux read and POST to /api/reading"
- Copilot generates the function with correct library calls
- Copilot Chat explains why
Wire.begin()must come first - Saves ~2 hours of reading datasheet and library docs
Real session: github.com/copilot/c/f2d66782...
Propose a LLM Chat Prompt
- Each team picks one V-Model phase
- Write one prompt you would give to GitHub Copilot
- Prompt must target one of the four areas on the right
- Be specific: mention the light sensor project
- Present your prompt and explain what you expect back
- Class votes on which prompt would save the most time
LLM Generating Tests:Unit Testing Phase
- Dev highlights
read_and_post()function in editor - Copilot Chat prompt: "generate pytest unit tests for this"
- LLM reads the function signature and infers edge cases
- Generates: valid lux, null return, network timeout, lux above 65000
- Dev reviews each test:checks mock matches real interface
- V-Model: unit test directly verifies the module design
AI Agent in V-Model: Autonomous Dev
- An agent is an LLM that can call tools and loop until done
- Requirements: agent readsissues, links to code automatically
- Coding: agent writes function, runs tests, fixes failures, commits
- Integration: agent triggers CI, reads failure logs, patches the bug
- System Testing: agent runs full sensor simulation, reports kWh delta
- Human reviews and approves:agent does the repetitive loop
GitHub Copilot LLM Chat/Agent
- Copilot Workspace is a coding agent inside GitHub
- Dev opens an issue: "sensor posts wrong zone ID"
- Agent reads the issue, locates the bug in
send_data_api.py - Agent proposes a fix, shows a diff, runs the test suite
- Dev clicks Approve:agent opens a pull request
- Real session used on this project: see link below
LLM + Agent: Value Across V-Model
- LLM: answers, generates, explains:one prompt at a time
- Agent: loops, uses tools, fixes errors autonomously
- Both live inside GitHub Copilot:no new tools needed
- LLM speeds up every phase from requirements to acceptance
- Agent automates the coding + test + fix loop end to end
- Human judgment still required at every gate
Module 13
Limitations of AI in Software Engineering
Understanding where AI fails and why engineering discipline is still required in IoT systems.
Common Models and Their Properties
- Choose model based on cost, context window, and latency
- Small models fit extraction, tagging, and dashboard summaries
- Larger models fit planning, coding, and long-document reasoning
- For our light sensor app, use cheap models first where possible
- Always verify live pricing before production deployment
Limitation 1: AI Can Be Wrong
- AI output is not guaranteed to be correct
- A confident answer may still be false
- Wrong outputs can look reasonable
- Users may trust the result too quickly
- Human checking is still required
Limitation 2: LLMs Can Hallucinate
- LLMs may invent explanations
- The explanation may sound professional
- But it may not match the real system
- This is risky in fault diagnosis
- Grounding is necessary
Limitation 3: Bad Data Leads to Bad AI
- Models depend on input data quality
- Missing values distort behavior
- Faulty sensors corrupt training data
- AI cannot fix broken measurements
- Data validation must come first
Limitation 4: AI Does Not See Full Context
- AI only sees provided signals
- It misses physical context
- It may ignore maintenance events
- It may not know room usage changed
- Context must be supplied explicitly
Limitation 5: Models Drift Over Time
- Behavior changes across semesters or seasons
- Occupancy patterns can shift
- Lighting conditions can change
- Old models become less accurate
- Retraining is necessary
Limitation 6: False Positives Happen
- Normal events may be flagged as faults
- This creates unnecessary alerts
- Users may lose trust in the system
- Not every unusual reading is a failure
- Thresholds need tuning
Limitation 7: False Negatives Happen Too
- Real faults may be missed
- Slow degradation is hard to catch
- No alert does not mean no problem
- Silent failures are dangerous
- Monitoring must not rely on AI alone
Limitation 8: Black Box Decisions
- Many models do not explain themselves well
- Users may not know why an alert appeared
- This weakens trust and accountability
- It is hard to audit the reasoning
- Explainability matters in engineering
Limitation 9: Prompt Quality Affects LLM Answers
- The same data can yield different answers
- Weak prompts produce weak outputs
- Ambiguous wording causes confusion
- Users may ask vague dashboard questions
- Prompt design matters
Limitation 10: Real-Time Systems Need Fast AI
- Inference takes time
- Heavy models add latency
- Dashboard updates may slow down
- IoT pipelines have timing limits
- Some models are too expensive to run live
Limitation 11: AI Adds Cost
- Inference consumes compute resources
- LLM queries cost money
- Storage and retrieval add overhead
- Scaling to more rooms increases expense
- Not every feature is worth the cost
Limitation 12: AI Increases System Complexity
- More components mean more integration work
- More things can fail
- Debugging becomes harder
- Monitoring must cover more layers
- Simple systems are easier to trust
Limitation 13: AI Features Create Security Risks
- Prompt interfaces can be abused
- Data access must be controlled carefully
- Users should not query unrestricted data
- Logs may contain sensitive information
- Security is part of AI design
Limitation 14: Users May Trust AI Too Much
- A polished dashboard feels authoritative
- Users may stop checking raw readings
- Summaries can hide important details
- Trust can become over-trust
- Human review remains important
Limitation 15: A Model in One Building May Fail in Another
- AI may not generalize well
- Different rooms have different patterns
- Different light sources change behavior
- Occupancy schedules vary by site
- Deployment often needs retraining
Limitation 16: AI Is Harder to Test Than Normal Code
- Code can have deterministic outputs
- AI often gives probabilistic outputs
- Pass or fail is less obvious
- Testing requires datasets and metrics
- Validation is more complex
Limitation 17: Accountability Remains Human
- AI does not carry responsibility
- Someone must own the final decision
- This matters in industrial operations
- Wrong alerts can waste time and money
- Wrong non-alerts can hide failures
Limitation 18: AI Depends on Infrastructure
- Cloud models need network access
- Service outages affect AI features
- Edge devices may lack compute power
- Availability becomes a system issue
- Fallback paths are needed
Limitation 19: AI Requires Ongoing Maintenance
- Models need retraining and retesting
- Prompts may need revision
- Knowledge bases need updates
- Metrics must be monitored continuously
- AI adds operational work
Limitation 20: AI Cannot Replace Engineering Judgment
- AI can assist but not own the system
- It does not understand full tradeoffs
- It cannot replace domain expertise
- Engineering decisions remain human work
- AI supports the process, not the responsibility
Questions
Questions
Sample Final Exam
- Covers all 13 modules of the semester
- Mix of scenario questions and design questions
- Focus on IoT pipeline and V-Model phases
- Focus on choosing the right AI layer for a problem
- Download: Final Sample 1
- Download: Final Sample 2
Module 14
Course Review: Mods 1–13
Every concept revisited through the room light sensor app.
Mod 1: Industry 4.0 Pipeline
- Physical world → digital data
- Sensor reads, firmware posts
- Programming vs. engineering
- Reliability, safety, trade-offs
- Ecosystem of shared components
Mod 1: Ecosystem Complexity
- Many independent components
- Shared JSON payload contract
- Change in one layer breaks others
- Coordination is continuous work
- Engineering manages this complexity
Mod 1: Engineering Properties
- Reliability: retry on POST fail
- Safety: skip null lux readings
- Trade-off: 5s vs battery life
- Docs: schema, README, API spec
- Process scales the team
Review Q: Module 1
- Name the four I4.0 pipeline stages in order for the sensor app
- The sensor goes offline at night: which engineering property applies?
- Why is a 5 s poll interval a trade-off?
Mod 2: Epics & User Stories
- Epic: large feature goal
- Story: As / I want / So that
- Acceptance: Given / When / Then
- Backlog tasks are estimable
- Vertical slices of user value
Mod 2: Backlog Task Breakdown
- Story decomposes to tasks
- Tasks estimated in hours
- Clear "done" definition per task
- Priority set by product owner
- Blocked tasks flagged at standup
Mod 2: Given / When / Then
- Given: system pre-condition
- When: trigger action
- Then: observable outcome
- Each AC is a testable assertion
- Multiple scenarios per story
Review Q: Module 2
- Complete: "As a building manager, I want ___"
- Write Given/When/Then for null lux
- What makes a backlog task estimable?
Mod 3: Conway's Law
- System mirrors team structure
- Firmware team owns sensor code
- Backend team owns API code
- Frontend team owns dashboard
- Interface = org boundary
Mod 3: Sprint Cycle (5 Meetings)
- Groom → Plan → Daily → Demo → Retro
- Timebox: 1–2 weeks
- Increment shipped each sprint
- Daily unblocks team members
- Retro improves the process
Mod 3: GitHub PR Workflow
- Feature branch per task
- Open PR → CI runs tests
- Peer review required
- Green CI + approval = merge
- Merge triggers auto-deploy
Review Q: Module 3
- A merge broke the lux POST: which sprint meeting surfaces this?
- Which tool would have caught it before merge?
- State Conway's Law for this project
Mod 4: NIST CSF (6 Functions)
- Govern · Identify · Protect
- Detect · Respond · Recover
- Risk-based security framework
- Applied to entire sensor ecosystem
- Guides policy and security controls
Mod 4: TDD & V-Model
- TDD: write test before code
- Red → Green → Refactor cycle
- V-Model: each level has test
- Unit ↔ integration ↔ system
- Test proves requirement met
Mod 4: SSDF Phases
- Prepare: train team on security
- Protect: harden code, sanitize
- Produce: build securely with TDD
- Respond: patch CVEs quickly
- Applied across every sprint
Review Q: Module 4
- A dev writes
read_lux()before writing any test - Which TDD step was skipped?
- Which NIST CSF function covers logging 401 errors?
- Which SSDF phase requires sanitizing lux input?
Mod 5: Architecture Styles
- Monolith: all-in-one process
- Client-Server: ESP32 → API
- Event-driven: async on publish
- Sensor app uses Client-Server
- Each style has trade-offs
Mod 5: UML Sequence Diagram
- Shows runtime message order
- Actors with lifelines
- Sync call: solid arrow
- Return: dashed arrow
- Alt fragment: conditional path
Mod 5: Core JSON Payload
- Payload is the system contract
- Fields: deviceId, lux, unit, ts
- Schema shared across all teams
- Versioning prevents breaking change
- Validate all fields on receipt
Review Q: Module 5
- Which architecture style does the sensor app use?
- Which UML diagram shows the POST /api/lux flow?
- A dev renames "lux" to "brightness": what breaks?
Mod 6: Legal Requirements
- GDPR: personal data obligations
- Lux + occupancy = personal data?
- Consent, retention, right to delete
- Legal req → highest priority story
- Non-compliance blocks release
Mod 6: Legal & Privacy
- Lux spike at 8 PM → person present
- Inferred occupancy = personal data
- GDPR Article 4: any info identifying a person
- Consent required before collection
- Right to deletion (Article 17)
- Non-compliance blocks release
Even raw sensor data can become personal data when it reveals who was where and when. The lux graph on the right is evidence of occupancy: and therefore falls under privacy law.
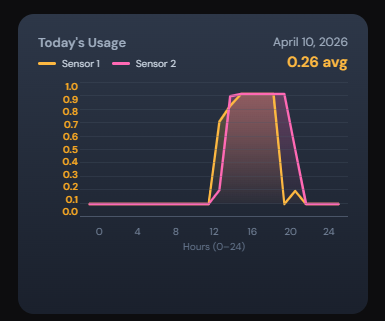
Mod 6: NFR vs. FR & FOTA
- FR: what the system does
- NFR: how well it performs
- NFR: latency, uptime, privacy
- FOTA: firmware over-the-air
- FOTA needs SHA-256 integrity check
Mod 6: Compliance as a Story
- Legal req → acceptance criteria
- Compliance tested like any feature
- Audit trail stored in logs
- Privacy by design from sprint 1
- Retrofit compliance is expensive
Review Q: Module 6
- A regulator requires lux data deleted on request: is this FR or NFR?
- Where does it appear in the backlog?
- What is FOTA and why does it need an integrity check?
Mod 7: Test Levels
- Unit: one function in isolation
- Integration: two components
- System: full end-to-end flow
- Each level catches different bugs
- All three needed for sensor app
Mod 7: AAA Pattern
- Arrange: set up test state
- Act: call the function under test
- Assert: verify the outcome
- One concept per test case
- Tests are fully deterministic
Mod 7: Contract Testing
- Payload is a tested contract
- Firmware tests it produces it
- Backend tests it accepts it
- Both suites must pass on change
- CI enforces the contract
Review Q: Module 7
- Write an AAA unit test for
validateLux(-1) - Which test level catches a broken DB connection?
- Distinguish verification vs. validation for the sensor app
Mod 10: Constrained Resources
- Battery: limit read frequency
- Memory: ring buffer caps usage
- Bandwidth: compact payload
- CPU: no on-device ML
- Adaptive sync balances all four
Mod 10: Adaptive Sync
- Night: stable lux → 60 s sleep
- Daytime change → 5 s poll
- Detect lux delta to decide
- Threshold tunable per room
- Balances accuracy vs. battery
Mod 10: JSON vs. Protobuf
- JSON: human-readable, verbose
- Protobuf: binary, 4× smaller
- Protobuf needs .proto schema
- Choose by bandwidth constraints
- Dev/debug prefers JSON
Review Q: Module 10
- ESP32 is battery-powered in a remote room: how reduce power?
- Ring buffer holds 50 readings: what happens at reading 51?
- When would you choose Protobuf over JSON?
Mod 11: Zero Trust & RBAC
- Never trust, always verify
- Every request must authenticate
- Bearer token on every POST
- RBAC: role defines allowed routes
- Principle of least privilege
Mod 11: Security Layers
- IP allowlist: block unknown sources
- HTTPS: encrypt all traffic
- Token: verify identity per request
- RBAC: limit route access by role
- Env vars: never hardcode secrets
Mod 11: RBAC Permission Matrix
- Roles assigned to principals
- Permissions tied to API routes
- Sensor cannot read its own data
- Manager cannot delete data
- Admin has all permissions
Review Q: Module 11
- Attacker POSTs fake lux from unknown IP: which control stops it first?
- DB password found in git history: what is the fix?
- Can the sensor-device role call GET /api/lux?
Mod 12: Release Channels
- Alpha: internal team only
- Beta: limited external users
- Gamma: staged wider rollout
- Release: all buildings / full prod
- Each channel gated by tests
Mod 12: CI/CD Pipeline
- CI: test on every PR push
- CD: deploy on merge to main
- Build → Test → Lint → Deploy
- Failed test blocks the merge
- Rollback on deploy failure
Mod 12: Digital Twin
- Software model of the sensor
- Inject any lux value in test
- Runs fast in CI pipeline
- Simulates hardware faults
- Reduces physical lab time
Review Q: Module 12
- A bug v1.2.0 breaks chart for beta users: what happens before gamma?
- What does v1.2.0 → v1.2.1 mean?
- Why use digital twin instead of real hardware in CI?
Mod 13: AI for the Process
- LLM writes sensor driver code
- Generates unit tests from description
- Reviews PRs for logic errors
- Drafts README and API docs
- Explains error messages
Mod 13: AI for the Product
- Anomaly detection on lux stream
- Occupancy prediction (ML model)
- Natural language lux queries
- Daily summary via RAG
- AI feature = product value added
Mod 13: Process vs. Product AI
- Process AI: helps build the system
- Product AI: helps use the system
- Both active in same project
- Neither changes the hardware
- Clear responsibility boundary
Room Sensor Data: What Do We See?
- 4 days of lux readings: Apr 10–13
- Two sensors: Sensor 1 (yellow) & Sensor 2 (pink)
- X-axis: hours 0–24 · Y-axis: normalised lux 0–1
- Apr 13 (today): spike ~8–12 h · avg 0.12
- Apr 12: broad peak 8–20 h · avg 0.47
- Apr 11: broad peak 8–20 h · avg 0.43
- Apr 10: narrower peak 12–20 h · avg 0.26
Friday Apr 11: office light switched on ~8 PM then off: visible as a sharp late-day plateau. Mon–Sun readings reflect natural daylight only (office light was off).
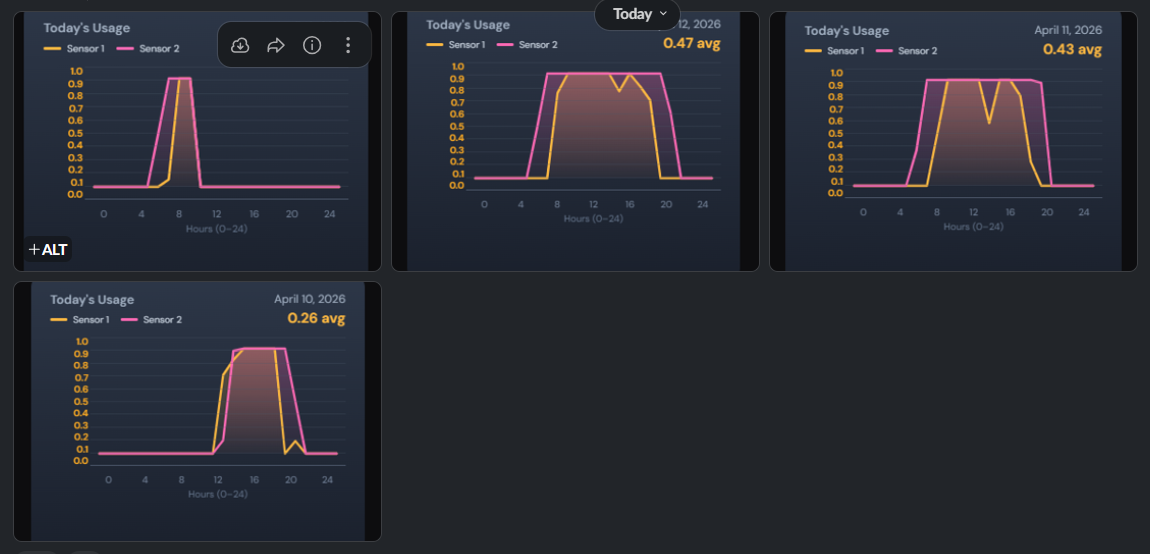
Sensor, Arduino & Software Perspective
- Sensor 1 vs 2 diverge: different placements or calibration?
- Sensor 2 (pink) consistently lower: may be obstructed
- Sharp edges suggest polling works correctly at 5 s
- No dropout gaps: WiFi + POST pipeline stable
- Normalisation hides absolute lux: raw values needed
- Friday 8 PM spike: software correctly captured light-on event
The system is working: data flows continuously. But two sensors reading differently signals a hardware or placement inconsistency, not a software bug.

Data Quality Perspective
- Normalised 0–1 loses absolute lux context
- No unit label on Y-axis makes comparison hard
- Two sensors should agree: large gap = quality concern
- Friday spike duration < 1 h: is that accurate?
- Weekend near-zero: expected (no sun, no lights)
- No timestamps on anomalies: need higher resolution
Good data quality needs: raw lux stored (not just normalised), sensor ID tagged per reading, and outlier detection to flag implausible jumps automatically.
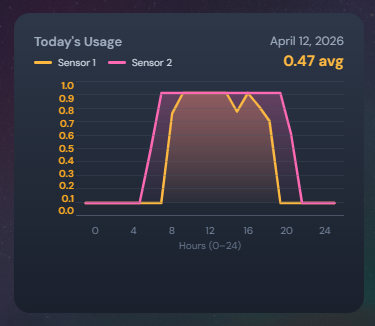
Sensor Setup: Window vs. Table
- Window sensor: captures sunlight directly
- Window sensor: high variance, weather-dependent
- Table sensor: measures working-area light
- Table sensor: more relevant to occupancy
- Sensor 1 (yellow) likely near window: peaks higher
- Sensor 2 (pink) likely on table: lower, steadier
A window sensor tells you about sunlight; a table sensor tells you about room use. Both are useful but serve different questions. Label each sensor's physical location in the database.

Dashboard Interpretation
- Broad plateau (8–20 h): natural daylight through window
- Sharp late spike (Friday ~20 h): artificial light switched on
- Avg 0.47 (Wed) vs 0.12 (Mon): cloudy Monday likely
- Plateau shape = occupancy proxy during office hours
- Single avg value hides intra-day variation
- Need: min/max/std per day, not just avg
The dashboard shows when light was present, which correlates with occupancy: but only when the office light is on. Natural light alone cannot confirm someone was in the room.
How to Improve Next Weekend
- Label sensor location in payload:
window/table - Store raw lux alongside normalised value
- Add PIR motion sensor: confirms occupancy directly
- Log office light switch state (GPIO pin)
- Increase resolution to 1 s during spikes (adaptive sync)
- Add timezone to timestamp: avoid ambiguous hour offsets
- Dashboard: show min/max band, not just avg
- Alert when Sensor 1 and Sensor 2 diverge > 20%
{ "deviceId":"r01", "location":"window",
"lux":342, "luxRaw":342, "lightOn":true,
"ts":"2026-04-18T20:00:00+05:30" }
Review Q: Module 13
- "Which room had highest lux Monday?": AI for Process or Product?
- LLM writes the unit test for
read_lux(): which SSDF phase? - Anomaly detection runs on the server, not ESP32: why?
Today's Case Studies
- Three real-world IoT systems
- Each covers: sensors, network, data, AI, failure modes
- Connects lecture concepts to deployed products
What Each Case Study Covers
- Sensor and hardware layer
- Network protocol choices
- Data model and storage
- AI use and limitations
- Failure modes and mitigations
Case Study 1: Navigation Software
- Real-time GPS + map routing on mobile/embedded
- Continuous sensor fusion: GPS, accelerometer, gyroscope
- Cloud map tiles + live traffic data ingestion
- Edge inference for lane guidance and rerouting
- Safety-critical: wrong route = real-world consequence
Navigation: Sensor Layer
- GPS gives absolute position ±3–5 m
- IMU dead-reckons through GPS outages (tunnels)
- Gyroscope detects turns, barometer detects floors
- Data fused at 50–100 Hz on device
- Bad GPS fix → Kalman filter down-weights it
Navigation: Network & Protocol Layer
- HTTPS REST for map tile and traffic fetches
- WebSocket for live incident push from cloud
- Tile cache on device: works offline
- Delta updates only: saves bandwidth
- TLS mutual auth for fleet/commercial use
Navigation: Data Model & Storage
- Trips stored as timestamped polylines
- Map tiles in SQLite on device (MBTiles format)
- Traffic events in time-series DB on cloud
- User preferences persisted per device ID
- GDPR: location history deletable on request
Navigation: AI & Failure Modes
- ML predicts ETA from historical speed profiles
- Anomaly detection flags GPS spoofing
- Model drift: new road not in training data
- False reroute wastes fuel: false negative misses jam
- Human override always available: AI assists only
Case Study 2: Clinical Scale From Home
- Smart scale measures weight, BMI, body-fat %
- Data sent to clinician portal and patient app
- Regulated device: HIPAA / MDR compliance
- Low-power BLE to phone, phone to cloud
- Trend alerts trigger clinical review workflow
Clinical Scale: Sensor & Hardware Layer
- Load cell measures weight to ±0.1 kg
- BIA (bioelectrical impedance) estimates body-fat %
- Measurements taken at fixed time each day (protocol)
- Tamper-evident casing: regulatory requirement
- BLE 5.0: low power, encrypted link layer
Clinical Scale: Security & Compliance
- BLE link encrypted (AES-128 at pairing)
- Cloud store HIPAA-compliant: data encrypted at rest
- Role-based access: patient vs clinician vs admin
- Full audit log: who viewed what, when
- Right to deletion: patient can purge history
Clinical Scale: Data Model & Trend Engine
- One reading per patient per day: timestamped
- Time-series DB (e.g. InfluxDB) for trend queries
- 7-day rolling average computed server-side
- Alert rule: >2 kg gain in 3 days → notify clinician
- Dashboard shows sparkline + threshold bands
Clinical Scale: AI Limitations & Human Oversight
- AI flags trends: clinician makes all decisions
- False positive alert: clothing / food variation
- False negative: slow oedema missed by threshold
- Model trained on population: may drift per patient
- Accountability always stays with the clinician
Case Study 3: Retailer Smart Carts
- Cart detects items via weight + barcode/RFID
- Running total shown on cart display
- Payment at cart: no checkout lane needed
- Store analytics: dwell time, path, conversion
- Wi-Fi backhaul to store edge server + cloud
Smart Cart: Sensor & Detection Layer
- Weight grid: 4–16 load cells in cart floor
- RFID reads tagged items passively at 1 m range
- Barcode scanner as fallback for untagged items
- Differential weight: item placed = +Δkg matched to SKU
- IMU detects cart movement: pause reads during transit
Smart Cart: Edge Processing & Network
- Store edge server holds local product catalogue
- Item lookup latency <50 ms: no cloud round-trip
- Wi-Fi 6: low latency, handles 100+ carts
- MQTT from cart to edge: lightweight pub-sub
- Edge syncs inventory delta to cloud every 30 s
Smart Cart: Data Model & Analytics
- Session record per shopping trip per cart
- Item events: add / remove / pay timestamped
- Path data from in-store BLE beacons (opt-in)
- Dwell time per aisle → planogram optimisation
- Anonymised before cloud analytics pipeline
Smart Cart: AI, Fraud Detection & Failure Modes
- AI checks: weight vs expected SKU weight
- Flags mismatch: item scanned but weight unchanged
- False positive: produce items vary in weight naturally
- False negative: swapping barcodes defeats weight check
- Human audit: flagged carts reviewed at exit gate
Project Overview
README.md
- End-to-end indoor light monitoring system
- Sensor detects ON/OFF → Flask backend stores events
- Dashboard alerts when light ON > 12 hours
- ✓ Clear scope ✓ Layered architecture
- ⚠ Auth not addressed ⚠ 12 h threshold hardcoded
Embedded
Repository Structure
/ (root)
app/embedded/: Arduino sketches & PCBapp/backend/: Flask APIapp/frontend/: Dashboardapp/architect/: ADRs, diagrams, interfacesapp/devOps/: CI/CD configs- ✓ Monorepo ✗ hardware_tests/ is empty
- ⚠ backend/ and frontend/ stubs only
BH1750 Light Sensor
app/embedded/BH1750_test/BH1750_test.ino
- 16-bit digital ambient light sensor, I2C
- Outputs lux directly: no ADC conversion needed
- I2C address:
0x23(ADDR=LOW) or0x5C(ADDR=HIGH) - ✓ Direct lux output ✓ Only 2 signal wires
- ⚠ Range 1–65535 lx ✗ ADDR pin not configured in sketch
BH1750_test.ino : Full Sketch
app/embedded/BH1750_test/BH1750_test.ino
void setup() {
Serial.begin(115200);
Wire.begin(21, 22); // SDA, SCL
if (lightMeter.begin()) {
Serial.println("BH1750 started!");
} else {
Serial.println("Error initializing BH1750");
}
}
void loop() {
float lux = lightMeter.readLightLevel();
Serial.print("Light: ");
Serial.print(lux);
Serial.println(" lx");
delay(1000);
}#include Libraries
BH1750_test.ino · lines 1–2
#include <Wire.h>
#include <BH1750.h>- Wire.h: Arduino I2C master (bundled with ESP32 core)
- BH1750.h: wraps register reads into
readLightLevel() - ✓ Wire.h needs no install
- ✗ BH1750 version not pinned
Wire.begin() : I2C Initialization
BH1750_test.ino · line 7
Wire.begin(21, 22); // SDA=21, SCL=22- Initializes I2C bus with explicit pin numbers
- Default clock: 100 kHz: fast mode:
Wire.setClock(400000) - Pull-up resistors 4.7 kΩ required on SDA and SCL
- ✓ Explicit pins: portable
- ✗ No Wire.setClock() call ✗ No bus error check
Serial.begin() : Debug Output
BH1750_test.ino · lines 6, 18–21
Serial.begin(115200);
Serial.print("Light: ");
Serial.print(lux);
Serial.println(" lx");- ✓ 115200 baud: fast enough for 1 s interval
- ✗ Data never leaves the bench
- ✗ No timestamp alongside lux value
- Production: replace with HTTP POST over WiFi
lightMeter.begin() : Sensor Init
BH1750_test.ino · lines 9–13
if (lightMeter.begin()) {
Serial.println("BH1750 started!");
} else {
Serial.println("Error initializing BH1750");
}- ✓ Checks return value ✓ Prints error message
- ✗ No retry on failure ✗ No halt: loop() runs anyway
- Fix:
if (!lightMeter.begin()) while(1) delay(100);
readLightLevel() : Measurement Loop
BH1750_test.ino · lines 17–22
float lux = lightMeter.readLightLevel();
Serial.print("Light: ");
Serial.print(lux);
Serial.println(" lx");
delay(1000);- Internal: requestFrom(0x23) → 2 bytes → lux = (H<<8|L) / 1.2
- ✓ Simple and readable ✓ float precision
- ✗ No ON/OFF threshold logic
- ✗ No HTTP transmission
delay() : Timing Strategy
BH1750_test.ino · line 22
delay(1000); // blocking: 1 second
// Non-blocking alternative:
unsigned long last = 0;
void loop() {
if (millis() - last >= 1000) {
last = millis();
float lux = lightMeter.readLightLevel();
}
// WiFi tasks run here
}PCB Design
app/embedded/PCB Design.png
- Custom PCB integrates ESP32 + BH1750 on one board
- Eliminates breadboard wiring for deployment
- ✓ Reproducible hardware ✓ Compact form factor
- ✗ No .sch / .kicad_sch source in repo
- ⚠ PNG only: not editable
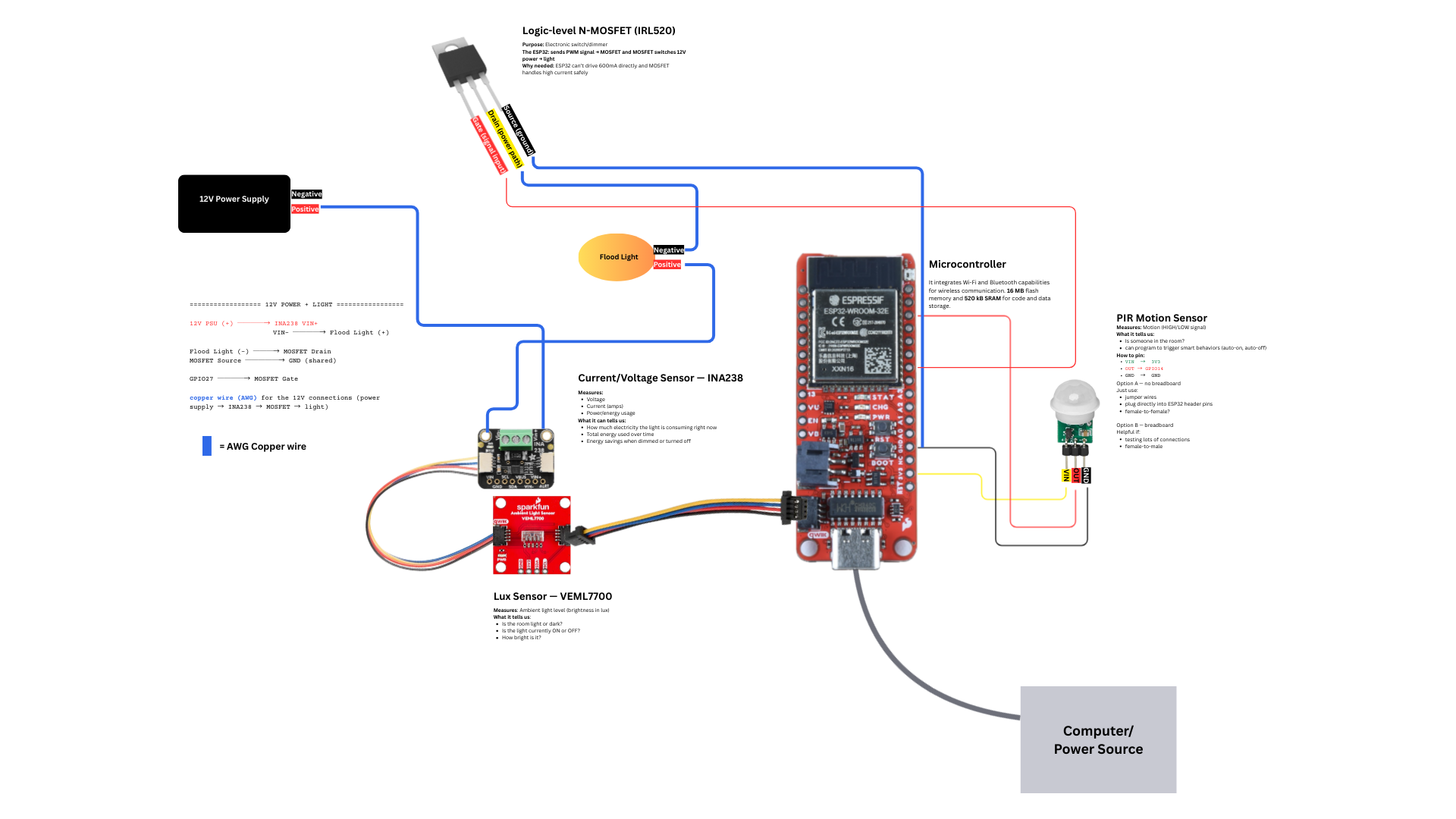
Event Data Schema
README.md · Data Structure
{
"meta": {
"entity": "room_light_event",
"version": "1.0",
"source": "indoor light sensor"
},
"data": {
"room_id": "string | integer",
"light_state": "ON | OFF",
"timestamp": "ISO-8601"
}
}Component Architecture: High Level
app/architect/diagrams/01_component_high_level.png
- IoT Device → Backend: HTTP POST (push)
- Frontend → Backend: HTTP GET (pull)
- Backend → User: notification (email/alert)
- ✓ Clear component boundaries
- ✗ Single backend = SPOF · No message queue
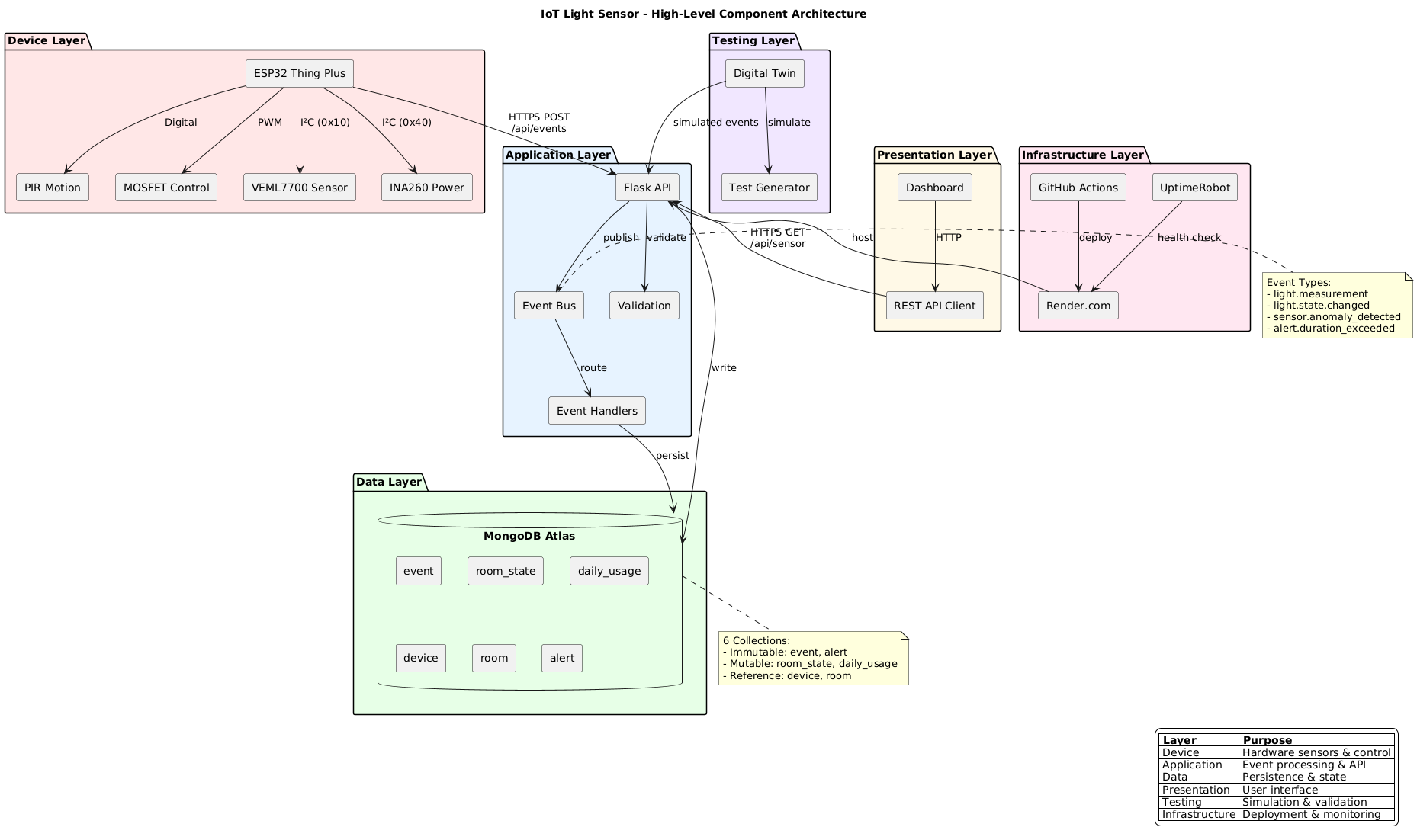
app/architect/diagrams/02_component_detailed.png
- ESP32 sub-components: BH1750 Driver · State Machine · HTTP Client
- Backend sub-components: Router · Validator · DB Layer · Notifier
- ✓ Validation module explicit
- ✗ No auth token · No local buffer on device
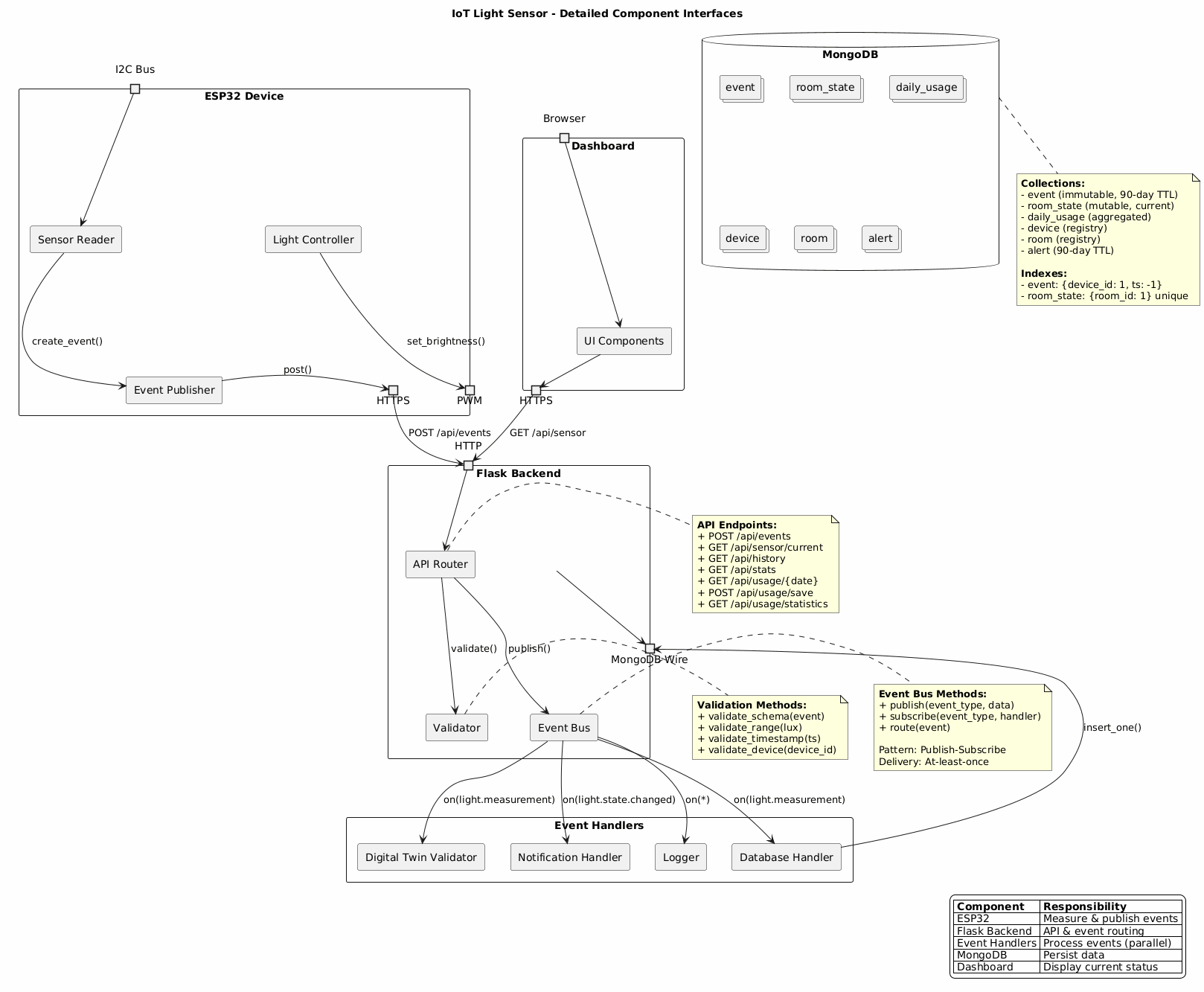
Event-Driven Architecture
app/architect/diagrams/Event-Driven Architecture.png
- Each light state change produces one event
- Event flows: sensor → backend → notification engine
- ✓ Loosely coupled · Easy to add consumers
- ✗ No broker (Kafka/MQTT): direct HTTP only
- ⚠ Consumer must be live to receive events
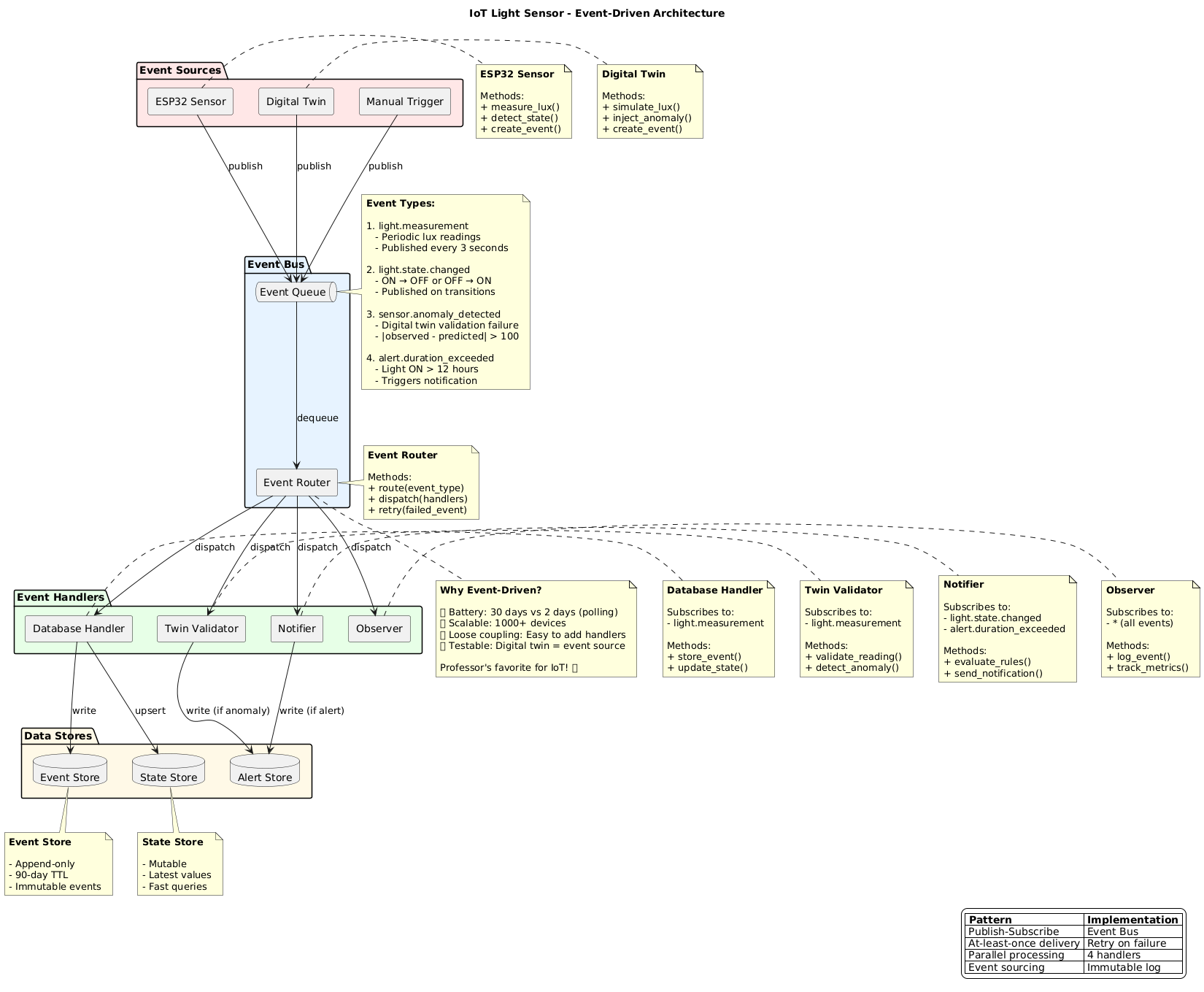
Use Case Diagram
app/architect/diagrams/Use Case Diagram.png
- IoT Device: Detect light state · Send event
- Occupant: View dashboard · Receive notification
- ✓ System boundary drawn · Actors separated
- ✗ No Admin actor · No historical query use case
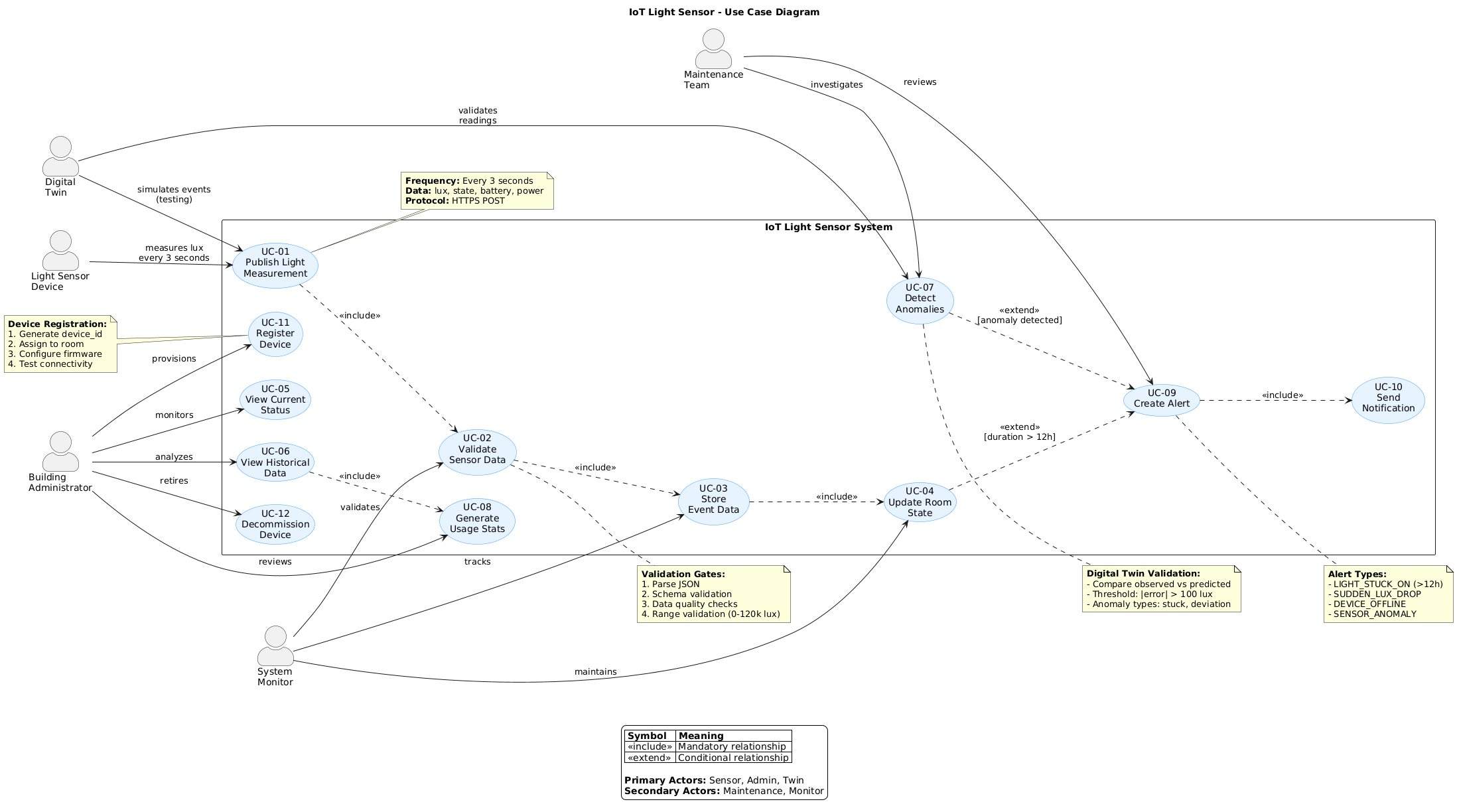
Activity Diagram
app/architect/diagrams/Activity Diagram.png
- Device lane: sense → decide → POST
- Backend lane: receive → validate → store → evaluate → notify
- Rule:
if (ON_duration > 12h) → send alert - ✓ Swim lanes · Decision point explicit
- ✗ Notification failure path not modeled
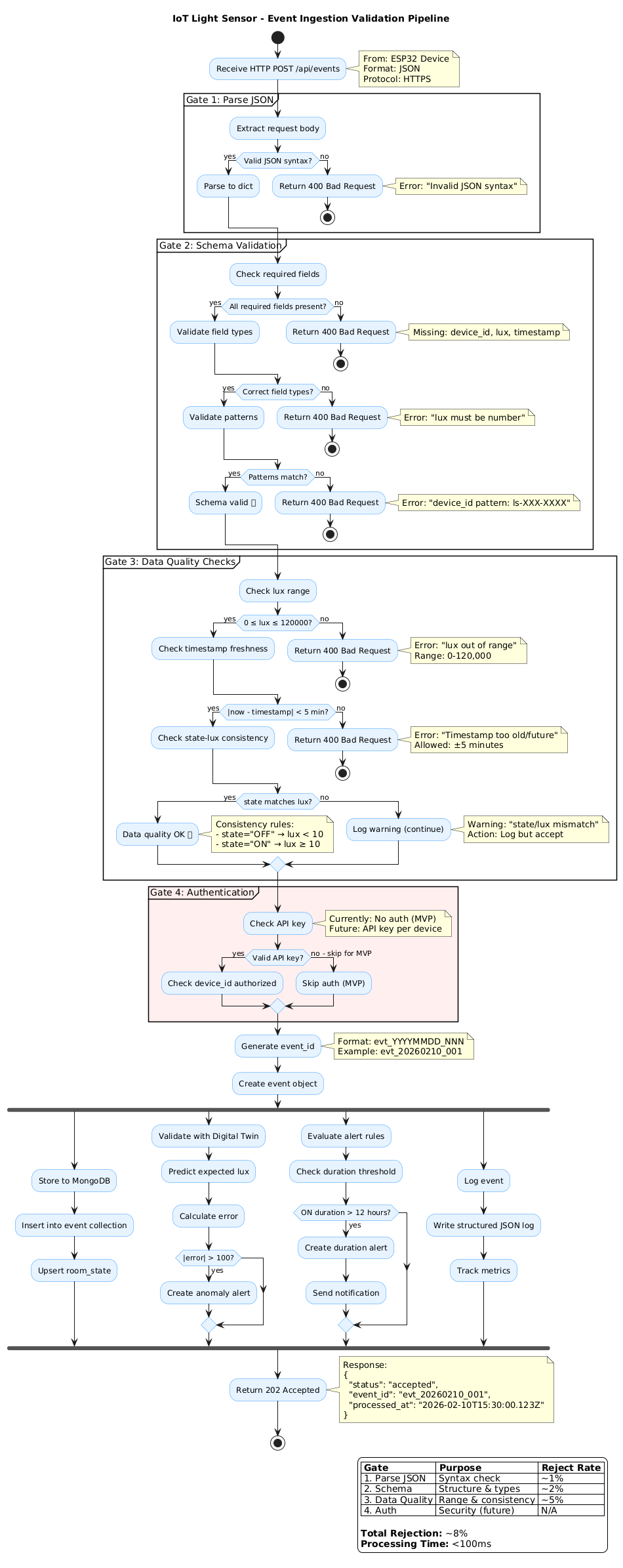
Deployment Architecture
app/architect/diagrams/04_deployment_architecture.puml
- Backend deployed on Render.com (Flask 3.1.3 / Python 3.9)
- Database on MongoDB Atlas M0 free tier
- ✓ Cloud-hosted · Free tiers available
- ⚠ Render free tier sleeps after 15 min idle
- ✗ No HTTPS enforcement on device POST
CI/CD Pipeline
.github/workflows/ · app/devOps/readme.md
- Trigger: push to
mainor pull request - Steps: checkout → install deps → pytest → flake8 → deploy to Render
- Secrets:
RENDER_API_KEY·MONGO_URIin GitHub Secrets - ✓ Automated deploy · Free for public repos
- ✗ No Arduino CI · No staging environment
Improvements Roadmap
RELEASE_NOTES.md · README.md
- ✗ No API authentication (device or user)
- ✗ No offline buffer on ESP32
- ✗ No configurable alert threshold
- ⚠ Backend / Frontend stubs need implementation
- ⚠ Single sensor per room assumed
Backend
Backend Overview
app/backend/ · requirements.txt · runtime.txt
- Flask 3.1.3 · Python 3.9+ · Deployed on Render.com
- 7 REST endpoints across 3 categories: Sensor, Dashboard, Usage
- MongoDB Atlas as the data store (pymongo driver)
- ✓ Lightweight framework ✓ Free-tier deployable
- ✗ No auth yet ⚠ backend/ is stub only
POST /api/events: Ingest Sensor Reading
app/architect/api/readme.md · Sensor Endpoints
POST /api/events
Content-Type: application/json
{
"device_id": "ls-100-0001",
"room_id": "room-101",
"event_type": "light.measurement",
"lux": 342.5,
"light_state": "ON",
"timestamp": "2026-02-10T15:30:00Z",
"meta": {
"battery_pct": 87,
"signal_rssi_dbm": -45,
"firmware_version": "1.0.0"
}
}
// Success → 202 Accepted
{
"event_id": "evt_20260210_001",
"processed_at": "2026-02-10T15:30:01Z"
}- ✓ 202 = async-friendly
- ✗ No auth header required yet
GET /api/sensor/current: Live Room State
app/architect/api/readme.md · Dashboard Endpoints
GET /api/sensor/current?room_id=room-101
// Response 200 OK
{
"room_id": "room-101",
"lux": 342.5,
"state": "ON",
"timestamp": "2026-02-10T15:30:00Z",
"freshness_seconds": 2
}
// Cache: 3 seconds (reduces DB load)
// Served from: room_state collection- ✓ Fast: reads room_state not raw events
- ⚠ freshness_seconds shows staleness
GET /api/history: Historical Readings
app/architect/api/readme.md · Dashboard Endpoints
GET /api/history
?room_id=room-101
&limit=100
&from=2026-02-10T00:00:00Z
&to=2026-02-10T23:59:59Z
// Response 200 OK
{
"room_id": "room-101",
"count": 100,
"events": [
{
"lux": 342.5,
"state": "ON",
"timestamp": "2026-02-10T15:30:00Z"
}
]
}
// Cache: 30 seconds · max limit: 500GET /api/stats: Aggregated Metrics
app/architect/api/readme.md · Dashboard Endpoints
GET /api/stats?room_id=room-101
// Response 200 OK
{
"room_id": "room-101",
"period": "today",
"avg_lux": 285.5,
"min_lux": 12.0,
"max_lux": 850.0,
"sample_count": 28800,
"energy_wh": 230.4
}
// Cache: 5 minutes
// Reads from: daily_usage collection- ✓ Energy (Wh) included
- ✗ No weekly/monthly period param yet
Usage Endpoints
app/architect/api/readme.md · Usage Endpoints
// Get daily stats for a specific date
GET /api/usage/2026-02-10
// Save a day's aggregated usage
POST /api/usage/save
{
"room_id": "room-101",
"date": "2026-02-10",
"on_seconds": 28800,
"energy_wh": 230.4
}
// Aggregate across periods
GET /api/usage/statistics
?room_id=room-101
&period=weekly // daily | weekly | monthly- ⚠ POST /usage/save has no auth: anyone can write
- ✗ No idempotency key on save
Input Validation Rules
app/architect/api/readme.md · app/architect/interface/sensor-backend.md
# Flask validation (pseudocode)
def validate_event(data):
# lux range
assert 0 <= data["lux"] <= 120000
# device_id pattern: ls-NNN-NNNN
assert re.match(r"^ls-\d{3}-\d{4}$",
data["device_id"])
# timestamp within 5-min of server time
delta = abs(now() - parse(data["timestamp"]))
assert delta <= timedelta(minutes=5)
# light_state enum
assert data["light_state"] in {"ON","OFF","UNKNOWN"}- ✓ Tight constraints prevent garbage data
- ✗ No JSON Schema library enforcing this at the framework level
Rate Limiting
app/architect/api/readme.md · Rate Limiting section
# POST /api/events
# Limit: 1000 req / hour / device_id
# GET endpoints
# Limit: 10,000 req / hour / IP
# 429 response when exceeded:
{
"error": "rate_limit_exceeded",
"retry_after_seconds": 3600,
"limit": 1000,
"window": "1h"
}- ✓ Per-device POST limit prevents flood
- ⚠ 1000/hr = ~16/min: fine for 3 s interval
- ✗ No burst allowance defined
CORS & Error Response Format
app/architect/interface/backend-frontend.md
# Allowed origins (CORS)
ALLOWED_ORIGINS = [
"https://se4cps.github.io", # GitHub Pages
"https://iot-dashboard.onrender.com",
"http://localhost:5500" # dev
]
ALLOWED_METHODS = ["GET", "POST", "OPTIONS"]
# Structured error response
{
"error": "validation_failed",
"detail": "lux must be between 0 and 120000",
"timestamp": "2026-02-10T15:30:00Z",
"request_id": "req_abc123"
}Sensor → Backend Interface Contract
app/architect/interface/sensor-backend.md
# Transport: HTTPS POST (TLS 1.3)
# Endpoint: /api/events
# Retry: 3 attempts, exponential backoff
# attempt 1: wait 1s
# attempt 2: wait 2s
# attempt 3: wait 4s
# Retry on: 500, 502, 503, 504
# Timeout per attempt: 10s
# Full event payload
{
"device_id": "ls-100-0001",
"room_id": "room-101",
"event_type": "light.measurement",
"lux": 342.5,
"light_state": "ON",
"timestamp": "2026-02-10T15:30:00Z",
"meta": {
"battery_pct": 87,
"signal_rssi_dbm": -45,
"firmware_version": "1.0.0"
}
}ADR-001 : Event-Driven Architecture Decision
app/architect/decisions/001-event-driven-architecture.md
# Decision: Event-Driven Architecture
# Rejected options:
# - Layered Monolith → requires polling
# (2-day battery life unacceptable)
# - Microservices → over-engineered for MVP
# Chosen: Event-Driven
# Battery: 2 days → 30 days (15x improvement)
# Bus (MVP): in-memory Python queue
# Bus (prod): RabbitMQ or Kafka (planned)
# 4 event types:
# 1. measurement → DB persist
# 2. state_change → notification trigger
# 3. anomaly → alert generate
# 4. alert → observability log- ✓ 15× battery improvement vs polling
- ⚠ Eventual consistency accepted
MongoDB: event Collection
app/architect/data/database-schema.md · Collection 1
// event document
{
event_id: "evt_20260210_001",
schema_version: "1.0",
ts: ISODate("2026-02-10T15:30:00Z"),
room_id: "room-101",
device_id: "ls-100-0001",
light_state: "ON", // ON | OFF | UNKNOWN
lux: 342.5,
meta: {
seq: 1234,
battery_pct: 87,
signal_rssi_dbm: -45,
firmware_version: "1.0.0",
power_mw: 2400,
motion_detected: true
}
}
// Indexes
db.event.createIndex({ device_id:1, ts:-1 })
db.event.createIndex({ room_id:1, ts:-1 })
db.event.createIndex({ ts:1 }, { expireAfterSeconds: 7776000 })MongoDB: room_state Collection
app/architect/data/database-schema.md · Collection 2
// room_state document (one per room)
{
_id: "room-101",
room_id: "room-101",
light_state: "ON",
lux: 342.5,
power_mw: 2400,
motion_detected: true,
last_event_id: "evt_20260210_001",
last_ts: ISODate("2026-02-10T15:30:00Z"),
updated_at: ISODate("2026-02-10T15:30:00.123Z")
}
// Upsert on every incoming event
db.room_state.updateOne(
{ room_id: "room-101" },
{ $set: { light_state:"ON", lux:342.5,
updated_at: new Date() } },
{ upsert: true }
)- ✓ 1 document per room: O(1) lookup
- ⚠ Race condition if two events arrive simultaneously
MongoDB: daily_usage Collection
app/architect/data/database-schema.md · Collection 3
// daily_usage document
{
_id: "room-101-20260210",
room_id: "room-101",
date: "2026-02-10",
on_seconds: 28800,
off_seconds: 57600,
avg_lux: 285.5,
energy_wh: 230.4,
updated_at: ISODate("2026-02-10T23:59:59Z")
}
// Aggregation to build it
db.event.aggregate([
{ $match: { room_id:"room-101",
ts: { $gte: ISODate("2026-02-10T00:00:00Z"),
$lt: ISODate("2026-02-11T00:00:00Z") }}},
{ $group: { _id: null,
avg_lux: { $avg: "$lux" },
energy_wh: { $sum: { $divide:["$meta.power_mw",3600000] }}
}}
])MongoDB: device Collection
app/architect/data/database-schema.md · Collection 4
// device document
{
_id: "ls-100-0001",
device_id: "ls-100-0001",
room_id: "room-101",
device_type: "light_sensor",
status: "ACTIVE", // ACTIVE|DISABLED|RETIRED
firmware_version: "1.0.0",
hardware: {
mcu: "ESP32 Thing Plus",
light_sensor: "VEML7700",
power_sensor: "INA260",
motion_sensor: "PIR"
},
provisioned_at: ISODate("2026-02-01T10:00:00Z"),
last_seen_at: ISODate("2026-02-10T15:30:00Z")
}
// Indexes
db.device.createIndex({ device_id:1 }, { unique:true })
db.device.createIndex({ room_id:1 })
db.device.createIndex({ last_seen_at:-1 }) // offline detectMongoDB: room Collection
app/architect/data/database-schema.md · Collection 5
// room document
{
_id: "room-101",
room_id: "room-101",
building: "CTC",
room_number: "113",
floor: 1,
tags: ["classroom", "computer-lab"],
area_sqft: 1200,
max_occupancy: 30,
created_at: ISODate("2026-02-01T00:00:00Z"),
updated_at: ISODate("2026-02-01T00:00:00Z")
}
// Indexes
db.room.createIndex({ room_id:1 }, { unique:true })
db.room.createIndex({ building:1, floor:1 })
// Seed for CTC 113
db.room.insertOne({
room_id: "room-101", building:"CTC",
room_number:"113", floor:1,
tags:["classroom","computer-lab"],
created_at: new Date()
})MongoDB: alert Collection
app/architect/data/database-schema.md · Collection 6
// alert document
{
alert_id: "alert-20260210-001",
ts: ISODate("2026-02-10T15:30:00Z"),
room_id: "room-101",
device_id: "ls-100-0001",
type: "LIGHT_STUCK_ON",
// types: LIGHT_STUCK_ON | SUDDEN_LUX_DROP
// DEVICE_OFFLINE | SENSOR_ANOMALY
severity: "WARN",
// levels: INFO | WARN | CRITICAL
linked_event_id: "evt_20260210_001",
explain: {
duration_hours: 13.5,
threshold_hours: 12
}
}
// TTL: auto-delete after 90 days
db.alert.createIndex({ ts:1 },
{ expireAfterSeconds: 7776000 })Collection Relationships & Storage Estimates
app/architect/data/database-schema.md · Data Relationships
// Cardinalities
Room (1) ──── (N) Device
Room (1) ──── (1) RoomState
Room (1) ──── (N) Event
Room (1) ──── (N) DailyUsage
Room (1) ──── (N) Alert
Device (1) ── (N) Event
// Storage per room (90 days)
// event ~800 MB (28,800 docs/day)
// room_state 200 B (1 doc forever)
// daily_usage 13.5 KB (1 doc/day, 2-yr TTL)
// device 300 B (reference)
// alert ~22 KB (~10 alerts/day)
// Total: ~850 MB per room
// 10 rooms → ~8.5 GB
// 100 rooms → ~85.0 GB- ⚠ Atlas M0 free tier limit: 512 MB
- ✗ 1 room for 90 days already exceeds M0
Query Performance & Index Strategy
app/architect/data/database-schema.md · Query Performance
// Target query times
// GET current state → < 10 ms (actual ~5 ms)
// GET last 100 events → < 50 ms (actual ~30 ms)
// Daily aggregation → <200 ms (actual ~150 ms)
// Weekly stats → <500 ms (actual ~400 ms)
// Key compound indexes:
db.event.createIndex({ device_id:1, ts:-1 })
db.event.createIndex({ room_id:1, ts:-1 })
// Caching layer (Flask)
// /api/sensor/current → cache 3 s
// /api/history → cache 30 s
// /api/stats → cache 5 min- ✓ Compound indexes match query patterns
- ✗ No index on (room_id, light_state) for ON-duration queries
Backend Improvements Roadmap
app/architect/decisions/ · app/architect/api/readme.md
# Planned improvements
# 1. Authentication (high priority)
# Add: Authorization: Bearer <token>
# to all POST endpoints
# 2. Replace in-memory queue with RabbitMQ
# producer.publish(event)
# consumer.subscribe(handle_event)
# 3. Schema migration v1.0 → v1.1
db.event.updateMany(
{ "meta.power_mw": { $exists: false } },
{ $set: { "meta.power_mw": 0 } }
)
# 4. Upgrade Atlas M0 → M10
# M0: 512 MB · M10: 10 GB · ~$57/moFrontend
Frontend Overview
dashboard/ · dashboard/app.py · dashboard/requirements.txt
- Flask 3.0 serves the dashboard · PyMongo · Gunicorn in production
- 6 room control cards · lux gauge · usage charts · user auth
- Dark theme with orange accent
#f5a623· glassmorphism effects - ✓ Real data from MongoDB ✓ Responsive layout
- ⚠ Simulated lux (0–50) not real BH1750 data
Dashboard File Structure
dashboard/
dashboard/
├── app.py # Flask app + all routes
├── requirements.txt # Flask · pymongo · gunicorn
├── dashboard.html # standalone HTML (root)
├── diagram.html # architecture diagram view
├── templates/
│ ├── dashboard.html # Jinja2 template
│ └── diagram.html
└── tests/
└── app_test.py # unit tests- ⚠ dashboard.html exists in both root and templates/
- ✗ No static/ folder: CSS/JS inlined
Flask App Entry Point
dashboard/app.py
from flask import Flask, jsonify, request
from pymongo import MongoClient
from dotenv import load_dotenv
import os, certifi, pytz
load_dotenv()
app = Flask(__name__)
# MongoDB connection (TLS + certifi)
client = MongoClient(
os.getenv("MONGO_URI"),
tlsCAFile=certifi.where()
)
db = client["light_sensor_db"]- ✓ .env for secrets ✓ TLS via certifi
- ✗ All routes in one file: no blueprints
Sensor Data Simulation
dashboard/app.py · generate_sensor_reading()
import random, datetime, pytz
def generate_sensor_reading():
pst = pytz.timezone("America/Los_Angeles")
hour = datetime.datetime.now(pst).hour
# Vary lux by time of day
base = 30 if 8 <= hour <= 18 else 10
lux = round(random.uniform(0, base + 20), 2)
return lux # range: 0–50
def classify_lux(lux):
if lux < 5: return "Dark", "#333", "🌑"
if lux < 15: return "Dim", "#666", "🌘"
if lux < 30: return "Normal", "#f5a623", "🌤"
if lux < 45: return "Bright", "#ffd700", "☀️"
return "Very Bright", "#fff", "🌞"- ✗ Simulated: not reading real BH1750 sensor
- ⚠ Max 50 lx vs BH1750 max 65,535 lx
GET /api/sensor: Current Reading
dashboard/app.py · /api/sensor
@app.route("/api/sensor")
def get_sensor():
lux = generate_sensor_reading()
level, color, icon = classify_lux(lux)
return jsonify({
"lux": lux,
"level": level,
"color": color,
"icon": icon,
"timestamp": datetime.datetime.utcnow()
.isoformat() + "Z"
})
# Example response:
# {
# "lux": 28.4,
# "level": "Normal",
# "color": "#f5a623",
# "icon": "🌤",
# "timestamp": "2026-02-10T15:30:00Z"
# }GET /api/history & /api/stats
dashboard/app.py · history + stats routes
@app.route("/api/history")
def get_history():
room = request.args.get("room_id", "living")
limit = int(request.args.get("limit", 50))
col = db[f"room_{room}"]
docs = list(col.find({},{"_id":0})
.sort("timestamp",-1)
.limit(limit))
return jsonify({"room_id": room,
"count": len(docs),
"events": docs})
@app.route("/api/stats")
def get_stats():
room = request.args.get("room_id","living")
col = db[f"room_{room}"]
docs = list(col.find({}, {"lux":1}))
luxes = [d["lux"] for d in docs if "lux" in d]
return jsonify({
"avg_lux": round(sum(luxes)/len(luxes),2),
"min_lux": min(luxes),
"max_lux": max(luxes),
"count": len(luxes)
})Usage Save & Statistics Endpoints
dashboard/app.py · /api/usage/save · /api/usage/statistics
@app.route("/api/usage/save", methods=["POST"])
def save_usage():
data = request.json
data["saved_at"] = datetime.datetime.utcnow()
db["daily_usage"].insert_one(data)
return jsonify({"status": "saved"})
@app.route("/api/usage/statistics")
def usage_statistics():
today = datetime.date.today().isoformat()
# Exclude today: partial day
docs = list(db["daily_usage"].find(
{"date": {"$ne": today}}, {"_id":0}
))
weekly = sum(d.get("hours",0) for d in docs[-7:])
monthly = sum(d.get("hours",0) for d in docs[-30:])
return jsonify({"weekly_hours": weekly,
"monthly_hours": monthly})Room-Level Endpoints
dashboard/app.py · /api/rooms/<room> · /api/rooms/all/<date>
# Per-room usage
@app.route("/api/rooms/<room>")
def room_data(room):
doc = db[f"room_{room}"].find_one(
sort=[("timestamp", -1)]
)
return jsonify(doc or {})
# All rooms for a date
@app.route("/api/rooms/all/<date>")
def all_rooms(date):
rooms = ["living","bedroom","kitchen",
"bathroom","office","garage"]
result = {}
for r in rooms:
doc = db[f"room_{r}"].find_one(
{"date": date}, {"_id":0}
)
result[r] = doc or {}
return jsonify(result)User Authentication
dashboard/app.py · /api/user/login
from hashlib import pbkdf2_hmac
import os
@app.route("/api/user/login", methods=["POST"])
def user_login():
data = request.json
username = data["username"]
password = data["password"]
user = db["user_logins"].find_one(
{"username": username}
)
if not user:
# First-time: register with hashed pw
salt = os.urandom(16)
hashed = pbkdf2_hmac(
"sha256", password.encode(),
salt, 100000
)
db["user_logins"].insert_one({
"username": username,
"password": hashed, "salt": salt
})
return jsonify({"status": "registered"})
# Verify existing user
hashed = pbkdf2_hmac(
"sha256", password.encode(),
user["salt"], 100000
)
ok = hashed == user["password"]
return jsonify({"status":"ok" if ok else "fail"})Logging Endpoints
dashboard/app.py · admin · device · alert logging
# Admin access log
@app.route("/api/log/admin", methods=["POST"])
def log_admin():
db["admin_logs"].insert_one({
**request.json,
"ts": datetime.datetime.utcnow()
})
return jsonify({"status": "logged"})
# Device activation log
@app.route("/api/log/device", methods=["POST"])
def log_device():
db["device_activity"].insert_one(request.json)
return jsonify({"status": "logged"})
# Alert: light on too long (>40 min)
@app.route("/api/log/alert", methods=["POST"])
def log_alert():
data = request.json
# triggered when light ON > 40 minutes
db["alerts"].insert_one(data)
return jsonify({"status": "alert_logged"})Dashboard Layout: HTML Structure
dashboard/templates/dashboard.html · layout
<!-- Top-level layout -->
<body>
<div class="app-container">
<!-- Left sidebar -->
<aside class="sidebar">
<div class="clock">...</div>
<div class="mini-calendar">...</div>
<div class="donut-chart">...</div>
<div class="room-bars">...</div>
</aside>
<!-- Main content -->
<main class="content">
<div class="room-cards">...</div>
<div class="gauge-panel">...</div>
<div class="controls">...</div>
<div class="stats-section">...</div>
</main>
</div>
</body>- ✓ All-in-one dark UI
- ✗ CSS/JS inlined: no separate static files
Lux Gauge Component
dashboard/templates/dashboard.html · gauge-panel
<!-- SVG gauge: 0–50 lux range -->
<svg class="gauge" viewBox="0 0 200 120">
<path class="gauge-bg"
d="M 20,100 A 80,80 0 0,1 180,100"
fill="none" stroke="#333" stroke-width="16"/>
<path class="gauge-fill"
id="gauge-arc"
d="M 20,100 A 80,80 0 0,1 180,100"
fill="none" stroke="#f5a623"
stroke-width="16"
stroke-dasharray="0 251"/>
<text id="gauge-value" x="100" y="95"
text-anchor="middle"
font-size="24" fill="#fff">--</text>
<text x="100" y="115"
text-anchor="middle"
font-size="10" fill="#888">lux</text>
</svg>
// JS update
function updateGauge(lux) {
const pct = lux / 50;
const dash = pct * 251;
document.getElementById("gauge-arc")
.style.strokeDasharray = `${dash} 251`;
document.getElementById("gauge-value")
.textContent = lux.toFixed(1);
}Room Control Cards
dashboard/templates/dashboard.html · room-cards
<!-- Generated for each of 6 rooms -->
<div class="room-card" data-room="living">
<div class="room-icon">🛋️</div>
<div class="room-name">Living Room</div>
<div class="room-lux" id="lux-living">--</div>
<div class="room-status"
id="status-living">--</div>
<div class="room-duration"
id="dur-living">0 min</div>
</div>
// Poll every 3 seconds
setInterval(() => {
fetch("/api/sensor")
.then(r => r.json())
.then(d => {
document.getElementById("lux-living")
.textContent = d.lux + " lx";
});
}, 3000);Sidebar: Clock & Calendar
dashboard/templates/dashboard.html · sidebar
// Real-time PST clock
function updateClock() {
const pst = new Date().toLocaleString(
"en-US",
{ timeZone: "America/Los_Angeles",
hour: "2-digit", minute: "2-digit",
second: "2-digit", hour12: true }
);
document.getElementById("clock")
.textContent = pst;
}
setInterval(updateClock, 1000);
// Mini calendar navigation
function prevMonth() { currentMonth--; renderCalendar(); }
function nextMonth() { currentMonth++; renderCalendar(); }
function renderCalendar() {
// builds grid of <td> for each day
// highlights today
}Sidebar: Donut Chart (Daily Usage)
dashboard/templates/dashboard.html · donut-chart
<!-- SVG donut: hours used / 24 -->
<svg viewBox="0 0 100 100">
<circle cx="50" cy="50" r="40"
fill="none" stroke="#222"
stroke-width="12"/>
<circle cx="50" cy="50" r="40"
fill="none" stroke="#f5a623"
stroke-width="12"
stroke-dasharray="0 251"
id="donut-arc"
transform="rotate(-90 50 50)"/>
<text x="50" y="55"
text-anchor="middle"
font-size="14" fill="#fff"
id="donut-label">0h</text>
</svg>
function updateDonut(hoursOn) {
const pct = hoursOn / 24;
const arc = pct * 251;
donutArc.style.strokeDasharray =
`${arc} 251`;
donutLabel.textContent = hoursOn + "h";
}Screensaver & Wallpaper Customization
dashboard/templates/dashboard.html · screensaver · wallpaper
// Screensaver: activates after 15 s idle
let idleTimer;
function resetIdle() {
clearTimeout(idleTimer);
idleTimer = setTimeout(showScreensaver, 15000);
}
document.addEventListener("mousemove", resetIdle);
document.addEventListener("keydown", resetIdle);
function showScreensaver() {
document.getElementById("screensaver")
.style.display = "flex"; // shows PST clock
}
// 12 preset wallpapers
const WALLPAPERS = [
"linear-gradient(135deg,#1a1a2e,#16213e)",
"linear-gradient(135deg,#0d0d0d,#1a0a0a)",
// ... 10 more gradients / photo URLs
];
function setWallpaper(i) {
document.body.style.background = WALLPAPERS[i];
}Data Persistence: localStorage
dashboard/templates/dashboard.html · auto-save
// Save usage to localStorage AND MongoDB
function saveUsage() {
const payload = {
date: new Date().toISOString().slice(0,10),
hours: roomDurations["living"] / 3600,
wallpaper_id: currentWallpaper
};
// 1. Local persistence
localStorage.setItem(
"usage_" + payload.date,
JSON.stringify(payload)
);
// 2. Remote persistence
fetch("/api/usage/save", {
method: "POST",
headers: {"Content-Type":"application/json"},
body: JSON.stringify(payload)
});
}
// Auto-save every 5 minutes
setInterval(saveUsage, 300000);Unit Tests: app_test.py
dashboard/tests/app_test.py
import sys
sys.path.insert(0, "..")
from app import get_sensor_level, generate_sensor_reading
# Test 1: lux=10 → "Dark"
def test_sensor_status_dark():
assert get_sensor_level(10) == "Dark"
# Test 2: lux=30 → "Normal"
def test_sensor_status_normal():
assert get_sensor_level(30) == "Normal"
# Test 3: 100 readings stay within 0–50
def test_generate_sensor_range():
for _ in range(100):
val = generate_sensor_reading()
assert 0 <= val <= 50, \
f"Out of range: {val}"Backend → Frontend Interface Contract
app/architect/interface/backend-frontend.md
# GET /api/sensor/current?room_id=room-101
# Cache: 3 s · Returns: lux · state · freshness
# GET /api/history
# ?room_id=room-101 &limit=500
# ?start_time=ISO &end_time=ISO
# Cache: 30 s
# GET /api/stats?room_id=room-101
# Cache: 5 min
# Returns: avg_lux · min · max · count
# CORS allowed origins:
# https://se4cps.github.io
# https://iot-dashboard.onrender.com
# http://localhost:5001
# Methods: GET · OPTIONS only
# Error shape:
# { "error": "...", "detail": "...",
# "timestamp": "...", "request_id": "..." }Frontend Improvements Roadmap
dashboard/ · app/architect/interface/backend-frontend.md
# Key improvements
# 1. Replace simulated lux with real sensor
# fetch("/api/sensor/current?room_id="+room)
# instead of generate_sensor_reading()
# 2. Fix gauge range
# const MAX_LUX = 65535; // BH1750 max
# const arc = (lux / MAX_LUX) * 251;
# 3. Add session token after login
# const { token } = await fetch("/api/user/login")
# localStorage.setItem("token", token)
# 4. Per-room polling
# rooms.forEach(r =>
# fetch(`/api/sensor/current?room_id=${r}`)
# )
# 5. Replace setInterval with
# Page Visibility API to pause when hiddenQuestions?
Weekend Test: IoT Light Sensor App
dashboard/app.py · dashboard/tests/app_test.py · embedded/BH1750_test.ino
- Leave the device running Friday → Monday and record observations
- Verify sensor readings, backend ingestion, dashboard updates, and alerts end-to-end
# Weekend test checklist
# EMBEDDED
# [ ] BH1750 reads lux every 3 s without freeze
# [ ] Serial monitor shows no 0.0 lux gaps
# [ ] WiFi reconnects after router reboot
# BACKEND (Render.com)
# [ ] POST /api/events accepted (202) all weekend
# [ ] No 429 rate-limit hits in logs
# [ ] MongoDB Atlas event count grows as expected
# DASHBOARD
# [ ] Room cards update every 3 s
# [ ] Usage stats persist across browser refresh
Today's Agenda
- Weekend Test
- Sprint 13
- Word Cloud Definition
Weekend Test 3
Project in Numbers
Milestones: Sprint #1–5 (1 of 3)
Milestones: Sprint #6 & #8–10 + MVP #1 (2 of 3)
Milestones: Sprint #11–13 + Future (3 of 3)
70 closed · 21 open · 91 tickets across 10 milestones
Sprint Velocity: Tickets Closed per Sprint
What's Next: Beyond the V-Model
- V-Model: requirements → test at every level
- Scrum sprints inside the V shape
- Embedded + API + Dashboard pipeline
- CI/CD closing the verification loop
- Two teams, one backlog, 13 sprints
- 4.0: Cyber-Physical, IoT, automation (now)
- 5.0: Human-centric + AI collaboration
- 6.0: Cognitive, autonomous, self-healing
- V-Model becomes a continuous loop
- Tests write themselves; systems self-correct
You built a real Industry 4.0 system: the skills transfer forward.
Industry 4.0 → 5.0
- ESP32 sensor → MQTT → Flask API → MongoDB
- Real-time dashboard via REST + BLE
- CI/CD pipeline on GitHub Actions
- Automated alerts (light on > 12 h)
- Focus: machines talk to machines
- Human operators collaborate with AI agents
- Systems adapt to context, not just rules
- Sustainability + resilience by design
- LLM-assisted maintenance & anomaly detection
- Focus: humans + machines co-create
Industry 5.0 → 6.0: Where to Aim
- Cognitive manufacturing
- Digital twins at scale
- Autonomous V-Model: AI writes tests & code
- Self-healing distributed systems
- Zero-touch deployment
- LLM & agent orchestration
- Edge AI (TinyML on ESP32)
- Distributed systems & consensus
- Formal verification
- Observability & SRE
- Add ML anomaly detection to your sensor data
- Build a digital twin of the room model
- Wire an LLM to auto-triage GitHub issues
- Replace manual sprints with AI planning
- Publish your system as open source
The V-Model does not disappear: it becomes the skeleton inside every autonomous pipeline.
Pure Software Engineering
- Code runs on servers you control
- Bugs → rollback & redeploy
- Deterministic, predictable environment
- One platform: browser or cloud
- Unlimited power & connectivity
- Testing in an emulator is enough
IoT / CPS Software Engineering
- Code controls physical actuators
- Bugs → damage, data loss, or injury
- Sensor noise, HW faults, real-time clocks
- Firmware + cloud + mobile + edge
- Battery-aware, BLE / LoRa / MQTT
- Real hardware required to test
- OTA updates in the field, no rollback
The physical world makes every bug consequential.





V-Model in Industry 4.0 — The Manual V
Sequential phases · manual hand-offs · fixed verification gates · human review at every checkpoint
V-Model in Industry 5.0 — The Assisted V
AI co-pilots at every phase · humans retain control · continuous feedback replaces one-way hand-offs
V-Model in Industry 6.0 — The Cognitive Loop
The V dissolves into a continuous cognitive loop · AI agents manage the full pipeline end-to-end
Recommended Reading

Industry 5.0 + 4.0
+ Society 5.0:
Technology for People

Industry 6.0:
Technology, Practices,
Challenges & Applications

Cyber-Physical Systems
for Industrial
Transformation

Industry 6.0:
Impediments &
Future Trends
Click any cover to open on Amazon
Syllabus
Software Engineering in Industry 4.0 Ecosystems (COMP 233)
Class Schedule:
Time: 12:30 PM: 1:25 PM on Monday, Wednesday, Friday
Location: Benerd School of Education 208
Course Description
In this course on Software Engineering within Industry 4.0 ecosystems, we will explore the integration and application of IoT and Cyber-Physical Systems (CPS). The course takes a dual perspective approach.
- First, we focus on the design aspect, the team structure, the requirements, the user interface design, the architecture, and tracking.
- Second, we focus on the implementation, integration, testing, verification, validation, release, and maintenance part.
Industry 4.0 Ecosystem Exploration 1/2
- Exploring the requirements specific to Industry 4.0 ecosystems and their influence on software engineering practices
- Understanding the dynamics of team organization and coordination within these ecosystems.
- Examining resource constraints and their implications in Industry 4.0 settings
- Investigating the legal frameworks and regulations affecting Industry 4.0 projects
- Analyzing architectural constraints, including system design and scalability considerations.
- Studying the security challenges and strategies within Industry 4.0
- Reviewing resource management, optimization, and constraints in software projects
Industry 4.0 Ecosystem Exploration 2/2
- Delving into the developme nt processes, standards, methodologies, and best practices for Industry 4.0 applications
- Focusing on testing and verification procedures specific to these advanced systems
- Addressing dependencies management in complex software environments
- Reviewing release cycles and continuous delivery in the context of Industry 4.0
- Updating strategies and lifecycle management for software in this dynamic field
- Integrating AI technologies with Industry 4.0 systems, exploring synergies and innovative solutions
Prerequisites
- COMP 51: Fundamental programming skills
- COMP 53: Basic data structures and algorithms
Teaching Assistant
| Teaching Assistant: | TBD |
| Email: | TBD |
| Office Location: | Student Support Center |
| Office Hours: | By appointment |
Instructor
| Instructor: | Dr. Solomon Berhe |
| Email: | sberhe@pacific.edu |
| Zoom: | Zoom Meeting Link |
| Office: | CTC 117 |
| Office Hours: | Mon/Wed/Fri, 2:00–3:15 PM (or by appointment) |
Textbooks:
Grading
- Labs: 15%
- Homework: 15%
- Project: 40%
- Exams: 30%
Course Topics
- Industry 4.0 Ecosystems and Software Engineering Integration
- Organizational Dynamics in I4.0
- Addressing Legal Constraints
- Architectural Design Principles in I4.0
- Security Measures and Strategies
- Resource Management in I4.0 Environments
- Development Processes for I4.0 Applications
- Testing and Verification Methods
- Managing Dependencies in I4.0 Projects
- Release and Update Strategies for I4.0 Systems
- Incorporating AI in I4.0 Solutions
Assignments and Exams
| Homework: | Includes written exercises and programming assignments. Submit via Canvas or GitHub. |
| Team Projects: | Two projects (design, development, and application integration) |
| Exams: | One midterm and one final. commonly may bring one handwritten note sheet (8.5x11) |
Policies
- Attendance and Participation: Active participation is required. Additional points may be awarded for consistent engagement
- Late Submissions:
- Late assignments accepted during the next class with a 20% penalty
- No makeup exams unless excused for valid reasons
- Academic Integrity: Academic dishonesty (e.g., plagiarism, cheating) will result in a grade of zero for the assignment or more severe penalties for repeated offenses.
- Collaboration: Collaborative problem-solving is encouraged but must stop short of sharing code or written work
- Accommodations: commonly requiring accommodations should contact
the Office
of Services for commonly with Disabilities at McCaffrey Center, Rm. 137.
- Phone: 209-946-3221
- Email: ssd@pacific.edu
- Website: Disabilities Support
Canvas and Course Updates
All course materials, announcements, and assignments will be posted on Canvas. Check regularly for updates
Honor Code
commonly are expected to act with integrity, honesty, and responsibility. Violations of the Honor Code will be reported to the Office of Student Conduct and Community Standards
For more details, see the University Academic Honesty Policy
Source Document: Course Syllabus
Questions?
Project = Sensor + Frontend + Backend + Database
Goal
Please inform me of the light status in the room
Sensor Layer
Light ON / OFF
Timestamped

Backend API Service
Receive
Validate
Store

Sample Data
{
"meta": {
"entity": "room_light_event",
"description": "Single light sensor observation per room",
"source": "indoor light sensor",
"version": "1.0",
"created_at": "ISO-8601 timestamp"
},
"data": {
"room_id": "string | integer",
"light_state": "ON | OFF",
"timestamp": "ISO-8601 timestamp"
}
}
Database

Dashboard
Current status
History
Notification Rule
Light ON > 12h
Process (Weekly Scrum)
┌───────────────┐ ┌────────────────┐ ┌──────────────────┐ ┌──────────────────┐ ┌─────────────────┐
│ 1. Planning │ → │ 2. Daily Scrum │ → │ 3. Refinement │ → │ 4. Demo / Review │ → │ 5. Retro │
│ What to build │ │ Sync & unblock │ │ Prepare backlog │ │ Show results │ │ Improve process │
└───────────────┘ └────────────────┘ └──────────────────┘ └──────────────────┘ └─────────────────┘
Same order · Same cadence · Every week
Agile Manifesto
Individuals and interactions
Working software
Customer collaboration
Responding to change
Foundational principles for iterative development
Project Roles
- Scrum Master
- Product Owner / Requirements Engineer
- Backend Engineer
- Frontend Engineer
- Embedded Engineer (Phone, Sensor)
- Software/Data Architect
- Software Developer
- Tester / Quality
- Release Engineer / DevOps
Feature Branch Workflow: Core Idea
- What is the purpose?
- Why avoid committing to main?
- Isolate feature development
- Keep main stable
- Enable parallel work
- Protect CI/CD pipeline
Feature Branch Workflow: Branching
- How are features organized?
- What is the branching rule?
- One branch per feature
- Use naming conventions
- No direct commits to main
- Independent development
Pull Requests
- Why use pull requests?
- What do they provide?
- Code review before merge
- Team validation
- Early bug detection
- Controlled integration
Rebasing
- Why prefer rebase?
- What problem does it solve?
- Clean commit history
- Applies commits on latest main
- Incremental conflict resolution
- Easier debugging
Main Branch Rule
- What must always hold?
- Builds successfully
- Passes tests
- Always deployable
- Stable baseline
Project Risk
- What risk occurred?
- Long-lived branch
- Diverged from main
- Conflicts in shared files
- Difficult merge
Risk Cause
- Why did this happen?
- Infrequent sync with main
- Parallel changes in core files
- Accumulated conflicts
- Delayed integration
Mitigation Strategy
- How was it fixed?
- Frequent pull/rebase
- Resolve conflicts early
- Short-lived branches
- Continuous integration
CI/CD Support
- How did CI help?
- Runs on every push
- Detects errors early
- Prevents broken merges
- Validates integration
Scrum vs V-Model
- When use Scrum?
- When use V-Model?
- Scrum → iterative, flexible
- V-Model → structured, verification
- Depends on system component
Scrum Use Cases
- Which parts use Scrum?
- UI/UX Design
- System Updates
- Feature Development
- Stakeholder Communication
V-Model Use Cases
- Which parts use V-Model?
- Legal Compliance
- Hardware Development
- Integration Testing
- End-to-End Testing
- Quality Assurance
Final Approach
- What is the final recommendation?
- Hybrid model
- Scrum for software iteration
- V-Model for validation & hardware
- Balance flexibility and reliability
Lab 4: AI-Assisted IoT Development
Reviewing what commonly found when using Copilot across the full engineering lifecycle: requirements, architecture, implementation, testing, and verification.
Task 1: Requirements Generation
Prompt given to Copilot:
Generate user requirements for an IoT indoor light sensor system that monitors ambient lux levels in a smart building and sends alerts when high lux is detected outside regular work hours.
What did Copilot produce? What did it leave out?
What did AI cover vs miss?
- AI covered functional requirements well
- Missed non-functional: latency, accuracy, uptime
- Missed operational: calibration, seasonal variation
- Common notes: high-level but not deployment-ready
Task 2: System Architecture
- Embedded sensor transmits via HTTP or MQTT
- Backend API validates and stores in MongoDB
- Dashboard queries backend via REST
- Alert engine monitors thresholds + work hours
- Notifications: email, SMS, push
Copilot proposed a 6-layer pipeline with clear separation of concerns.
Pro: Separation of Concerns
- Each layer can scale independently
- Swap MongoDB without touching sensor firmware
- Upgrade backend framework without changing dashboard
- Teams can own individual layers
Commonly correctly identified this as the main architectural benefit.
Con: Single Point of Failure
- Centralized backend = one failure point
- If it goes down: no ingest, no alerts, no dashboard
- Valid mitigations commonly identified:
- Local buffer on the embedded device
- MQTT broker with message persistence
- Retry logic with exponential backoff
Task 3: Backend API Implementation
Prompt: Write an API endpoint that receives POST requests with sensor readings, validates input, stores in MongoDB, and returns a status response.
- Fields:
sensorId,lux,timestamp - Copilot produced a working Express + Mongoose scaffold
- One student was asked if Copilot should commit it directly: they declined
What the Generated API Is Missing
- No authentication: any device can write
- No range validation: lux could be -999
- No rate limiting: 100 sensors burst at once
- No retry / dead-letter queue on DB failure
Copilot produces a functional scaffold, not a production-ready service.
Should Copilot Commit Directly?
- Copilot offered to commit the generated file to the repo
- Commonly declined: a deliberate choice
- Pro: saves boilerplate commit time
- Con: unreviewed code enters version history
Treat AI output like a PR from a new contributor: read every line before merging.
Task 4: Unit Testing
Prompt: Generate unit tests for classifyLight(lux).
'dark': lux < 50'dim': 50 ≤ lux < 150'normal': 150 ≤ lux ≤ 500'bright': lux > 500
Copilot produced 38 test cases covering boundaries, null, NaN, Infinity, and negatives.
Boundary Value Analysis
- Test one value below, at, and above each boundary
- Reveals off-by-one errors that range tests miss
- Copilot naturally applies this pattern when asked to "account for edge cases"
This is standard test technique: AI executes it reliably for pure functions.
38 Tests: Too Many?
- Copilot produced 38 tests for a 4-branch function
- Pro: exhaustive, catches every edge case
- Con: maintenance overhead, slower CI, harder to diagnose failures
- A focused suite of ~12 tests covers the same risk
Task 5: System-Level Test Plan
Prompt: Describe a system test plan that checks end-to-end data flow from sensor reading to dashboard, including latency and alert accuracy.
- 12 end-to-end test cases
- End-to-end latency ≤ 3 seconds
- API response ≤ 500 ms, dashboard render ≤ 1 s
- Alert boundary tests: 299 / 300 / 300.01 lux
- 6-week execution timeline
Unit Test vs System Test
- Unit: one function in isolation, fast, no services needed
- System: full pipeline running, sensors to dashboard
- Both are necessary: they catch different classes of bug
- AI generates both but needs guidance on scope
Copilot Across the V-Model
- Requirements: functional ✓, non-functional ✗
- Architecture: layer separation ✓, resilience ✗
- Implementation: scaffold ✓, auth / rate limit ✗
- Unit test: boundaries ✓, test count discipline ✗
- System test: thorough plan ✓, automation strategy ✗
Where AI Tools Add the Most Value
- Generating boilerplate: schemas, routes, CRUD
- Covering happy-path requirements quickly
- Producing boundary test cases for pure functions
- Structuring test plans with concrete metrics
Where AI Tools Fall Short in IoT
- Sensor noise, drift, and calibration strategy
- Latency and reliability requirements
- Authentication for embedded devices
- Offline handling and reconnect logic
- Real-world data: fluctuating readings, seasonal variation
These require domain knowledge that AI cannot infer from a prompt.
MongoDB Schema Design
- Collection:
sensor_readings - Index on
(sensorId, timestamp desc): dashboard queries - Validate:
lux ≥ 0,sensorIdrequired - Store raw events: derive aggregates later
Copilot produced the schema; commonly correctly noted missing range validation.
Review: Valid Answers from commonly
- What type of requirement did AI most often skip?
- Name one way to handle a backend outage.
- What is one risk of letting Copilot commit directly?
- Why test at 299, 300, and 300.01 lux specifically?
- What makes a 6-week test plan hard to execute?
Takeaway: AI as a Co-Engineer
V-Model + Agentic AI / LLM / RAG
Homework 4: IoT-LLM Research Application
Three techniques from the paper applied to the lux sensor system: data preprocessing, RAG with re-ranking, and chain-of-thought prompting.
Why LLMs Struggle with Raw Sensor Data
- LLMs are trained on natural language, not numeric streams
- 720 raw lux floats per hour carry no room context
- LLM cannot distinguish noise from anomaly without metadata
- Sending raw data: GPT-4o-mini accuracy = 37.3%
All three homework examples address this root problem.
Example 1: Data Preprocessing
Research idea: simplify + enrich raw sensor data before the LLM sees it.
- Compute statistics: mean, variance, min, max, trend
- Add metadata: room name, sensor placement, units, sampling rate, expected range
- Result: a short natural-language description instead of a raw array
Accuracy: 37.3% → 43.3%
What Statistical Features to Extract
- Mean lux over a time window (e.g., 1-min or 5-min)
- Variance: stable vs. fluctuating light
- Min / max: detect clipping or spikes
- Rate of change / trend: gradual fade vs. sudden drop
- FFT mean: frequency-domain pattern
Commonly applied 1-min averages (720 → 60 values), rolling stats, and scalar quantization (32-bit float → 8-bit int, 4× compression).
What Metadata to Attach
- Room name and type (office, hallway, server room)
- Sensor placement (ceiling, window-facing, table)
- Window orientation (south-facing = morning sunlight)
- Unit (lux), sampling rate, expected range
- Time context (daytime, after-hours, unoccupied schedule)
Without metadata: LLM sees "15." With metadata: "Room B server room, ceiling, south window, 15 lux at 11 PM outside work hours."
Pipeline Before and After
- Before: Sensor → DB → Dashboard → "250"
- After: Sensor → Enrichment → DB → LLM → Dashboard → "720 lux is too high for living room during daytime"
- LLM replaces hard-coded if/else rules
- MongoDB becomes a knowledge layer, not just storage
Example 2: RAG: Retrieval-Augmented Generation
Research idea: automatically retrieve domain knowledge + labeled demonstrations instead of hard-coding expert rules.
- Build a knowledge base: lighting standards, anomaly patterns, Q&A demos
- At inference time: hybrid search retrieves 2–3 most relevant passages
- Inject retrieved context into LLM prompt
- LLM grounds its answer in standards, not guesses
Accuracy: 43.3% → 59.3% (+ demos: 66.7%)
What the Knowledge Base Contains
- Lighting standards (server room: 300–500 lux, hallway: 0–300)
- Anomaly pattern descriptions (sudden drop = fixture failure vs. power cut)
- Labeled demo Q&A from historical MongoDB data
- Sensor placement and calibration notes
- Alert rules and Swagger API behavior
Commonly noted: MongoDB history already contains this: the KB is curated from existing sprint data.
Re-ranking: Retrieve n, Keep m
- Retrieve n = 5 candidate documents from knowledge base
- Re-ranker scores relevance to the specific query
- Keep only m = 1–2 most relevant passages for the LLM
- Discards: outdoor lighting, night rules (irrelevant to hallway daytime query)
Too many docs (m=5) → LLM output becomes noisy and inconsistent.
Why Focused Retrieval Beats Stuffing Context
- Each irrelevant document adds noise to the prompt
- LLMs can be "distracted" by off-topic but plausible passages
- Small, high-precision context = better reasoning
- Optimal: n ≈ 3–5 retrieved, m ≈ 1–2 kept
Commonly identified this as the key trade-off: more retrieval ≠ better answers.
Example 3: Chain-of-Thought + Role
Research idea: assign the LLM a domain-expert role and require step-by-step reasoning before a final answer.
- Role: "You are a building lighting systems engineer"
- Require two sections: ANALYSIS then ANSWER
- LLM must cross-reference rooms, schedule, and retrieved knowledge
- Dashboard shows the reasoning trace, not just the label
Accuracy: 66.7% → 77.8%
CoT in Action: Room C at 11 PM
- Room C: 600 lux at 11 PM
- Rooms A + B: 0–5 lux
- Building scheduled as unoccupied
ANALYSIS: cross-reference schedule + compare all rooms.
ANSWER: "Lights left on; check motion sensor and relay; ~0.6 kWh/hr energy waste."
Without CoT: "high lux anomaly detected." With CoT: actionable diagnosis with energy cost.
Accuracy at Each Step (GPT-4o-mini)
- Baseline (raw data): 37.3%
- + Preprocessing: 43.3% (+6 pts)
- + RAG retrieval: 59.3% (+16 pts)
- + Demonstrations: 66.7% (+7 pts)
- + Role + CoT: 77.8% (+11 pts)
Each technique adds independently; the combination achieves expert-level reasoning.
All Three Techniques Combined
- Preprocessing: sensor → enriched description
- RAG: query KB → re-rank → inject 2 docs
- CoT: role + retrieved + data → step analysis → answer
- Each layer builds on the previous one
- LLM acts as a reasoning layer, not a lookup table
Commonly confirmed: combination outperforms any single technique alone (ablation result).
LLM as Reasoning Layer vs Rule Engine
- Old approach: hard-coded if/else for every alert condition
- New approach: LLM interprets enriched context dynamically
- No need to enumerate every edge case manually
- New room or anomaly type → add docs to KB, not new rules
Commonly noted: KB is extensible: one team can add domain docs without rewriting reasoning logic.
What Changes on the Dashboard
- Before: a number: "250"
- After: an explanation: "720 lux is too high for living room during daytime (expected 0–300)"
- ANALYSIS section: step-by-step reasoning trace
- ANSWER section: final recommendation with action
- Facility managers can verify or challenge the AI's reasoning
Dimensionality Reduction: Scalar Quantization
- Normalize:
lux / max_range - Quantize:
int((lux / 300) × 255)→ 8-bit integer - Before: 8 values × 4 bytes = 32 bytes
- After: 8 values × 1 byte = 8 bytes (4× compression)
- Vector sent to API instead of raw floats
Smaller payload = faster transmission + cheaper storage. Vector space enables semantic similarity.
Per-Sensor Context Matters
- Sensor 2 near window: 10,000–15,000 lux in sunlight
- Dashboard cap at 800 lux flattened the display
- Raw data was correct; the display made it look wrong
- LLM summary: "Sensor 2, near window, current 12,400 lux, dashboard likely clipping"
- Distinguishes sensor fault from display artifact
Review: Common Valid Answers
- Why can't an LLM reason over raw lux floats?
- What two things does preprocessing add?
- Why retrieve n=5 but only inject m=2 into the prompt?
- What is the role of a "demo Q&A pair" in the knowledge base?
- Why show ANALYSIS + ANSWER on the dashboard?
Takeaway: IoT + LLM Design Principles
Topic
- V-Model vs Project Timeline
- Regression Testing
- Focus: third-party software updates
- : Operating system updates
- : Browser & runtime updates
- : Predictive maintenance of hardware
- : Firmware & dependency upgrades
Also Today
- Review Homework & Labs
- Sprint Demo 12
The V-Model Fits Inside the Contract Timeline
V-Model & Regression Testing: During & Beyond
What Is Regression Testing?
- Re-running existing tests after any change to verify nothing broke
- Change source can be your code or something beneath it
- Third-party updates are the silent risk: you did nothing, yet things break
- Goal: detect breakage before users do
Third-Party Update Categories
- OS updates: kernel changes, file permission model
- OS updates: deprecated APIs, security patches that alter behavior
- Browser / runtime: Chrome V8, Node.js
- Browser / runtime: WebView engine version: JS/CSS rendering changes
- Firmware: sensor calibration drift
- Firmware: Edge controller OS patches, driver ABI changes
- Predictive HW maintenance: sensor degradation over time triggers
- Predictive HW maintenance: false readings before full failure
Regression Testing Strategy
- Automated test suite: run on every dependency update via CI/CD
- Pinned versions: lock OS image and firmware version;
- Pinned versions: upgrade on a controlled schedule
- Canary deployment: roll update to one garage node first
- Canary deployment: monitor 24h before fleet-wide
- Hardware health checks: daily lux baseline self-test;
- Hardware health checks: alert if drift > 10%
- Rollback plan: keep previous firmware image
- Rollback plan: one-command rollback via OTA
Q1: What is a Cyber-Physical System (CPS)?
- Software that simulates physical environments digitally
- A system coupling computation with physical processes
- A real-time OS for embedded industrial hardware
- A protocol linking IoT sensors to cloud platforms
Answer: B: Integrates computation, networking & physical processes
Q2: What characterized Industry 1.0?
- Mass production powered by electricity and assembly lines
- Automation driven by computers and electronics
- Smart factories using IoT, AI, and connected sensors
- Mechanical production powered by water and steam
Answer: D: Mechanical production powered by water and steam
Q3: What drove Industry 2.0?
- Electrification, steel, and mass production assembly lines
- Steam engines and mechanized textile mills
- Programmable logic controllers and robotics
- Cloud computing and machine learning algorithms
Answer: A: Electrification, steel, and mass production
Q4: What best describes Industry 3.0?
- Water-wheel mills and early steam-driven factories
- Steel production and electrified assembly lines
- Electronics, IT systems, and programmable automation
- Cyber-physical systems connected via the Internet of Things
Answer: C: Electronics, IT systems, and programmable automation
Q5: What best defines Industry 4.0?
- Shift from manual craftwork to mechanized steam-powered labor
- Integration of CPS, IoT, AI, and real-time data across physical systems
- Deployment of standalone mainframe computer systems
- Adoption of electrical grids and standardized assembly lines
Answer: B: CPS + IoT + AI + real-time data integration
Q1: What is an Epic in requirements engineering?
- A high-level requirement grouping related features
- A sprint review meeting held with stakeholders
- A single testable condition inside a user story
- A deployment checklist before a production release
Answer: A: A high-level requirement grouping related features
Q2: What is the correct User Story format?
- Given / When / Then a condition is satisfied
- Title / Description / Effort estimate in points
- As a [role], I want [action], Because [reason]
- Epic / Sprint / Acceptance criteria are met
Answer: C: As a [role], I want [action], Because [reason]
Q3: What do Acceptance Criteria define?
- Documents the tech stack chosen for the project
- Assigns story-point effort to each backlog item
- Specifies deployment targets for each release cycle
- Defines testable conditions a user story must meet
Answer: D: Defines testable conditions a user story must meet
Q4: What do Implementation Tasks focus on?
- What the end user needs from the system
- How the system is built using chosen technologies
- Grouping related user stories under one theme
- Defining SLA thresholds for uptime and latency
Answer: B: How the system is built using chosen technologies
Q5: What is a Product Backlog?
- A prioritized list of epics, stories, and tasks
- A record of all bugs found during QA testing
- A Gantt chart mapping milestones to release dates
- A log of completed sprints and team velocity trends
Answer: A: A prioritized list of epics, stories, and tasks
Q1: What does Conway's Law state?
- Agile teams always outperform waterfall teams in delivery
- Hardware constraints must be resolved before sprints begin
- Team size determines the total number of components
- Systems mirror the communication structure of their team
Answer: D: Systems mirror their team's communication structure
Q2: What is the purpose of the Stand-up meeting?
- To demo the working sprint increment to stakeholders
- To sync progress, share plans, and surface blockers
- To choose sprint work and define success criteria
- To reflect on process and capture team improvements
Answer: B: Sync progress, share plans, surface blockers
Q3: Which team structure does Agile/Scrum use?
- Teams organized in strict top-down reporting hierarchies
- Modular teams each owning one independent system layer
- Cross-functional product teams working together in sprints
- Functional silos grouped by technical discipline and role
Answer: C: Cross-functional product teams working in sprints
Q4: Why can't hardware follow agile sprint cycles?
- Physical changes are costly, slow, and hard to reverse
- Hardware teams lack access to sprint planning tools
- Hardware components do not require testing like software
- Agile methodology was designed only for frontend teams
Answer: A: Physical changes are costly, slow, and hard to reverse
Q5: What does the Sprint Retrospective focus on?
- Selecting backlog items for the upcoming sprint cycle
- Demonstrating the working increment to product stakeholders
- Grooming and refining items in the product backlog
- Reflecting on the process and defining team improvements
Answer: D: Reflecting on process and defining team improvements
Q1: What does CSF 2.0 "Protect" focus on?
- Log events, monitor health, and alert on anomalies
- Triage reported vulnerabilities and patch them quickly
- Encrypt data, control access, and verify signed updates
- Assign ownership of risks and document all decisions
Answer: C: Encrypt data, control access, verify signed updates
Q2: What does "shift left" mean in the SSDF?
- Address security and testing earlier in development
- Moving deployment pipelines from cloud to on-premise
- Shifting sprint work from backend to frontend roles
- Reducing the number of release stages before production
Answer: A: Address security and testing earlier in development
Q3: What is the purpose of NIST SP 800-213?
- Define secure coding rules for web application backends
- Define IoT device requirements for procurement and design
- Map cybersecurity risk across a six-function process loop
- Standardize firmware update protocols across cloud platforms
Answer: B: Define IoT device requirements for procurement and design
Q4: Which CSF 2.0 function restores service after an incident?
- Contains the incident and assesses its full impact
- Logs all events and detects anomalies from sensors
- Defines acceptable risk levels and assigns team ownership
- Restores service, verifies stability, and prevents recurrence
Answer: D: Recover: restore service, verify stability, prevent recurrence
Q5: Why is Nature a first-class CPS stakeholder?
- Natural language is used to write IoT device requirements
- Environmental laws mandate IoT sensor calibration records
- Energy use and environmental impact shape system design
- Nature provides the raw data inputs for all IoT sensors
Answer: C: Energy use and environmental impact shape system design
Q1: What is software architecture?
- The UI design and frontend styling of an application
- The CI/CD pipeline that deploys code to production
- The shared blueprint of components, interfaces, and decisions
- The database schema used to model system entities
Answer: C: Components, interfaces, and early decisions
Q2: What does the Modularity architecture driver mean?
- Defining clear structural boundaries between components
- Ensuring the system recovers from any network failure
- Reducing total microservices in the deployment manifest
- Standardizing the deployment environment across all teams
Answer: A: Clear structural boundaries between components
Q3: Which style best fits independent service scaling?
- Monolith: one repo, one deploy, fast iteration
- Microservices: independent ownership and deployment
- Layered: UI to API to domain to data tiers
- Event-driven: decoupled producers and consumers
Answer: B: Microservices: independent ownership and deployment
Q4: What does a UML Component diagram show?
- The message sequence exchanged between services over time
- Runtime nodes, servers, and network topology of the system
- Core data structures and their relationships in the model
- Service boundaries and dependencies between components
Answer: D: Service boundaries and dependencies
Q5: When is Monolith the best architectural choice?
- Small team, fast iteration, and simple operational needs
- Many teams each owning one independently deployable service
- Real-time event streams requiring decoupling and replay
- Systems needing independent horizontal scaling per domain
Answer: A: Small team, fast iteration, simple ops
Q1: What does FOTA enable for IoT compliance?
- Generating audit logs for security review submissions
- Proving encryption coverage across all device channels
- Mapping backlog items directly to regulation IDs
- Delivering compliance corrections to deployed devices
Answer: D: Deliver compliance corrections to deployed devices
Q2: What does "reasonable security" mean legally?
- Maximum available encryption enforced on all IoT devices
- A fixed checklist defined and locked at product launch
- A standard that evolves with technology and case law
- Government-approved algorithms applied to all stored data
Answer: C: Evolves with technology, standards, and case law
Q3: How can evolving law affect backlog priority?
- It always reduces sprint velocity and slows feature delivery
- Legal risk can move compliance work ahead of new features
- It replaces the full backlog with mandatory legal tickets
- Regulatory work is deferred until after the product release
Answer: B: Legal risk can move compliance ahead of features
Q4: Which CPS layer handles Privacy, Retention, and Access?
- Data layer: manages privacy, retention, and access
- Firmware layer: validates input and manages fail-safe modes
- Connectivity layer: enforces BLE and TLS encryption
- UI/App layer: surfaces transparency controls to users
Answer: A: Data layer: privacy, retention, access
Q5: What is the legal risk of an unpatchable IoT device?
- It cannot connect to updated cloud service endpoints
- It fails automated compliance scanning in CI/CD gates
- It requires a full hardware recall and replacement cycle
- Liability increases as regulations and threats evolve
Answer: D: Liability increases as regulations and threats evolve
Q1: What does Verification check in V-Model?
- Whether the system meets real user needs in the field
- Whether artifacts like requirements and code are correct
- Whether the system handles peak load without degrading
- Whether deployed devices pass field acceptance criteria
Answer: B: Artifacts (requirements, design, code) are correct
Q2: What does Validation confirm in V-Model?
- That source code passes all static analysis lint checks
- That the API returns expected HTTP status codes
- That unit tests achieve a minimum code coverage target
- That the system delivers real user and business value
Answer: D: System delivers real user and business value
Q3: What test level covers the full end-to-end stack?
- System test: exercises the full integrated stack
- Unit test: isolates a single function or method
- Component test: tests a single service boundary
- Acceptance test: validates user-facing scenarios
Answer: A: System test: full integrated stack
Q4: What does the AAA pattern in TDD stand for?
- Authenticate, Authorize, Audit a system interaction
- Assign, Apply, Assess the impact of code changes
- Arrange, Act, Assert the expected test outcome
- Archive, Annotate, Approve pull request test results
Answer: C: Arrange, Act, Assert
Q5: What is the purpose of the V-Model in testing?
- To replace manual testing with fully automated pipelines
- To map each development phase to a corresponding test level
- To define the order of bug fixes within a sprint cycle
- To link unit test coverage targets to release gate metrics
Answer: B: Map each dev phase to a corresponding test level
Q1: Why do IoT devices use duty cycling?
- Boost CPU clock speed to handle peak sensor loads
- Alternate active and sleep states to cut power draw
- Synchronize data streams across multiple IoT sensor nodes
- Compress firmware binaries before each over-the-air update
Answer: B: Alternate active/sleep states to cut power draw
Q2: Which reduces data volume before cloud transmission?
- Increase sampling rate to capture more accurate readings
- Switch from TCP to MQTT to reduce packet overhead
- Upload raw sensor data to cloud for later filtering
- Filter and aggregate sensor readings at the edge first
Answer: D: Filter and aggregate at the edge before sending
Q3: What is the key tradeoff of delta compression in IoT?
- Lower bandwidth use at the cost of more local processing
- Reduce latency by skipping redundant checksum validation steps
- Extend battery life by doubling the transmission interval set
- Shrink firmware size by removing unused protocol stack libraries
Answer: A: Lower bandwidth at cost of more local processing
Q4: Which approach most extends IoT device battery life?
- Run the MCU at full clock speed between every sensor poll
- Use cellular LTE instead of BLE for longer communication range
- Put the MCU in deep sleep between each sensor read cycle
- Cache all readings in flash for scheduled weekly batch uploads
Answer: C: Deep sleep between sensor reads extends battery life
Q1: What does a SQL injection attack exploit?
- Unsanitized user input merged directly into database queries
- Weak encryption keys used during TLS certificate handshakes
- Open ports left exposed by a misconfigured IoT gateway
- Unencrypted firmware images stored in device flash memory
Answer: A: Unsanitized user input merged into database queries
Q2: Which access control model maps permissions to job roles?
- Discretionary control, where each data owner sets own rules
- Mandatory control, enforced using centrally assigned security labels
- Role-based control, mapping permissions to each user's function
- Attribute-based control, applying dynamic real-time context policies
Answer: C: Role-based control maps permissions to defined roles
Q3: What is symmetric encryption's main limitation in IoT?
- Requires a certificate authority to distribute every session key
- Cannot encrypt any payload larger than a single network packet
- Adds too much processing latency for real-time sensor streams
- Securely sharing one secret key across many devices is hard
Answer: D: Securely sharing one key across many devices is hard
Q4: What does "defense in depth" mean for an IoT system?
- A single firewall rule blocks all inbound external network traffic
- Multiple layered controls each catch failures the others miss
- Hardware security modules encrypt all data stored at rest
- Role-based access control is applied to every API endpoint
Answer: B: Multiple layered controls each catch what others miss
Q1: What distinguishes a canary release from a full rollout?
- Canary releases skip regression tests to accelerate deployment speed
- Canary builds are deployed only to internal QA staging environments
- New code is exposed to a small subset of users first
- Canary versions disable telemetry to reduce overhead at launch
Answer: C: New code exposed to a small user subset first
Q2: What is the primary goal of a CI/CD pipeline?
- Automate build, test, and deploy steps for faster safe delivery
- Replace manual code reviews with static analysis gate checks
- Generate compliance reports for required IEC 62443 security audits
- Synchronize firmware versions across all devices in a fleet
Answer: A: Automate build, test, deploy for faster safe delivery
Q3: What happens during a staged release rollback?
- All devices simultaneously revert to the prior firmware version
- Traffic gradually shifts back to the last known stable release
- A hotfix is compiled and pushed directly to affected devices
- The release pipeline is paused and all pending builds discarded
Answer: B: Traffic gradually shifts back to the stable release
Q5: Which phase involves limited external users before full GA?
- Unit testing, isolating individual functions inside a local build
- Alpha testing, using only internal developers in a lab setting
- Beta testing, engaging real external users before general release
- Regression testing, re-running prior suites after each new change
Answer: C: Beta testing with real external users before GA
Q1: What is the key benefit of AI-driven predictive maintenance?
- Replacing all human operators with fully autonomous robotic systems
- Generating compliance reports required by industrial safety regulations
- Reducing firmware size by removing unused sensor driver modules
- Detecting equipment faults before failure to prevent unplanned downtime
Answer: D: Detect faults before failure, preventing downtime
Q2: What distinguishes edge AI from cloud AI in IoT systems?
- Edge AI requires a live internet connection for model inference
- Edge AI runs inference on device, reducing latency and bandwidth
- Edge AI offloads all computation to a collocated server rack
- Edge AI uses larger and more complex models than cloud allows
Answer: B: Edge AI infers on-device, cutting latency and bandwidth
Q4: What role does a digital twin play in AI-assisted engineering?
- A virtual simulation environment for safe model training and testing
- Replacing physical sensors with software-generated synthetic data streams
- Storing historical sensor telemetry as training datasets in cloud
- Deploying trained AI models directly onto production edge hardware
Answer: A: Virtual simulation for safe model training and testing
Q5: What is transfer learning's main advantage in Industry 4.0 AI?
- It eliminates the need for any domain-specific labeled training data
- It reduces inference latency by sharing weights across IoT gateways
- It allows models to run on hardware without any accelerator chip
- It reuses pretrained weights, reducing required data and compute costs
Answer: D: Reuse pretrained weights, cutting data and compute needs
Lab 5: Sprint & Documentation
Close out the project, finalise your backlog, and leave the codebase production-ready.
Due: April 27
Task 1: Update All Tickets
- Open your project backlog board
- Move every completed item to Done
- Any unfinished ticket → move to Future Work
- Screenshot your final board and include it in your submission
Task 2: Update Documentation
- Update
README.md: project overview, architecture, how to run, limitations - Add figures, brief tutorial of embedded and frontend components
- Confirm all API endpoints or interfaces are documented
- Add a Lessons Learned section (3–5 bullet points)
Task 3: Remove Obsolete Code
- Files & folders: delete
_old,_backup, temp, and unused scripts - Dead branches: delete merged branches; keep only
main - Dependencies: remove unused packages from
requirements.txt - Stale config: strip dev credentials, local URLs, debug flags
- Re-run tests after cleanup to confirm nothing broke
Task 4: Tag a Release & Demo
- Create a GitHub release tagged
v2.0 - Confirm CI/CD pipeline passes on the tag
- Submit: GitHub release link
Homework 5: IoT Light Sensor: Garage Adaptation
Reflect on how the design would change if you built the same IoT light sensor app for an indoor garage instead of a smart office building.
Due: April 27
Question 1
What is the primary difference in the sensing environment between a smart office building and an indoor garage?
Question 2
How would your sensor thresholds and trigger logic change for a garage?
Question 3
What new safety requirements would the garage context introduce that the office version did not need?
Question 4
Would you keep the same edge-cloud architecture, or change it? Why?
Question 5
Name one legal or compliance constraint specific to a garage and explain how it would affect your design.
Question 6
How many weekly sprints would you recommend for the garage adaptation project, and what would each sprint deliver?
Question 7
What skill levels and roles would you require for the garage IoT project team (embedded, backend, database, etc.)?
Question 8
How would you plan testing given that the garage is in a different location (same city) than the R&D office?
Question 9
What hardware would you need for development and testing of the garage IoT light sensor app?
Final Exam: Friday, May 1 | 12 - 1 PM | CTC 113
- 20 questions on paper (1–2 per module)
- 18 multiple-choice
- 2 descriptive (e.g. design architecture or recommend process)
- Closed book + 1 note sheet
- No Module 14–15 on exam: focus on Modules 1–13
- Architecture: identify components, layers, trade-offs
- Process question: state constraints, then justify the approach
- Partial credit for clear reasoning
- Diagrams and bullet notes welcome
- Homework & Lab 1–5
- Midterm, IoT Light Sensor Project
- Project Backlog
- Module 1–13 slides
- ☐ M1 Intro / SE
- ☐ M2 Requirements
- ☐ M3 Team Structure
- ☐ M4 Dev Process
- ☐ M5 Architecture
- ☐ M6 Legal
- ☐ M7 Testing / V&V
- ☐ M10 Sustainability
- ☐ M11 Cyber Security
- ☐ M12 Release Process
- ☐ M13 AI Integration
Please ask anytime sberhe@pacific.edu